点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:王利民 |(已授权转载)编辑:CVer
https://zhuanlan.zhihu.com/p/616384758
本文介绍我们在2D、3D光流领域的新工作。针对Camera-LiDAR多模态设定,我们提出一种多阶段的双向融合的框架,并基于RAFT和PWC两种架构构建了CamLiRAFT和CamLiPWC这两个模型。我们在FlyingThings3D,KITTI等多个数据集上取得了SOTA性能。其中,我们性能最好的模型CamLiRAFT在KITTI排行榜中误差仅为4.26%,在所有提交中排行第一。此外,我们的方法还能够处理non-rigid运动,并且在LiDAR-only的单模态设定下也大幅超过了之前的方法。
我们这个工作的会议版本(CamLiFlow)之前已被CVPR 2022接收,且被选为 Oral Presentation。最近我们对其进行扩展,扩展到新的模型(CamLiRAFT),达到了更强的性能。论文和代码已经开源:
会议版本 (CVPR 2022 Oral):https://arxiv.org/abs/2111.10502
扩展版本 (arXiv 2023):https://arxiv.org/abs/2303.12017
代码地址:https://github.com/MCG-NJU/CamLiFlow
1 引言
本文关注Camera和LiDAR的多模态融合问题,具体的任务是2D光流和3D光流(3D光流又称为场景流,Scene Flow)的联合估计。
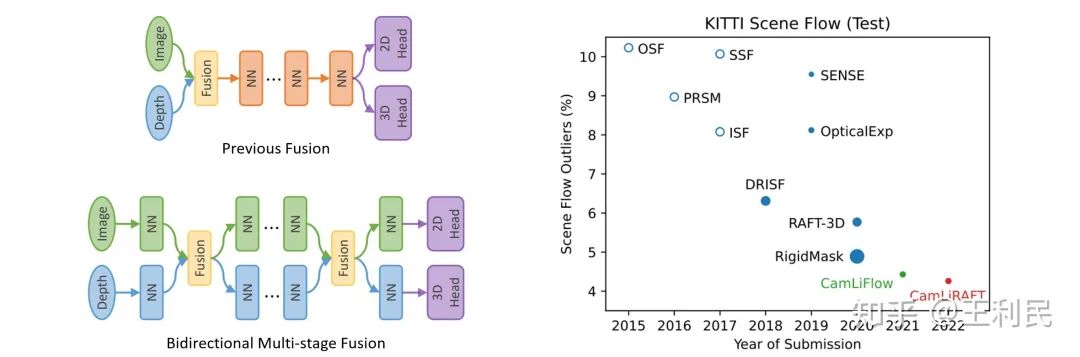
之前的方法往往使用early-fusion或者late-fusion这种单阶段的融合设计。然而,单阶段融合不能充分利用每个模态的特征,也不能充分做到模态间的互补。因此,我们提出一种多阶段的双向融合的框架。在每个阶段内,两种模态独立学习;在阶段末尾,我们提出Bi-CLFM算子将两个分支双向连接起来,进行互补信息的传递。整个网络可以使用多任务损失进行端到端的训练。此外,我们的融合方案具有通用性,可以用于PWC-Net、RAFT等多种架构,也可以拓展到其他任务、其他模型(只要是图像和点云的融合就可以)。
在对图像和点云进行融合时,可能会遇到三个挑战,我们一一进行了解决。首先是针对图像特征和点特征的数据结构不匹配的问题,我们提出了一个可学习的双向融合模块Bi-CLFM,它可以融合2D到3D、3D到2D两个方向的特征。其次是两个分支性能不匹配的问题,因为采用现有的光流方法(比如RAFT)构建2D分支很容易,但想让3D分支的结构和性能与2D分支相当却较为困难。因此我们重新构建了一个和RAFT结构一样的3D分支,并设计了基于point的correlation pyramid,它同时能够捕捉small motion和large motion。第三是两个分支的梯度尺寸不匹配的问题,如果直接进行融合则会导致训练不稳定,还会出现一种模态主导训练的情况。因此我们设置了将来自另一个模态的梯度截断,让每个模态专注于优化自身。
我们在RAFT和PWC两种架构上实现了提出的融合方法,并取名CamLiRAFT和CamLiPWC。在FlyingThings3D数据集上,CamLiPWC和CamLiRAFT显著优于之前的所有方法;相比于RAFT-3D,我们的EPE3D误差减少了48%,并且只用1/5的参数量。在KITTI排行榜中,之前的SOTA方法都重度依赖刚体假设,而我们的CamLiRAFT在没有利用任何刚体假设的情况下与之前的SOTA方法RigidMask不相上下(SF-all:4.97% vs. 4.89%);在用上刚体假设之后,我们的方法进一步刷到了 4.26%,在所有提交中排行第一。我们还在Sintel数据集上进行了实验:在没有针对Sintel进行finetune的情况下,CamLiRAFT在Sintel的training set的final pass上取得了2.38 AEPE的误差,相比于RAFT和RAFT-3D分别降低了12%和18%,这证明了我们方法不仅拥有良好的泛化性,而且可以处理non-rigid运动。此外,我们的方法CamLiPWC-L和CamLiRAFT-L在LiDAR-only的单模态设定下也大幅超过了之前的方法,在未来的研究中可以作为一个强大的baseline。
2 方法
2.1 Bidirectional Camera-LiDAR Fusion Module(Bi-CLFM)
Bi-CLFM模块在2D到3D、3D到2D两个方向上融合密集图像特征和稀疏点特征。它的输入为图像特征、点云特征,还有点云的位置坐标;输出则是融合后的图像特征和点云特征。我们这里输出和输入的特征shape是不变的,因此可以很容易地作为一个插件来插入到不同的架构中。
在进行特征融合之前,我们需要先将图像特征和点特征对齐。也就是说,需要对图像特征进行采样,让它变得稀疏;对点特征进行插值,让它变得稠密。
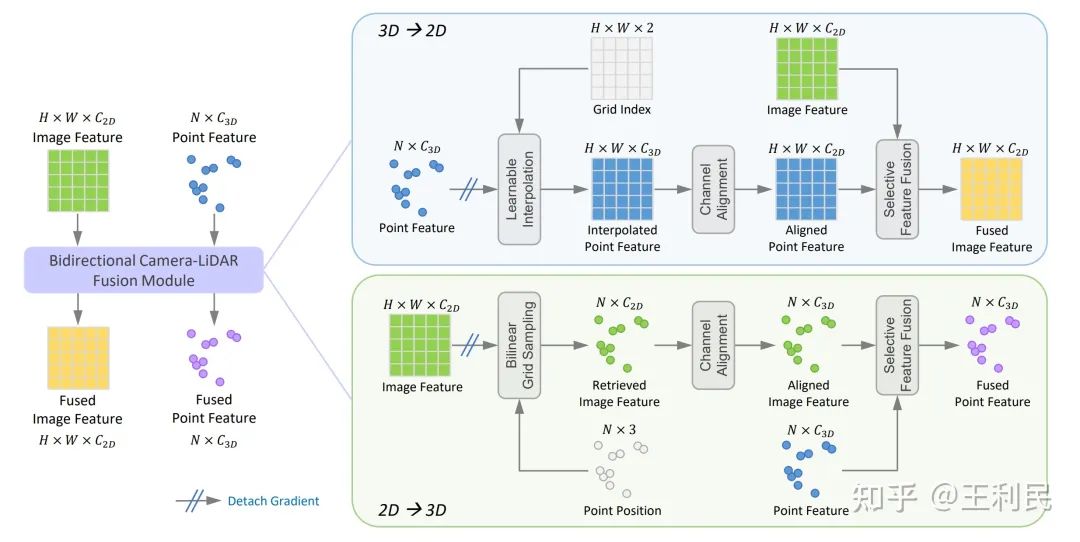
2D->3D: 对于2D到3D方向的对齐,我们首先将点投影到图像平面来sample相应的2D特征,其中,非整数坐标的情况使用双线性插值来处理。接着使用一个1×1卷积将sample得到的特征的通道维度与输入点特征dim对齐。
3D->2D: 3D到2D方向的对齐也是类似,我们将点投影到图像平面,利用一个新的可学习的插值模块(下面有讲)从稀疏点特征中得到密集的特征图。接着也使用一个1×1卷积将插值点特征的通道维度与输入图像特征dim对齐。
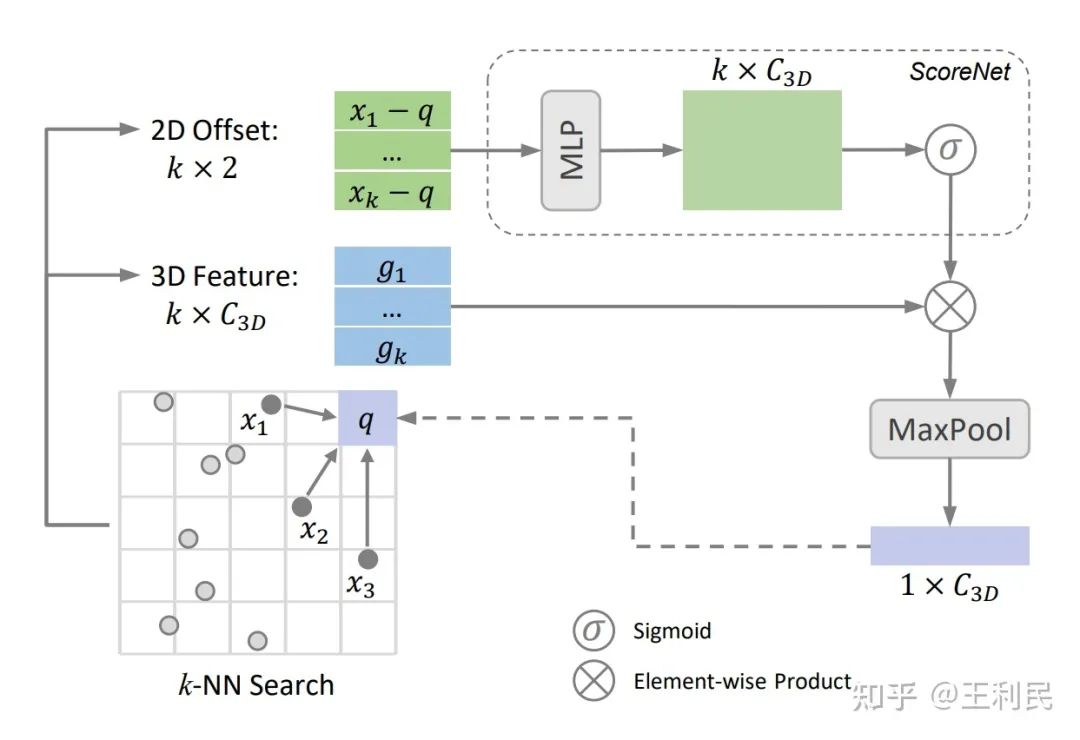
可学习插值: 对于密集特征图的每一个像素,我们在图像平面中寻找k个离它最近的投影后的点。接着,我们用一个ScoreNet根据坐标偏移量为相邻特征生成权重,ScoreNet会给每一个特征赋予一个(0,1)区间的分数。最后再根据分数赋予相邻特征权重,并使用max或sum这类对称运算进行聚合。
自适应特征融合: 对齐了特征之后,我们需要对他们进行融合。最简单的方法就是concat或者add,不过它们不够adaptive。这里我们使用了基于SKNet的方法进行adaptive的特征融合,它能够自适应地挑选出需要融合的channel。
梯度截断: 在进行多模态融合时,可能会遇到两个模态梯度尺寸不匹配的问题。如果不进行处理,可能会导致一种模态主导训练。我们对两个模态的梯度进行分析,发现2D的梯度比3D大了约40倍!因此,我们在Bi-CLFM中截断了来自另一个模态的梯度,使模态间不会受到相互影响。
2.2 PWC pipeline(CamLiPWC)
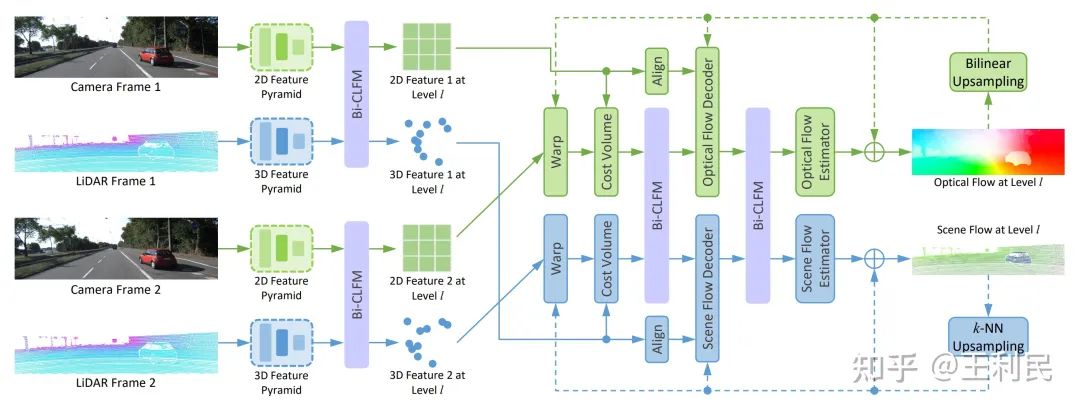
CamLiPWC的两个分支都基于PWC架构,也就是我们的会议版本。其2D分支基于IRR-PWC,3D基于PointPWC,并且相比官方做了一些改动和实现优化。接着,我们将feature pyramid、cost volume和flow decoder三个位置的特征进行双向特征融合。
2.3 RAFT pipeline(CamLiRAFT)
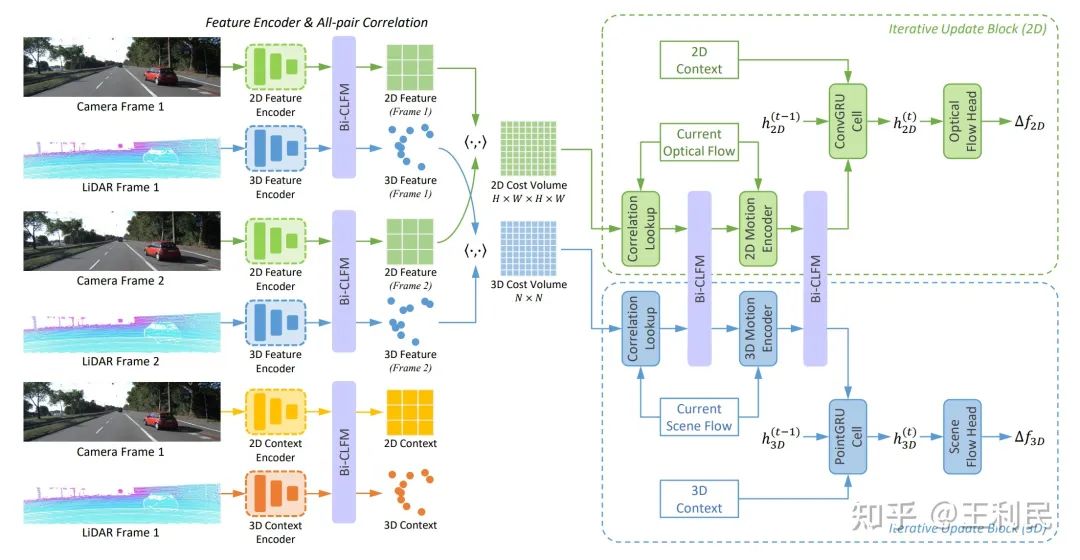
CamLiRAFT使用RAFT(一点没改)作为2D分支。它的3D分支是我们自己设计的,因为现有的方法要么性能很差,要么速度很慢,并且架构还和RAFT不对称(具体可以看文章中 Section 4.2 的讨论)。接着,我们在feature encoder、context encoder、correlation lookup和motion encoder四个位置进行双向特征融合。
3 实验结果
我们在FlyingThing3D,KITTI,和Sintel数据集上评估了提出的方法。
FlyingThings3D
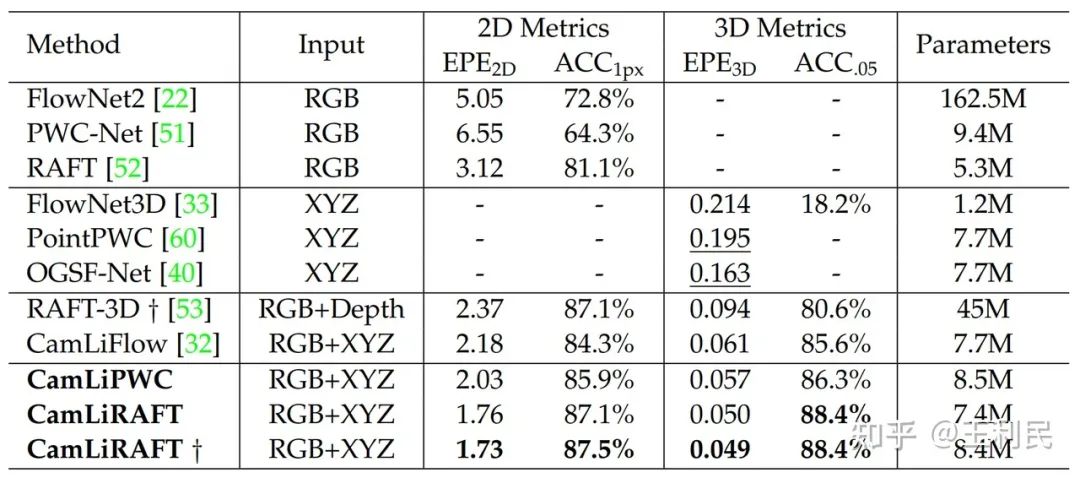
在FlyingThing3D数据集中,我们提出的CamLiPWC和CamLiRAFT优于之前的所有方法,实现了更轻量和更高性能的统一,在各种指标上都达到了新高度。与RAFT-3D相比,我们的方法只需要将sparse点云作为输入,无需dense的深度图,还可以处理刚性和非刚性运动,这证明了多阶段双向融合的有效性。

从可视化结果来看,单模态方法由于纹理信息或几何信息的缺失,性能会受到一定影响,而我们提出的方法无论是对重复结构的物体,还是包含重叠物体的场景都能够很好的处理。
KITTI
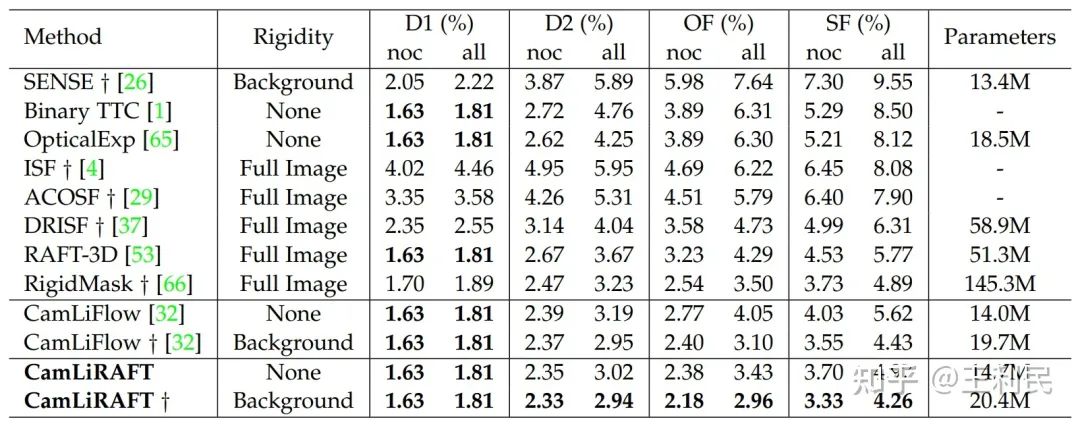
我们在KITTI数据集上测试了CamLiRAFT模型。要知道KITTI这个数据集里面几乎都是刚体,并且之前的SOTA方法都重度依赖刚体假设。我们的CamLiRAFT在没有利用刚体假设的情况下,就与之前的SOTA方法RigidMask不相上下(SF-all: 4.97% vs 4.89%)。在使用刚性假设对背景进行refine之后,我们发现CamLiRAFT的误差仅有4.26%,大幅超过所有方法。
Sintel
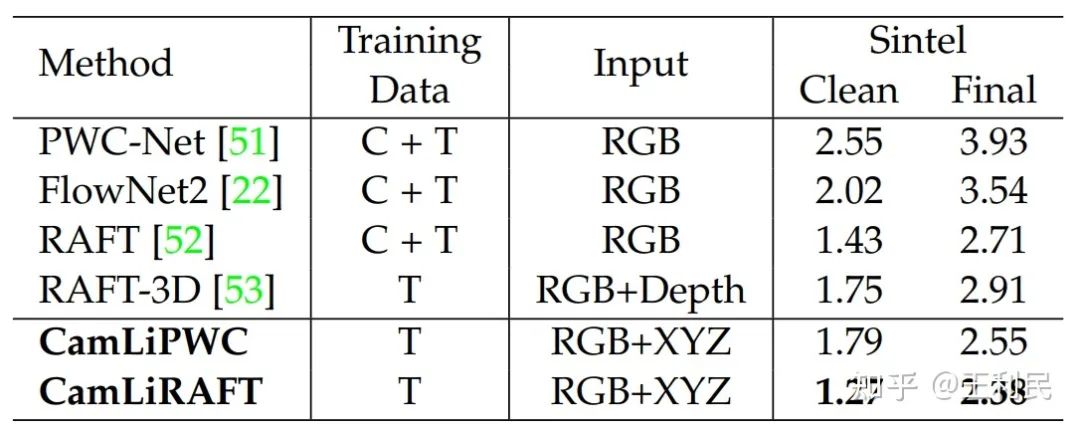
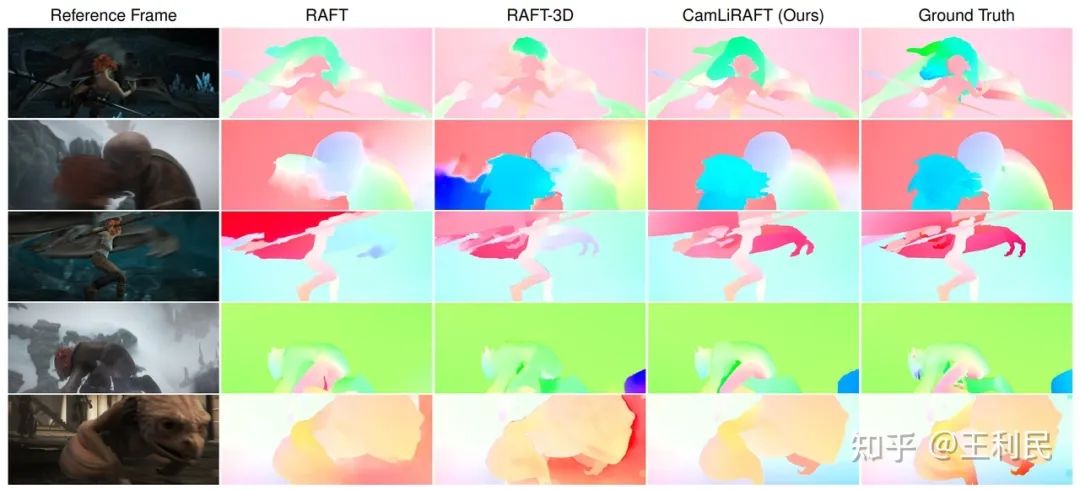
我们还在MPI Sintel数据集上进行测试,该数据集主要非刚性运动组成。因为Sintel只给training set提供了depth,我们就测试了模型的泛化性:只在合成数据上训,然后直接在Sintel training set上验证。CamLiRAFT在clean和final上的误差分别达到了1.27和2.38的新纪录,比RAFT降低了11.2%和12.2%。相反,RAFT-3D相比于RAFT是倒退的,因为它把刚体假设内嵌到模型里了,导致它不适用非刚性的场景。这证明了我们方法不仅拥有良好的泛化性,而且可以处理non-rigid运动。
4 结论
我们提出了一种多阶段的双向融合pipeline,它能够利用Camera和LiDAR之间的互补性来进行特征融合。还引入了Bi-CLFM模块,它可以在2D到3D、3D到2D两个方向进行特征对齐和融合,并利用其构建了CamLiPWC和CamLiRAFT。通过实验,我们证明了提出的pipeline具有通用性,在更轻量的同时,也在多个数据集上达到了SOTA性能。希望这个结果可以让大家对双向融合范式有更多的关注。
最新CVPP 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()