前言
CUDA并行程序设计系列是本人在学习CUDA时整理的资料,内容大都来源于对《CUDA并行程序设计:GPU编程指南》、《GPU高性能编程CUDA实战》和CUDA Toolkit Documentation的整理。通过本系列整体介绍CUDA并行程序设计。内容包括GPU简介、CUDA简介、环境搭建、线程模型、内存、原子操作、同步、流和多GPU架构等。
本系列目录:
- 【CUDA并行程序设计系列(1)】GPU技术简介
- 【CUDA并行程序设计系列(2)】CUDA简介及CUDA初步编程
- 【CUDA并行程序设计系列(3)】CUDA线程模型
- 【CUDA并行程序设计系列(4)】CUDA内存
- 【CUDA并行程序设计系列(5)】CUDA原子操作与同步
- 【CUDA并行程序设计系列(6)】CUDA流与多GPU
- 关于CUDA的一些学习资料
CPU的发展
在早期,计算机的性能随着中处理器(CPU)的发展得到了很大的提升,在摩尔定律的驱使下,CPU的时钟频率从30年前的1MHz发展到现在的1GHz~4GHz。但是,靠提高CPU时钟频率来提升计算机性能在现在已经不是一个好的方法了,随着功耗的急剧升高和晶体管的大小已经接近极限,硬件厂商需要需求其它的方案。其中一个方案就是增加处理器的数量,现在所见到的大部分PC机都使用了多核处理器,像Intel的I3、I5、I7系列都是多核CPU。但是,受体积和功耗的现在,CPU的核心数量也不能增加的太多。可以说,近几年CPU并没有得到突破性的发展,连知名程序员Jeff Atwood上次升级PC也是2011年的事了。
GPU的发展
在CPU发展的同时,图形处理技术同样经历了巨大的变革,早期的GPU主要用于图形显示,以游戏居多,在那时几乎每一款新的大型游戏推出都会引发显卡更换热潮。图形处理器直接运行图形流水线功能,通过硬件加速渲染图形,使得应用程序能实现更强的视觉效果。
GPGPU
GPU的计算能力以及并行性吸引了很多研究人员对把GPU应用于图形之外的兴趣,后来就出现了GPU通用计算(GPGPU)。2007年NVIDIA率先倡导使用GPU加速计算性能。
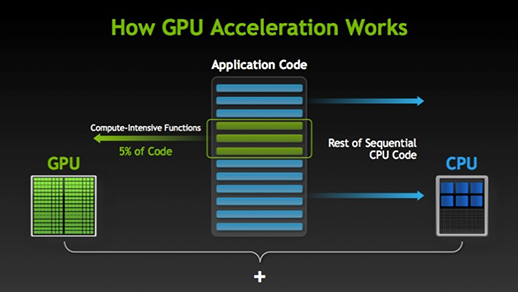
使用GPU加速,最主要的是让程序并行运行,这点和PC集群技术是一样的。一个程序的大部分串行代码依然在CPU上运行,而少部分可并行的(往往也是最耗时间的,如for循环)代码在GPU上运行,如下图。在这种方式下,程序的运行速度得到了很大的提升。
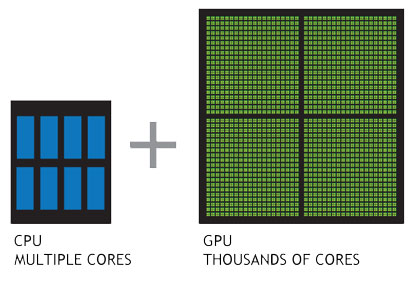
现代的GPU使用了类似于集群技术,一个GPU内有许多流处理器簇(Streaming Multiprocessor, SM),它们类似CPU的核。一个GPU可能有成千上万个核,因此就可以使程序在GPU上并行运行。对比CPU和GPU如下图。
下面是NVIDIA官方给出的对比不同CPU和GPU在浮点型运算的性能:
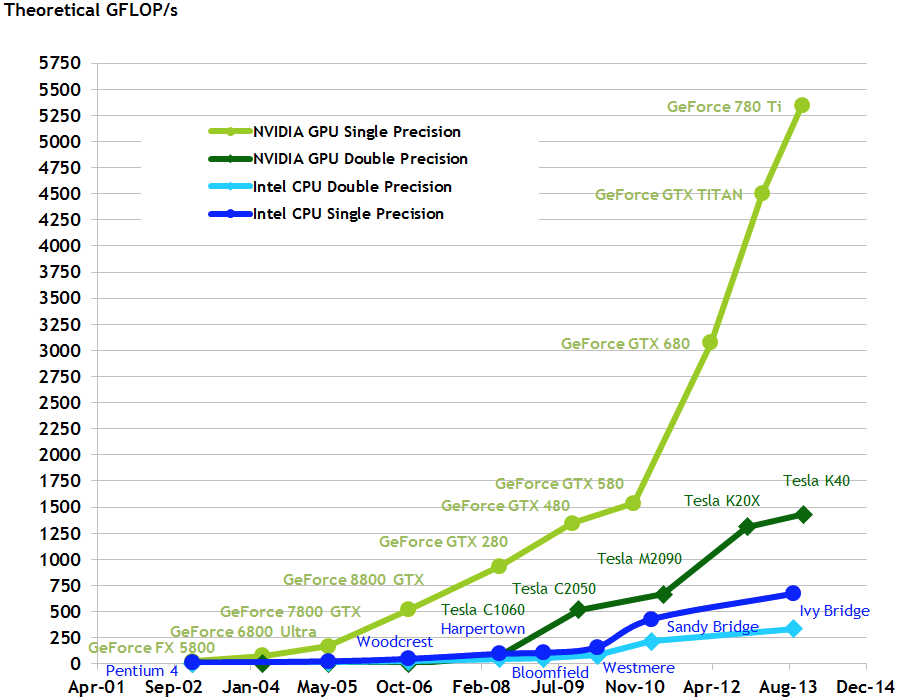
如果上面的图表还不能明白GPU到底能加速到多块,那么下面这个视频能更直观地说明GPU加速的效果。(看不到视频的话直接转至 优酷链接 | Youtube)
参考文献
- 《CUDA并行程序设计:GPU编程指南》
- 《GPU高性能编程CUDA实战》
- http://blog.codinghorror.com/building-a-pc-part-viii-iterating/
- WHAT IS GPU ACCELERATED COMPUTING?
- CUDA C Programming Guide