摘要
结构光和深度学习方法被广泛应用于人工视觉中,以获取真实场景的深度地图。本文提出了一种结合结构光和深度学习立体匹配的深度计算方法。为了解决立体匹配中无纹理区域的问题,采用一对具有丰富结构光信息的左右两侧图像,由无监督CNN网络获取粗深度图。粗深度图用于相位展开,是基于相位的结构光方法的瓶颈。然后,通过相位匹配得到精细、准确的深度图。与传统的结构光方法相比,该方法在遮挡和无纹理区域具有更好的性能。为了评价该方法的性能,建立了实验平台,并进行了多次实验。定量和定性实验表明,该方法能够产生高精度的深度,并在结构光系统中消除遮挡。
关键词:深度感知,深度学习,结构光,相位展开
1. Introduction
三维几何重构在机器人技术、人机交互、工业自动化、虚拟现实等领域有着广泛的应用。深度采集作为三维重建的核心内容,近年来得到了广泛的研究。计算摄影作为一种传感技术,可以提高真实场景的高维信息捕获性能。在现有的方法中,ToF[1]、结构化光[2]和立体匹配方法[3]得到了广泛的应用。
立体匹配是一种从多台相机[4]中提取深度的技术。通过从这些相机不同角度捕捉多个图像,通过匹配对之间的差异获得深度。一般来说,有两种匹配策略。一种称为局部对应法,另一种称为全局对应法[5]。前者通过block-matching[6]和基于梯度的优化[7]等子方法,倾向于在有限的窗口内或通过灰度、颜色等特征搜索对应的像素。该方法计算量小,效率高。然而,当处理大的、无纹理的区域和遮挡边界时,它会受到限制。全局方法包括置信度传播[8]、动态规划[9]和图割[10]等方法,将两幅图像的匹配作为一个优化问题。该方法利用非局部特征,与局部方法相比,取得了更好的性能。深度学习法是近年来一个重要的研究领域。与传统的全局匹配和局部匹配方法不同,深度学习立体匹配计算的是深度网络的视差。遗憾的是,作为一种被动的深度测量技术,无论是传统的方法还是先进的深度学习方法都无法获得准确的深度信息,尤其是对于无文本的场景。
结构光技术是一种高精度的深度测量方法,它能主动地将编码后的图像投射到场景中,并通过摄像机获取变形图像。为了计算pattern与变形图像之间的视差。近几十年来,人们提出了结构光方法,这些方法可以分为空间编码和时间编码。空间编码技术以不同的颜色、强度和形状精细地生成结构光图案,用独特的标签对特征进行编码。已经提出了详细的空间编码模式,如de bruijn[11]、m阵列[12]和非正式编码。一般来说,空间编码技术设计的模式是单镜头的,因此空间编码模式适合于动态场景。对于时间编码技术[11],设计了基于时间序列的模式,如二进制码、灰度码等。时间编码技术的模式是多镜头的。时间编码方案根据投射到场景上的几个模式的顺序对某个像素进行编码。一般来说,时间编码方案具有精度高的优点,得益于多镜头模式。基于相位的模式由于其鲁棒性和稠密性,在空间编码和时间编码方案中都得到了广泛的应用[13,14]。然而,相位展开问题是不可避免的。同时,投影仪和摄像机的位置也不同。遮挡严重,会导致深度信息丢失。
提出了一种相移结构光技术与深度学习立体匹配相结合的方法来获取遮挡场景的精确深度数据。该方法首先通过深度学习立体匹配得到粗深度图。然后,在粗图的辅助下,利用结构光获得精细的深度图。一方面,利用粗糙信息计算相位周期,避免了结构光的相位模糊;另一方面,遮挡区域的深度数据采用粗深度图填充,克服了结构光固有的不足。显然,我们利用立体匹配和结构光在复杂场景中实现了更好的深度感知。
本文的其余部分安排如下。第二节简要介绍了相关工作。第3节概述了我们的深度传感系统。第4节详细描述了我们的方法。实验结果见第5节。在第六节中,我们将结束本文。
2. Related work
结构光方法虽然可以获得精确的深度图像,但容易受到环境光的照射和遮挡,特别是在彩色区域。为了解决这些问题,研究人员采用立体匹配的方法来提高结构光的性能。王[15]提出了一种混合的三维重建框架,由一个投影仪和两个摄像机组成。该方法利用投影模式数据得到摄像机之间的初始对应关系,然后利用立体匹配消除模糊。它克服了结构光相位匹配的模糊性问题。然而,该方法也存在遮挡问题。卡里希尔[16]提出了一种用于动态形状获取的结构光立体方法。他们投射出一个单镜头的彩色条纹图案,然后通过解码技术估计每个相机和投影机之间的可靠相关性。利用立体匹配技术对一些未解决的区域进行了探索。但是,这种方法不适用于彩色场景。与此同时,简单的单镜头模式产生了一个粗略的深度图。考虑到投影仪的精度低于相机,Li[17]设计了一种结合灰度编码模式和相位模式的组合模式,避免了投影仪的标定。然而,立体匹配只适用于相位展开。无法获得被遮挡区域的深度数据。Weise[18]提出了一种结合立体匹配和结构光测量深度数据的新方法,并提出了一种运动补偿方法来检测动态场景。然而,该方法不能从闭塞区域提取深度数据。Alhwarin[19]采用不同于单投影双摄像机的方法,构建了一个具有两个Kinect运动单元的深度传感系统。这两款深度相机建立了主动立体匹配系统,克服了单台相机的缺点,包括检测距离短,以及由透明、有光泽或非常哑光和吸收物体反射而产生的误差。然而,这两种结构光在实践中是相互影响的。一些研究者提出了基于深度学习的深度获取方法。张[20]提出了一种用于主动立体系统深度估计的自监督学习方法。该方法经过训练,不需要ground-truth,可以预测遮挡区域的深度数据。然而,它不能实现高精度的测量。Eigen[21]提出了一种利用VGG-16获取深度数据的经典深度学习方法。然而,这种方法需要大量的训练数据,数据集限制了应用领域。Garg[22]提出了一种基于单视图的无监督CNN网络来估计深度数据。该方法训练方便,结果令人满意。
我们的方法与以往研究相比,该方法结合了高精度相移法的优点和深度学习立体匹配法的有效性。深度学习立体匹配和结构光的结合提供了两种不同视角的混合深度图。首先,利用深度学习立体匹配方法获得粗深度图。由于我们将结构光投射到场景中,该方案克服了立体匹配方法中无纹理区域的缺点。然后用相移法计算出精细深度图。采用粗深度图来解决相移法中存在的相位模糊问题。同时,考虑到相机和投影机的遮挡是结构光系统固有的弱点,粗深度图可以填充精细深度图中缺少深度数据的区域。
3. Overview of the system
在实验平台上,深度传感系统由一个DLP投影仪和两个RGB相机组成,如图1所示。
投影仪和摄像机放置在同一水平面上,它们的光轴沿极线相互平行。根据外极约束,匹配点的差异只存在于图像的行之间,从而降低了算法的复杂度。投影仪和左相机组成结构光深度感知机构,两相机用于获取粗深度图。对摄像机和投影仪的内外参数进行了预先标定。
图2给出了该方法的实现过程。首先,从投影仪上依次投影出三种相移模式。同时,对三幅不同相位的图像进行序列捕获,并根据场景进行调制。其次,采用深度学习立体匹配法计算粗深度图。注意,结构信息丰富了图像的特征,弥补了立体匹配中无纹理区域的局限性。第三,通过左相机连续拍摄的三幅图像来恢复被展开的相位。相位展开是通过结合粗深度图和移相图信息来实现的。通过相位匹配得到了结构光的精细深度图。最后,通过粗深度图与细深度图的简单比较,填充遮挡区域的深度数据。详细信息将在下面的部分中描述。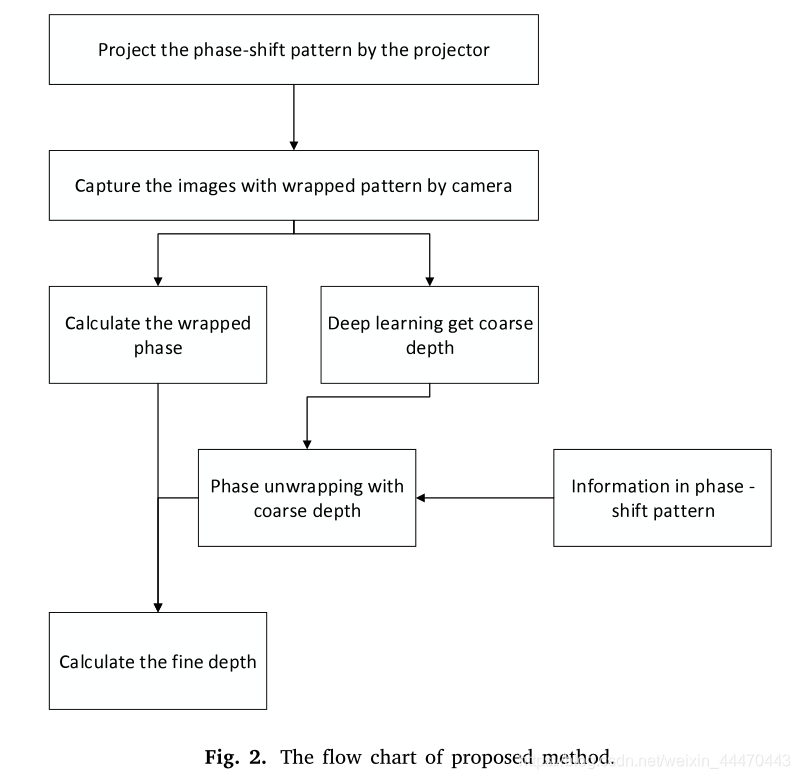
4. Depth sensing algorithm
在上一节对系统和处理流程进行概述的基础上,本节详细描述了结合结构化光和深度学习立体匹配的深度采集。在该方法中,我们在场景[14]上投影了三步相移模式。相移法是一种经典的时间复用、结构光方法。其模式强度随正弦规律的变化而变化,且初始相位不同。对于投影相移模式中的每个像素,其强度定义为式(1):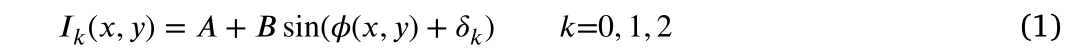
在式(1)中,x,y分别表示像素(x,y)的行坐标和列坐标。
是第k个图案中这个像素的强度。A为直流值,B为信号幅值。初始相位
是
,其中N=3。让T表示强度的周期。
是像素
的绝对相位,计算公式为(2)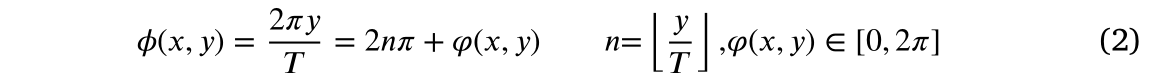
在式(2)中,
是像素(x,y)的包裹相位,n是周期数。
4.1 Structured information based on stereo matching for coarse depth acquisition(基于立体匹配的结构化信息用于粗深度采集)
考虑到特征在立体匹配中是必不可少的,我们使用两个包含结构化信息的场景图像来辅助无纹理区域。考虑到我们只想获得低复杂度的粗深度,可以使用无监督CNN网络[22]。该方法是一种经典的无监督深度图获取方法。我们在实验室环境中拍摄了8000张照片,另外100张照片用于测试。框架如图3所示。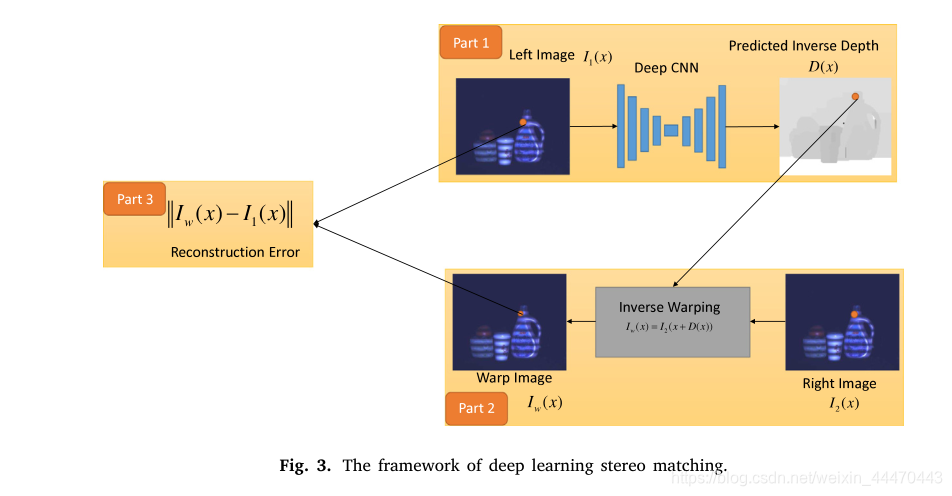
如图3所示,在编码器(第1部分)中输入左摄像机
的图像,编码器是具有堆叠卷积和池层的传统神经网络。此外,该网络将左边的图像转换成深度图
。在第2部分中,解码器根据右相机
的图像合成后向扭曲图像
,以使编码器输出视差。反深度是一个中间深度,而不是最终的预测图。反向扭曲是指利用中间深度数据综合源数据。然后通过一个简单的损失函数将第三部分的
与
进行匹配。在训练过程中,网络通过对差异进行简单的先验平滑,使重构损失最小化。利用这种无监督CNN方法,计算出粗深度图。具体流程可参考[22]。
4.2 Fine depth acquisition
为了创建一个精细的深度图,计算捕获图像中的绝对相位是至关重要的。这意味着我们需要估计包裹相位 并确定其像素周期n。在所有基于阶段的方法中,周期的确定都是瓶颈。在这里,我们简要讨论了包层相位的估计。
4.2.1 Wrapped phase estimation
在该方案中,左右摄像头都可以捕获场景的三幅图像
。我们可以选择其中一个进行相位估计。这三幅图像定义为式(3)。
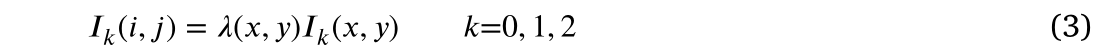
在式(3)中,
表示每个点的反射率。在局部区域中,a保持近似恒定值。组合等式(1)和(3),我们有:
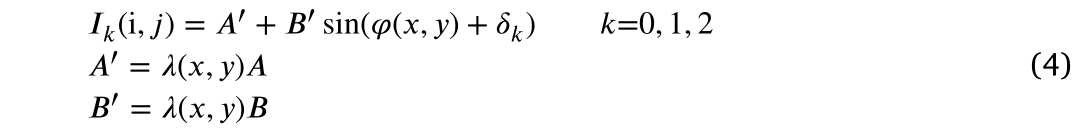
式(4)中,A′,B′,
为未知参数。显然,我们需要至少三个
来解这个方程。我们可以用公式(5)计算包裹相
。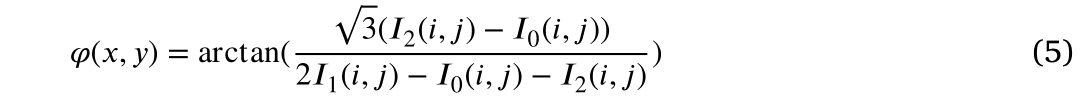
4.2.2 Phase unwrapping with the assistance of the coarse map
在基于相位的方法中,相位展开用来确定相位的正确周期。我们倾向于利用粗深度来辅助相位展开。在提出的方案中,我们使用左摄影机和投影仪来侦测结构光的深度。投影仪相机的极线几何结构如图4所示。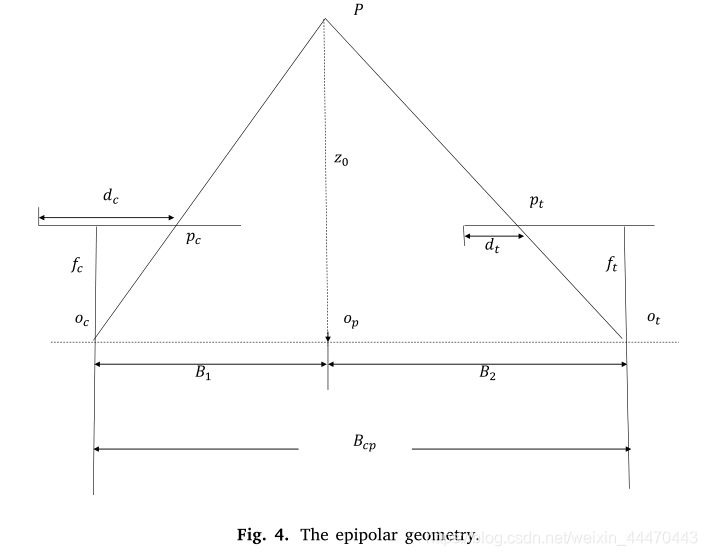 p是场景的一个点。图案中的点
是相机中
的匹配点。
和
分别是摄像机和投影仪的光学中心。
和
是相机焦距和投影仪焦距。
是相机和投影仪之间的基线。
是p在基线上的投影。
为摄像机中心距
的距离,
为投影仪中心距
的距离,摄像机和投影仪的分辨率分别为
和
。
是通过深度学习立体匹配获得的粗深度。
和
分别表示相机和投影仪的每个像素的实际大小。
是当前像素
和相机视野中左边框之间的距离。
是投影图案中
与左边框之间的距离。投影仪可以看作是相机的逆模型。相机和投影仪的标准化比例定义为等式(6)。
p是场景的一个点。图案中的点
是相机中
的匹配点。
和
分别是摄像机和投影仪的光学中心。
和
是相机焦距和投影仪焦距。
是相机和投影仪之间的基线。
是p在基线上的投影。
为摄像机中心距
的距离,
为投影仪中心距
的距离,摄像机和投影仪的分辨率分别为
和
。
是通过深度学习立体匹配获得的粗深度。
和
分别表示相机和投影仪的每个像素的实际大小。
是当前像素
和相机视野中左边框之间的距离。
是投影图案中
与左边框之间的距离。投影仪可以看作是相机的逆模型。相机和投影仪的标准化比例定义为等式(6)。

在公式6中,
是投影仪的标准列。根据图4中的几何关系,有两个方程来模拟一对对应的匹配点
和
:


通过分别将等式(7)和(8)的两边相加,我们可以得到:
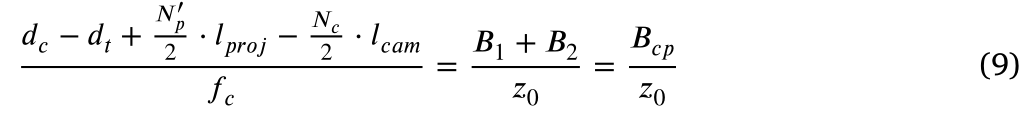
将
和
定义为
和
的列号。
,
。
表示为等式10:
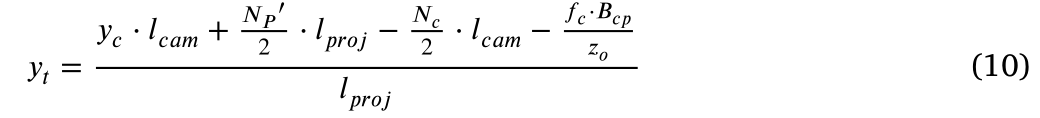
考虑到
是深度学习立体匹配的粗深度,
是场景变形模式中
的粗糙的列坐标。
是一个粗糙的绝对相位。通过等式2,我们可以得到:

包裹相
的周期由式(11)获得:

从而得到
的准确列数:

4.2.3. Fine depth calculation
如上所述,左相机的光轴与投影仪的光轴平行,系统垂直对齐,因此极线沿垂直方向排列。我们只需要沿着列方向搜索对应的相位对。精细深度
采用三角剖分原理计算:

在等式15中,
,d代表视差。
图5给出了该方法的过程。场景中有一张地图和几本书。图5(a)为左相机捕捉到的变形图像,图5(b)为右相机捕捉到的变形图像。图5(d)为左右摄像头深度学习立体匹配得到的粗深度图。展开相位如图5©所示,由式(5)得到。图5(e)为变形图像的展开阶段。很明显,相位的强度是周期性变化的。因此,相位展开是必要的,在粗深度图的帮助下,绝对相位如图5(e)所示。精细深度图如图5(f)所示。书的边缘被清晰地重构,地图的微小波动也被区分出来,这反映了我们提出的方法的高精度。
4.3. Filling the depth data of the occluded area
在结构光方法中,由于摄像机和投影仪的角度不同,在精细深度图中存在遮挡区域。但是,我们有一个粗略的深度图来补偿这些区域丢失的深度数据。粗深度图和细深度图具有相同的分辨率。因此,精细深度图中的每个像素对应于粗深度图中位于同一位置的像素。通过对精细深度图和粗深度图的比较,可以找到遮挡区域,并利用粗深度数据进行填充。
5. Experimental result
在这一节中,给出了一些实验结果来证明我们提出的方法的可行性。本节给出的所有经验都是在真实的场景中进行的。用一台DLP投影仪和两台摄像机对该方法进行了评价。摄像机是 Point Grey Grasshopper3。DLP投影仪基于TI的DMD(数字微镜装置)光指挥仪(Light Craft 4500)。投影机和摄像机的分辨率分别为9121140和20482048。提前对实验平台进行了标定。投影仪和右摄像机之间的基线为109.6 mm,而摄像机之间的基线为60.1 mm。条纹图案T的周期为30像素。T是条纹图案的周期。理论上,频率越高,对全局光照的抵抗力就越强。然而,由于光学像差,投影仪不能可靠地投射任意高频[23]。根据我们投影仪的解法和实际实验中的全局光照,我们将T设为30像素。通过定量实验和定性实验验证了该方法的有效性。
5.1. Quantitative analysis
本实验以Kinect (Kinect v2)和ToF sensor (SR4000)作为比较对象,与我们的方法进行比较。我们在平台前面设置了一系列不同深度的平面,从900毫米到1400毫米不等。在每一个距离处,我们在不移动或振动设备的情况下,计算了大约10次深度。用最小二乘法计算距离的真值。我们采用重建的rmse作为指标。三种不同装置的性能如图6所示。如图所示,我们提出的方法的精度优于kinect v2和sr4000。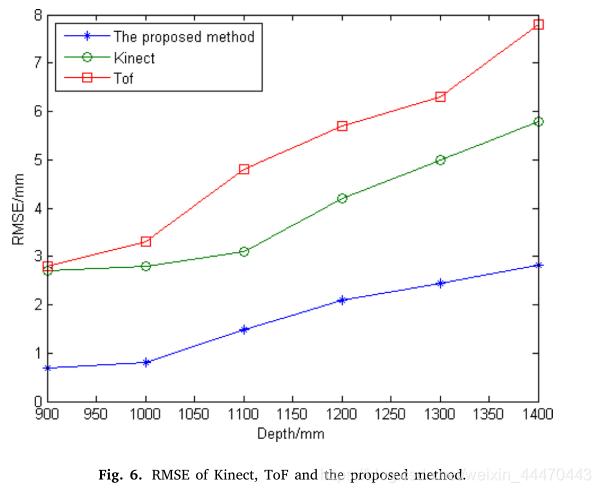
图7给出了使用三个平面来验证所提出方法的准确性的实验。在这个实验中,一个盒子和两本书按顺序摆放。盒子在书的前面。图7(a)是由左照相机拍摄的变形图像之一。图7(b)和7(c)是深度图和场景重建。我们发现深度图的表面和重建是平滑的。图7(d)是图7(b)中的深度图的横截面图结果。红线是三个物体的真实深度。地面真实数据的拟合次数超过10次。表1是我们提出的方法绝对误差的平均值。可以看出,该方法具有较高的精度。同时,我们发现有两个闭塞区域。它们由图7(a)中的蓝线标记。得益于我们所提出的方法,图7(a)中的边是尖锐连续的。此外,我们观察到框中有一些错误的深度数据,它们已经被图7©中的红色圆圈标记出来。由于镜面反射,结构光信息在这一区域丢失。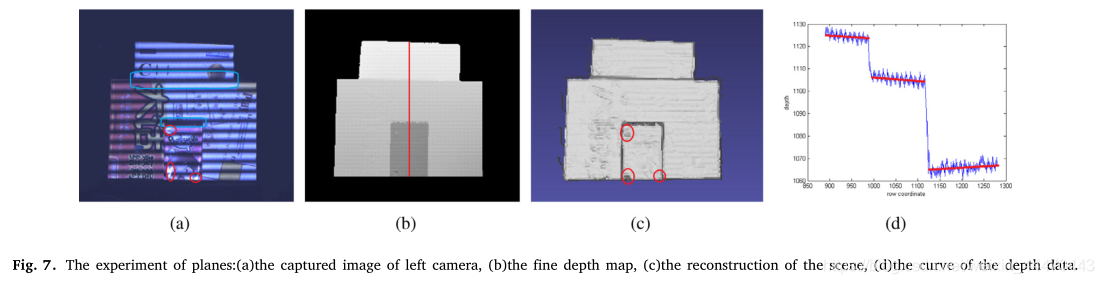

5.2. Qualitative analysis
为了通过定性分析验证该方法的性能,我们构造了两个复杂的场景,如图所示8(a)和8(d)。在图8(a)中,对象具有不同的颜色并且包含反射。图8(d)是一个耳朵的雕塑。图8(a)中的对象包含特别高的纹理量。物体表面纹理的深度检测具有挑战性,因为纹理可能会导致展开误差。采用结构光和深度学习相结合的方法,可以正确地解包相位,达到较高的解包精度。图8(b)和图8(e)是两个场景的深度图。我们观察到深度图的边缘是清晰的。它们被重建,如图8©和图8(f)所示。结果表明,该方法在复杂场景下是可行的。

在深度传感中,遮挡的恢复也是一个挑战。在本实验中,我们建构两个明显被遮挡的场景来验证我们所提出的方法的效能。实验结果如图9所示。图9(a)是一个被杯子明显遮挡的瓶子。图9(f)是书被左边的瓶子遮挡的情况。图9(b)和图9(g)为结构光获取的深度图。深度数据在红色圆圈标记的区域中丢失。图9(c.)和图9(h)分别是图9(b)和图9(g)遮挡的放大细节。显然,遮挡太明显,无法在该区域获得准确的深度数据。图9(d)和图9(i)是我们提出的方法的结果。填充遮挡区域的深度数据,放大后的细节如图9(e)和图9(j)所示。该方法将结构光与深度学习立体匹配相结合,可以弥补结构光系统的不足。粗深度图可以填充精细深度图中缺少深度数据的区域。
6. Conclusion
提出了一种将结构光与深度学习立体匹配相结合的深度计算方法。为了解决立体匹配中无纹理的问题,采用深度学习立体匹配技术,利用一对具有丰富结构信息的左右双目图像,计算出粗深度图。在结构化方法中,相位展开是通过粗深度图来实现的。通过相位匹配得到了结构光的精细深度图。同时,粗深度数据可以填充精细地图的遮挡区域。实际实验证明,该方法能够实现精确的深度图,并在深度传感中有效地消除遮挡。
Acknowledgment
这项工作得到国家自然科学基金(61672404, 61632019, 61751310、61875157、61572387)的支持,《中国国防基础科学研究计划》(JCKY2017204B102)、《中国中央大学基础研究基金》(编号SA-ZD1602203、JBG160228、JBG160213)、《中国陕西省自然科学基础研究计划》(计划编号2016ZDJC-08)。
Conflict of interest
作者声明,他们没有已知的相互竞争的经济利益或个人关系,可能会对本文报告的工作产生影响。