提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、Why Layer Normalization
训练最新的深度神经网络在计算上是昂贵的,减少训练时间的一种方法是归一化神经元,最近引入的一种称为批归一化的技术使用训练案例的小批量上神经元的总输入分布来计算均值和方差,然后使用均值和方差对每个训练案例中该神经元的总输入进行归一化,这大大减少了前馈神经网络的训练时间。(Batch Normalization)
但是Batch Normalization的效果取决于小批量的大小,同时如何将其应用于递归神经网络尚不明显,这主要是因为在深度固定的前馈神经网络中,直接为每个隐藏层存储对应信息很容易,但是在递归神经网络中,递归神经元的输入随着序列长度而变化,因此对于RNN应用批归一化似乎需要针对不同时间步长进行不同统计。与批量归一化不同,层归一化不会在训练案例之间引入任何新的依存关系。
二、Layer Normalization
Batch Normalization和Layer Normalization的应用
对于CNNs图像
x=shape(batch_size, channels, height, weight),
则bn_mean=np.mean(x, axis=(0, 2, 3)), shape=(1, channels, 1, 1)对于RNNs序列
x=shape(batch_size, seq_len, hidden_size),
则ln_mean=np.mean(x, axis=2), shape=(batch_size, seq_len, 1)
一层输出的变化将趋向于导致对下一层求和的输入发生高度相关的变化,尤其是对于ReLU单元,其输出可以变化 l l l。这表明可以通过固定每一层内求和输入的均值和方差来减少“covariate shift”问题。
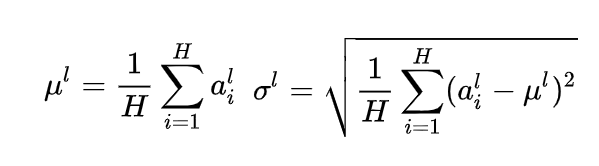
其中H表示层中隐藏单元的数量,和batch Normalization不同的是,这是在层归一化下,层中所有隐藏单元共享相同的归一化项 [公式] 和 [公式] ,但是不同的训练案例具有不同的归一化项。
或者如下:
从原理操作上来讲,BN针对的是同一个batch内的所有数据,而LN则是针对单个样本。另外,从特征维度来说,BN是对同一batch内的数据的同一纬度做归一化,因此有多少维度就有多少个均值和方差;而LN则是对单个样本的所有维度来做归一化,因此一个batch中就有batch_size个均值和方差。借用知乎上的一张图——batchNormalization与layerNormalization的区别——来说明:
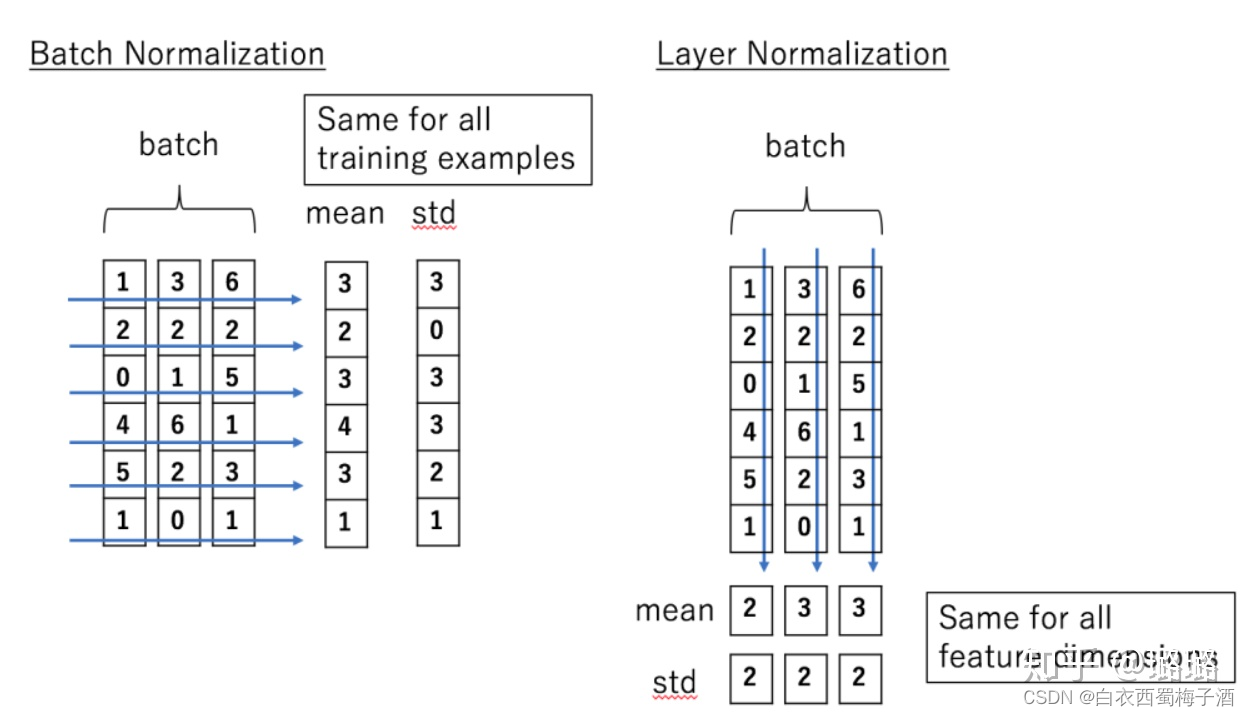
在标准RNN中,递归单元的总输入的平均幅度影响了每个时间步长增长或收缩,从而导致梯度爆炸或消失。在层归一化的RNN中,归一化项使将所有求和的输入重新缩放为层不变,这将导致更稳定的隐藏到隐藏的变化。