提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
本文参考:
1.Group Normalization算法笔记
2.Group Normalization详解
原论文:Group Normalization
一、 Group Normalization
Group Normalization(GN)是针对Batch Normalization(BN)在batch size较小时错误率较高而提出的改进算法,因为BN层的计算结果依赖当前batch的数据,当batch size较小时(比如2、4这样),该batch数据的均值和方差的代表性较差,因此对最后的结果影响也较大。
如下图所示:
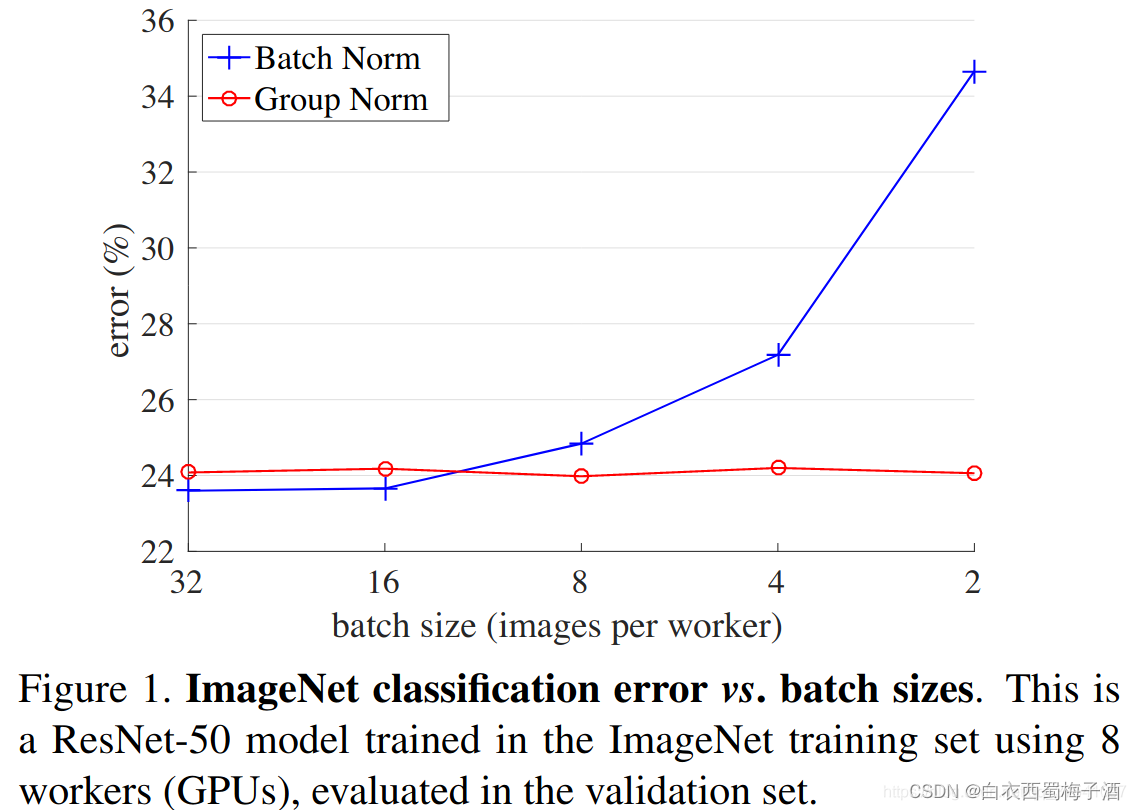
虽然在一般的分类算法中,我们一般会将batchsize设置的较大,但是在目标检测、分割以及视频相关的算法中,由于输入图像较大、维度多样以及算法本身原因等,batch size一般都设置比较小,所以GN对于这种类型算法的改进应该比较明显。
二、Group Normalization思想
GN算法的思想非常简单,就是要使归一化操作的计算不依赖batch size的大小。于是作者就考虑将channel分成多个group,计算每一个Group的Mean和variance。因此,GN算法不依赖于Batch Size的大小,在不同Batch size的情况下具有稳定的效果。
下图是各种Normalization 的算法:

我们可以发现Layer Normalization 和 Instance Normalization都可以看作是Group Normalization的一种特殊化。
具体的公式与之前的BN,LN基本相似。
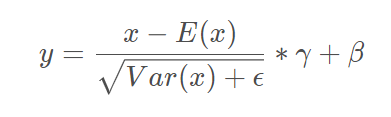
下面给出在Pytorch中的实现方式:
import time
import cv2
import tensorflow as tf
# def test_time(func):
# time1=time.clock()
# func()
# time2=time.clock()
# print(time2-time1)
import torch
import torch.nn as nn
from torch import Tensor
def group_norm(x: Tensor,
num_groups: int,
num_channels: int,
eps: float = 1e-5,
gamma: float = 1.0,
beta: float = 0.):
assert divmod(num_channels, num_groups)[1] == 0
channels_per_group = num_channels // num_groups
new_tensor = []
for t in x.split(channels_per_group, dim=1):
var_mean = torch.var_mean(t, dim=[1, 2, 3], unbiased=False)
var = var_mean[0]
mean = var_mean[1]
t = (t - mean[:, None, None, None]) / torch.sqrt(var[:, None, None, None] + eps)
t = t * gamma + beta
new_tensor.append(t)
new_tensor = torch.cat(new_tensor, dim=1)
return new_tensor