
Title: Multimodality Helps Unimodality: Cross-Modal Few-Shot Learning with Multimodal Models
Paper: https://arxiv.org/pdf/2301.06267.pdf
导读
本文提出了一种简单而有效的基于多模态预训练模型 CLIP 的小样本微调算法——cross-modal adaptation,通过将跨模态信息(例如文字标签)作为训练样本加入交叉熵损失(Cross-Entropy Loss, CE Loss)进行微调,即可实现用一个简单的线性分类器在十一个图像识别训练集中取得SOTA效果。
不仅如此,所提方法的训练速度和性能均大幅优于先前基于prompting、adapter或ensemble的算法,例如CoOp、CoCoOp、Tip-Adapter和WiSE-FT等。此外,实验表明了我们的算法在域外分布(Out of Distribution, OOD)测试集上,例如ImageNet-V2和Sketch上也具备良好泛化能力,同时可以适应多种输入模态,包括但不仅限于音频。
最后,我们希望这项工作能为未来的多模态学习提供有益的参考价值,也可以取代传统的linear-probing来作为未来预训练模型的衡量基准。
linear-probing: 即把骨干网络部分的权重冻结,在模型最后添加一层线性分类器(一般使用全连接层)完成分类,只训练
Linear Classifier的参数;其常用在自监督领域,将预训练模型的表征层的特征固定,只通过监督数据去训练分类器;
finetune: 即大家正常理解的微调;
因此,finetune会更细预训练模型的特征提取器,而另一个的优势则是不会破坏预训练的特征提取器。
动机
小样本学习(Few-shot learning)是机器学习领域的一个重要方向,然而基于深度学习的识别算法仍然无法达到人类甚至婴儿在此类任务上的性能。我们认为这一现象主要是因为现阶段的小样本学习任务往往只考虑单一模态的训练样本,例如只用少量图像来训练一个分类器。然而,大量神经科学的研究1、2指出,人脑在学习新概念的时候会利用跨模态的信息,比如语言或者音频。
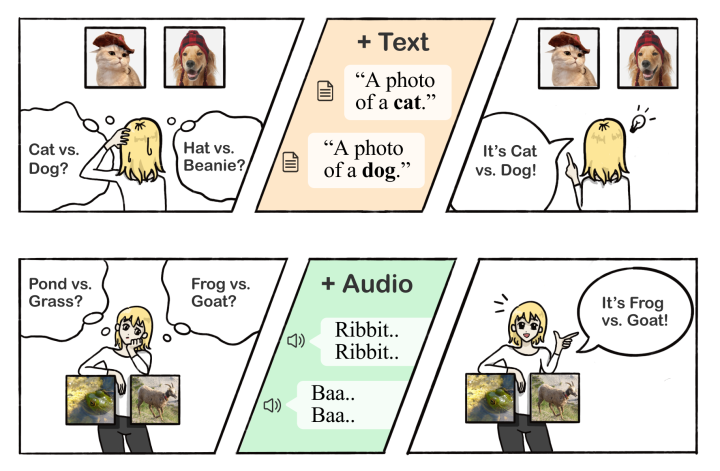
这一跨模态学习的现象在当前以CLIP为代表的预训练模型上尤为突出。CLIP在各大图像识别任务上都取得了非常先进的zero-shot识别性能, 即是仅用文本的信息(标签名)就可以取得非常优异的分类结果。此类模型利用了对比学习(contrastive learning)使得不同模态的样本能在同一个空间中对齐。
基于此,我们提出了一个简单的基于CLIP的小样本微调算法,即是将跨模态的信息(比如文本标签)作为额外的训练样本,同图像样本一起用来优化softmax,即cross-entropy loss。
方法
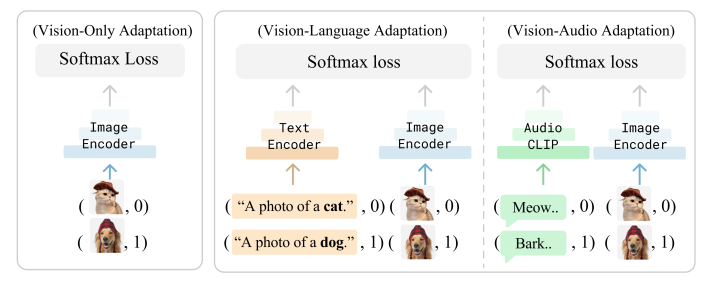
我们发现目前最流行的基于CLIP的小样本学习算法,例如CoOp, Tip-Adapter, WiSE-FT 等,均只用单一的图像样本来训练一个分类器:
L u n i − m o d a l = ∑ i H ( y i , ϕ ( x i ) ) \mathcal{L}_{uni-modal} = \sum_i \mathcal{H}(y_i, \phi(x_i)) Luni−modal=i∑H(yi,ϕ(xi))
其中 x i x_i xi为图像样本, y i y_i yi为图像标签, ϕ \phi ϕ为特征提取器(feature extractor)。 H \mathcal{H} H则是常用的基于一个线性分类器 W = [ w 1 , ⋯ , w Y ] W = [w_1, \cdots, w_Y] W=[w1,⋯,wY]的交叉熵损失函数:
H ( y , f ) = − log ( p ( y ∣ f ) ) = − log ( e w y ⋅ f ∑ y ′ e w y ′ ⋅ f ) \mathcal{H}(y, f) = -\log \Big( p(y | f) \Big) = - \log \Big( \frac{e^{w_{y} \cdot f}}{\sum_{y'} e^{w_{y'} \cdot f}} \Big) H(y,f)=−log(p(y∣f))=−log(∑y′ewy′⋅fewy⋅f)
因为我们假设CLIP能够将不同模态的样本映射到同一特征空间(具备和分类器特征 w y w_y wy同样的长度 N N N):
w y , ϕ m ( ⋅ ) ∈ R N w_y, \phi_m(\cdot) \in R^N wy,ϕm(⋅)∈RN
因此,我们提出一个简单的使用跨模态的信息的方法(Cross-modal adaptation):例如每个class自带的文本标签,我们将其视作为额外的“one-shot”训练样本,并加入损失函数。假设我们有 M M M种模态(例如 M M M= (图像,文本)):
( x i , y i ) → ( x i , y i , m i ) , x i ∈ X m i , m i ∈ M (x_i,y_i) \rightarrow (x_i,y_i,m_i), \quad x_i \in X_{m_i}, \quad m_i \in M (xi,yi)→(xi,yi,mi),xi∈Xmi,mi∈M
那么我们的方法(cross-modal adaptation)就会使用如下的损失函数:
L c r o s s − m o d a l = ∑ i H ( y i , ϕ m i ( x i ) ) \mathcal{L}_{cross-modal} = \sum_i \mathcal{H}(y_i, \phi_{m_i}(x_i)) Lcross−modal=i∑H(yi,ϕmi(xi))
在测试的时候,因为我们对不同模态采用了同一个线性分类器,对于不同模态的样本,只需要分别经过各自模态的特征提取器,即可做出分类。例如 x x x属于模态 m m m, 那么其分类结果 y ^ {\hat y} y^就是:
y ^ = a r g m a x y ′ w y ′ ⋅ ϕ m ( x ) {\hat y} = argmax_{y'} w_{y'} \cdot \phi_m(x) y^=argmaxy′wy′⋅ϕm(x)
尽管我们可以用同一个分类器完成对不同模态的分类,在这篇论文的实验中我们主要关注我们方法在图像识别这一单一模态任务上带来的提升。
效果
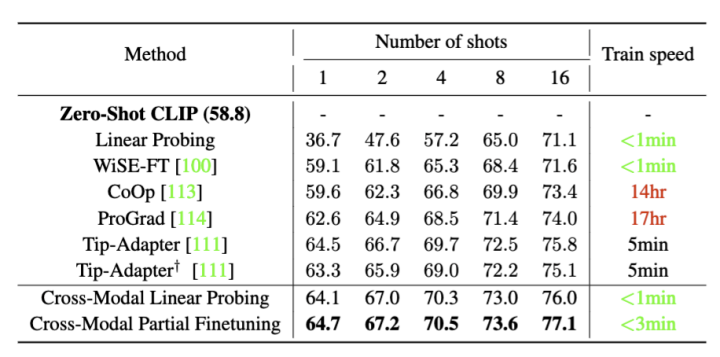
对于图像识别而言,几乎所有的数据集例如ImageNet等都会附带每个class的文本标签,因此我们的方法可以得益于这类数据集自带的“免费”跨模态信息来进行训练。在训练过程中,我们只需要微调一个线性分类器Cross-modal Linear Probing,既可以取得SOTA的效果。同时,我们也可以部分微调CLIP的图像特征提取器来取得更好的性能,例如神经网络的最后一层Cross-modal Partial Finetuning:
需要注意的是,我们所比较的方法,例如CoOp和Tip-adapter等均利用了同样的跨模态文本标签信息。在这一基础上,我们发现我们提出的损失函数仍然可以提升以往方法的性能:
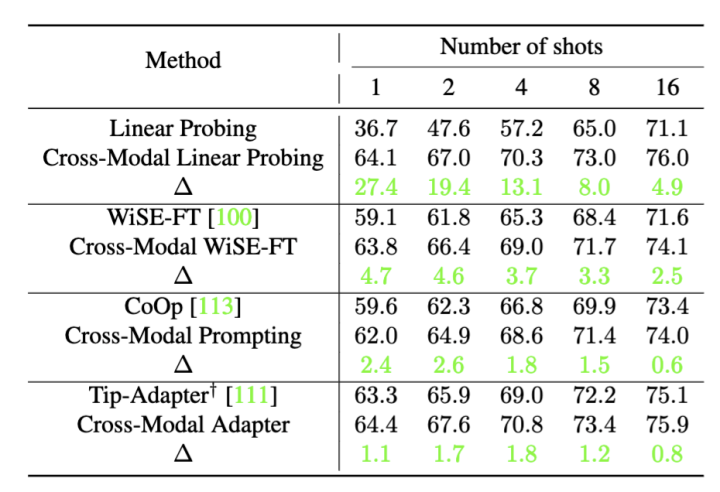
我们的方法仅需要微调很少的参数,同时,不同于prompting,我们因为能够提前提取最后一层网络特征,可以将训练成本和速度压缩好几倍:
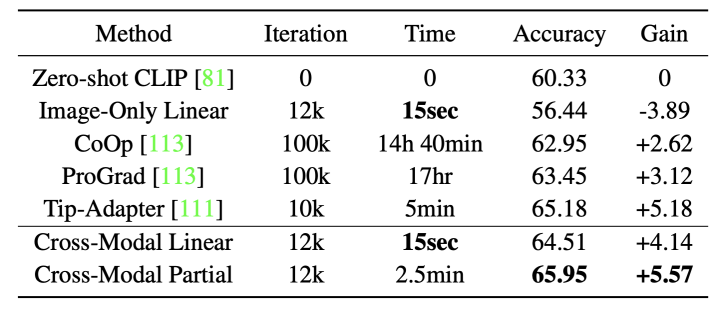
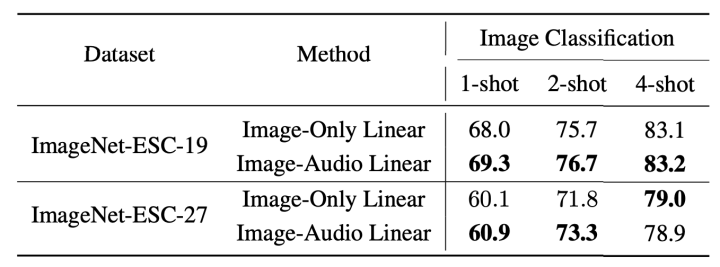
为了证明我们的方法能扩展到更多模态,我们利用AudioCLIP提出了第一个小样本视觉音频识别任务ImageNet-ESC,并证明了我们的方法也能够利用音频来提升图像识别的性能(或者用图像来提升音频识别的性能):
理论分析
我们将cross-modal adaptation方法和现阶段流行的classifier ensembling方法(WiSE-FT)进行了对比。WiSE-FT方法指出在微调CLIP之后,应当将微调后的网络权重和原始的CLIP网络权重做一个加权平均,例如用0.5来取一个平均权重。
在实践中,我们发现我们的方法要显著优于WiSE-FT。我们认为这个原因可以追溯到机器学习理论中的Representer Theorem。这一理论证明了对于机器学习分类器,最优的权重一定是所有训练样本的线性组合。对于cross-modal linear-probing方法来说,因为我们训练时使用了对于所有训练样本的cross-entropy loss,我们的方法能自动找到每一个样本(无论模态)对应的权重。
w y = ∑ i α i y ϕ m i ( x i ) = ∑ m ∈ M w y m , where w y m = ∑ { i : m i = m } α i y ϕ m ( x i ) w_y = \sum_i \alpha_{iy} \phi_{m_i}(x_i) = \sum_{m \in M} w_y^m , \quad \text{where} \quad w_y^m = \sum_{\{i: m_i = m\}} \alpha_{iy} \phi_m(x_i) wy=i∑αiyϕmi(xi)=m∈M∑wym,wherewym={ i:mi=m}∑αiyϕm(xi)
而WiSE-FT在linear-probing训练时仅能找到对于视觉特征样本所对应的权重,仅在训练之后将其他模态的特征样本权重与之相加。这一分析解释了为何我们的方法要优于WiSE-FT。
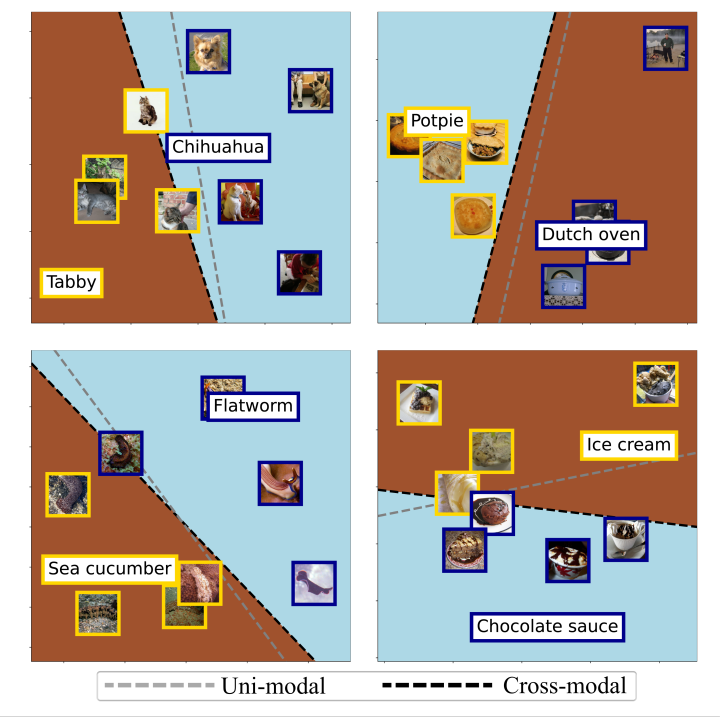
在我们使用PCA的方法来在二维空间观测我们的分类器时,我们发现我们的方法通过引入跨模态文本标签信息可以有效改变分类器的权重:
总结
Cross-modal adaptation先进的实验结果证明了CLIP这一类的多模态模型的最优微调范式一定要利用跨模态的信息,这一点和单模态微调(例如prompting和adapter之于大语言模型)有显著的区别。我们认为文本模态对于小样本泛化任务有非常明显的帮助,因此后续工作应当着重研究如何利用更多的文本信息来提升图像分类的效果。
在论文中我们还展示了我们方法在OOD测试集上,例如ImageNetV2和ImageNet-Sketch上的优越泛化性能。基于此,我们希望跨模态微调cross-modal adaptation能够取代单模态微调,成为未来预训练模型的性能衡量基准。
代码
本文方法实现起来简单易用,可参考以下pseudocode:
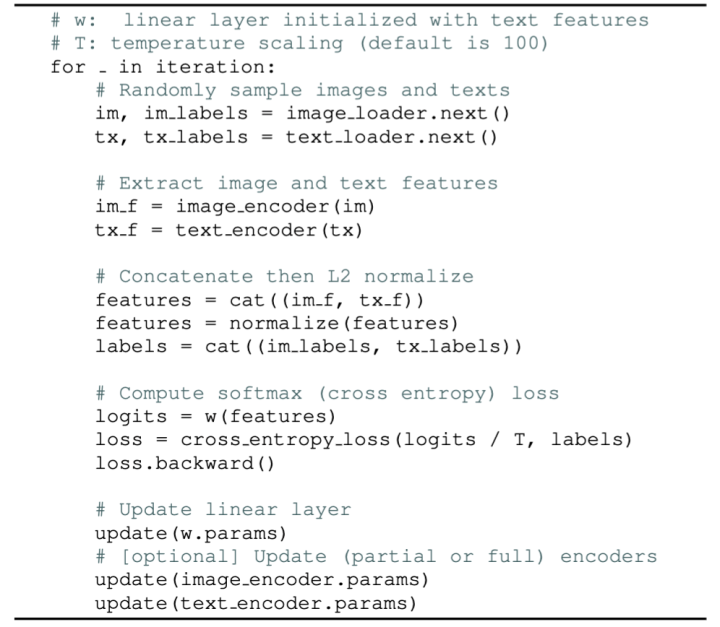
代码链接:Github code,欢迎多多Star支持以下!
写在最后
如果您也对人工智能和计算机视觉全栈领域感兴趣,强烈推荐您关注有料、有趣、有爱的公众号『CVHub』,每日为大家带来精品原创、多领域、有深度的前沿科技论文解读及工业成熟解决方案!欢迎添加小编微信号:cv_huber,一起探讨更多有趣的话题!