提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
可参考:Batch Normalization原理与实战
提示:以下是本篇文章正文内容,下面案例可供参考
一、Why we need Batch Normalization
1.1 Internal covariate shift
概念:covariate shift:学习系统的输入分布发生变化。
在神经网络中,我们会面临如下问题:
1.在神经网络中,由于我们大多使用MBGD(Mini Batch Gradient Descent),使得我们需要对模型超参数进行细致的调整,特别是学习速率和初始参数值。不仅如此,由于神经网络中的每一层的输入都受到前一层的参数的影响,训练变得复杂起来——因此,网络参数的微小变化会随着网络的加深而放大。
这里也就是所谓的梯度消失的问题,如果网络结构过深,那么传入到前面的网络层的梯度就会非常小,也就让训练变得非常困难。
2.对于深度学习这种包含很多隐层的网络结构,在训练过程中,因为各层参数不断在变化,所以每个隐层都会面临covariate shift的问题,也就是所谓的Internal Covariate Shift。也就是如果每层的参数都在不断变化,那么会导致输入隐藏层的分布会不断在变化,也就是说,对于隐层而言,x的分布在一段时间内保持固定是有利的,这样就意味着隐层不需要重新学习如何去迎合x的分布的变化,也就变相的加快了训练的速度。
1.2 Former Research
在之前的研究表明,如果在图像处理中对输入图像进行白化(Whiten)操作的话那么神经网络会较快收敛。
于是作者就想到了在每一层的输入前都使用一次归一化操作。(简易的白化操作)
二、Batch Normalization
Batch Normalization操作使得每一层的输入都大致处于同一个分布,同时对于Sigmoid函数而言,它也将大部分的数据规范到了其中间区域,这样能够减少梯度消失和爆炸的问题。(可以使用较大的学习率)
但是只是简单的归一化也有问题,有时候,我们不希望所有的数据总是均值为0,方差为1。这可能会改变原来的网络层能表示的东西,比如说把sgmoid限制在了0附近的线性区域,这样就意味着激活函数更多的起着一个线性函数的表示,而多个线性函数的组合,就丧失了深度的意义。(难以增加神经网络的表达能力)
于是,作者又引入了两个可学习的参数,
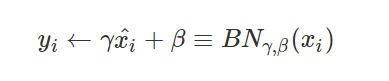
具体理解,我们可以考虑当γ正好等于某个值以使得归一化失效,那么也就意味着这个batch Normalization 不起作用。 而具体的参数,由神经网路自己去学习得到。
在测试时,我们会保存训练时的到的对应的均值和方差的估计量,也就是移动平均得到的值来作为每个测试样本BN的均值和方差。
具体的公式如下:
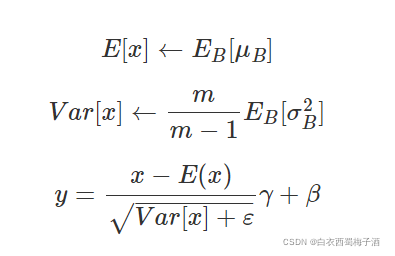
补充:
尽管每一个batch中的数据都是从总体样本中抽样得到,但不同mini-batch的均值与方差会有所不同,这就为网络的学习过程中增加了随机噪音,与Dropout通过关闭神经元给网络训练带来噪音类似,在一定程度上对模型起到了正则化的效果。
在CV中,BN代表了对于一个batch 中的每个channel进行相应的归一化,即求一个batch中channel1的均值,方差然后进行归一化。