文章:Deep Learning for Omnidirectional Vision: A Survey and New Perspectives
Background
OmniDirectional image (ODI) data:
- 360 image
- panoramic image
- spherical image data
ODI advantages:
- wide FoV of spherical imaging
- rich geometric information
- multiple projection types
ODI challenges:
- severe distortion in the equirectangular projection (ERP) type
- content discontinuities in the cubemap projection (CP) format
DL types:
- CNN
- RNN
- GANs
- GNN
- VIT
DL-methods focus on four major aspects:
- (I) convolutional filters used to extract features from the ODI data (omnidirectional video (ODV) can be considered as a temporal set of ODIs)
- (II) network design by considering the input numbers and
projection types - (III) novel learning strategies
- (IV) practical applications
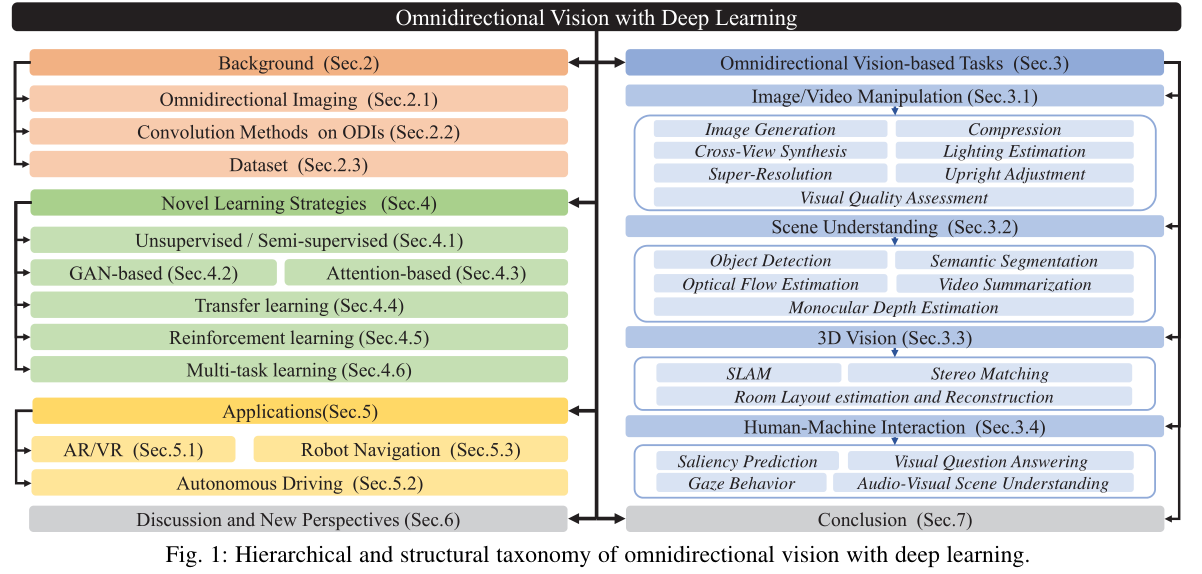
Omnidirectional Imaging
Coordinate
- spherical coordinate ( ρ , θ , ϕ ) (\rho,\theta,\phi) (ρ,θ,ϕ)表示半径和经纬度
- Cartesian coordinate ( x , y , z ) (x,y,z) (x,y,z)
- 关系:
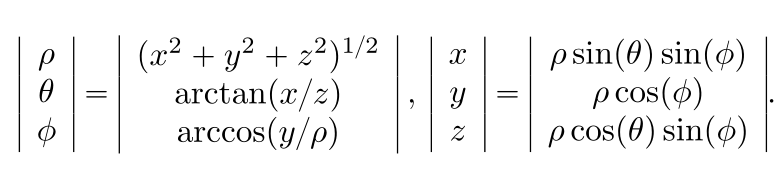
Spherical representation types:
- ERP: 横坐标 π w \frac{\pi}{w} wπ,纵坐标 2 π h \frac{2\pi}{h} h2π
- CP: 6个 90 FoV的立方体面 , 面边长 w w w, 焦距 w 2 \frac{w}{2} 2w
- 针对CP空间采样率不均设计的Equi-Angular Cubemap (EAC) projection
- Tangent:在球坐标和 pixels on the tangent images之间建立一一映射
- Icosahedron:CP、ERP的面细分为更小的面,细分度需要在精度和效率间权衡
- 为此设计的CNN:“Spherephd: Applying cnns on a spherical polyhedron representation of 360˝ images,“CVPR, 2019.和“Spheresr,” CVPR, 2022
- 将球面转化为非空间域
- 3D rotation group (SO3)
- spherical Fourier transformation (SFT)
CP and tangent images suffer from the challenges
- higher computational cost
- discrepancy
- discontinuity
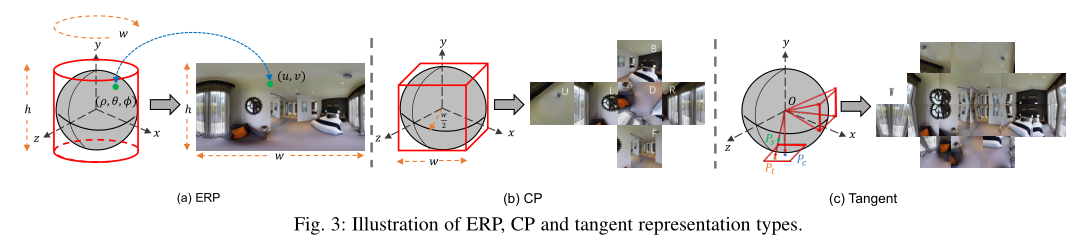
Spherical Stereo
- 两视点基线为 b = ( δ x , δ y , δ z ) \mathbf b=(\delta x, \delta y, \delta z) b=(δx,δy,δz)
- 球坐标系 ( ρ , θ , ϕ ) (\rho,\theta,\phi) (ρ,θ,ϕ)中的角度差为 ( δ θ , δ ϕ ) (\delta_\theta,\delta_\phi) (δθ,δϕ)
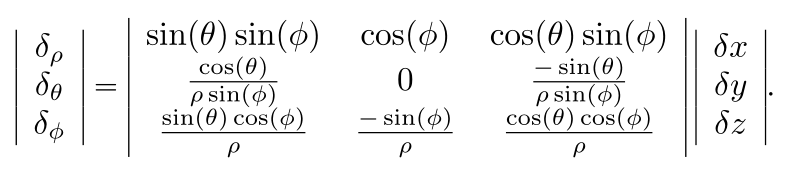
Convolution Methods on ODI
当球形图像投影回平面时,处理失真的CNN改进方法可分为两大类:
- 在平面投影上2D conv
- 在球面域spherical conv

平面投影上2D conv:
-
针对ERP类型
- 利用规则的卷积滤波器,根据球坐标自适应核大小。然而,如图4(a)所示,规则卷积权重仅沿每行共享,不能从头开始训练。“Learning spherical convolution for fast features from 360˝ imagery,” in NIPS, 2017
- SphereNet 提出了另一种典型方法,该方法通过直接调整卷积滤波器的采样网格位置来处理ERP,以实现失真不变性,并且可以端到端地进行训练,如图4(b)所示。图c、d也是类似思路
- 此外还有SO3、加权图结构的方法
-
之接应用2D CNN 到CP和Tangent类型
- ”Bifuse: Monocular 360 depth estimation via bi-projection fusion,” in CVPR,2020.
- “360MonoDepth: High-resolution 360˝ monocular depth estimation,” in CVPR, 2022.
在球面域spherical conv
- “Learning so(3) equivariant representations with spherical cnns,” in ECCV,
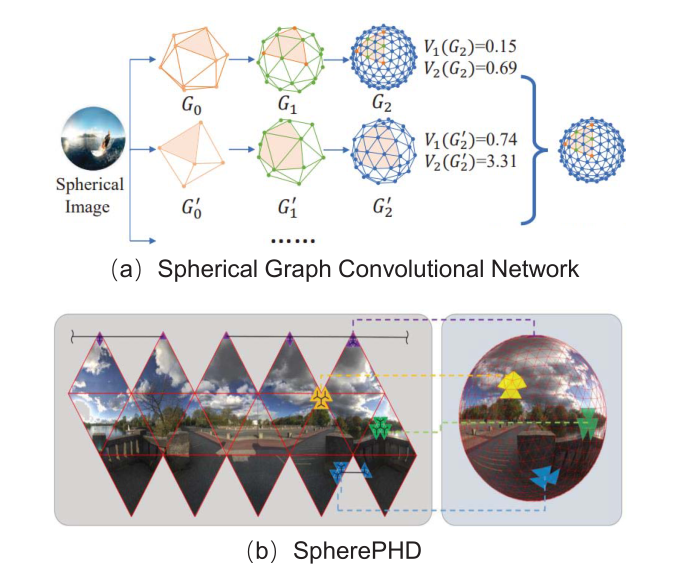
2018 提出了第一种球形CNN结构,该结构考虑了球谐域中的卷积滤波器,以解决标准CNN中的三维旋转等效问题 - Graph Convolutional Network
- SpherePHD:设计图b的球形多面体
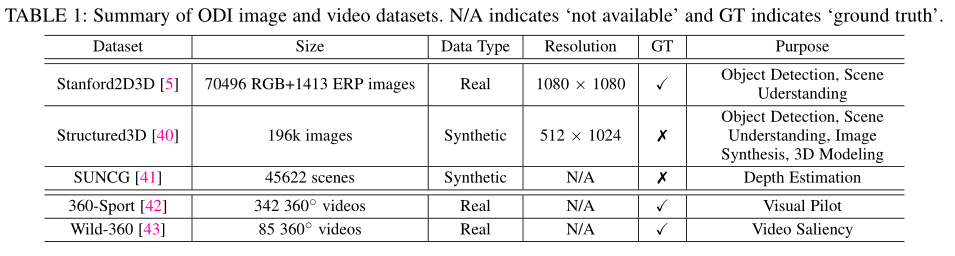
Dataset
以下仅仅是笔者关心的领域,实际上文中涉及了很多方面。
OMNIDIRECTIONAL VISION TASKS
Depth Completion:
“Cross-modal 360˝ depth completion and reconstruction for large-scale indoor environment,” IEEE Trans. Intell. Transp. Syst., 2022.
- 提出了一个具有代表性的两阶段框架,以实现全景深度补全
“Bips: Bimodal indoor panorama synthesis via residual depth-aided adversarial
learning,” arXiv, 2021 - GAN框架
ODI Completion
…
View Synthesis
- OmniNeRF
- Pathdreamer(indoor):取视频游走的两个节点,生成节点间新路径的视图
Cross-view Synthesis and Geo-localization
目的是从卫星视图图像合成地面视图ODI,而 geo-localization的目的是匹配地面视图ODI和卫星视图图像,以确定它们之间的关系
…
Lighting Estimation
…
Human Behavior Understanding
…
Stereo Matching
人的双眼视差取决于视网膜上投影之间的差异,即球面投影而非平面投影。因此,ODIs上的立体匹配与人类视觉系统更为相似。
“A study on the influence of omnidirectional distortion on cnn-based stereo vision,” in
VISIGRAPP, 2021.
- 讨论了全方位失真对基于CNN的方法的影响
- 并比较了从透视图和全方位立体图像预测的视差图的质量。实验结果表明,基于ODIs的立体匹配更具优势
General stereo matching algorithms follow four steps:
- matching cost computation
- cost aggregation,
- disparity computation with optimization
- disparity refinement
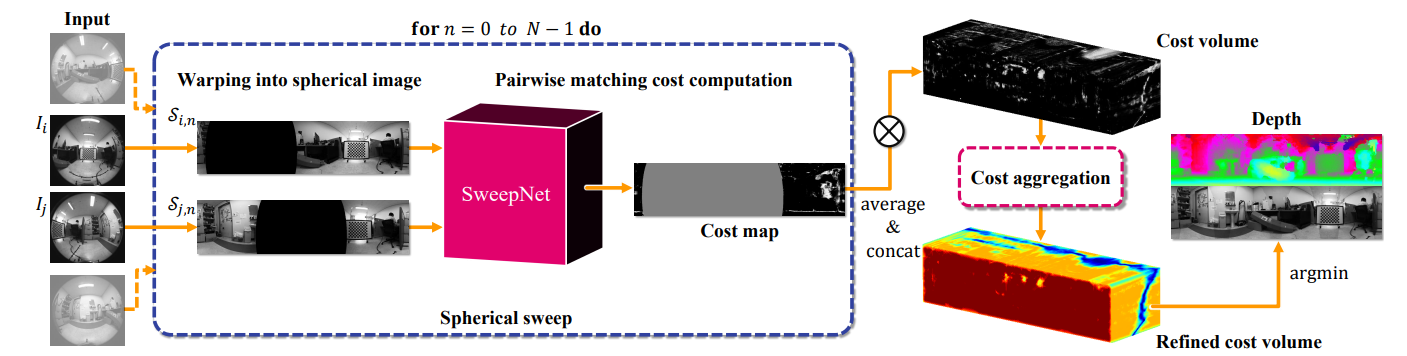
SweepNet提出了一种宽基线立体系统,用于从带有超宽FoV镜头的相机捕获的一对图像计算匹配成本图,并在rig坐标系下使用全局球体扫描直接生成全向深度图:
OmniMVS将四个220 FoV鱼眼视图作为输入来训练端到端DNN模型,并使用3D编码器-解码器块来正则化。
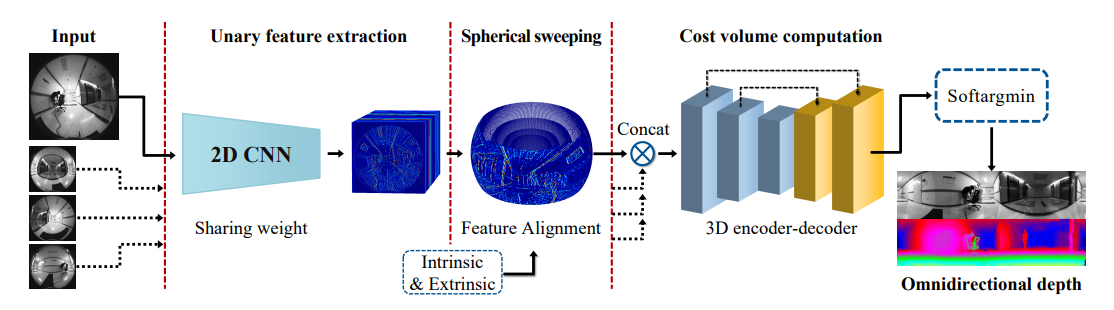
“End-to-end learning for omnidirectional stereo matching with uncertainty prior,” IEEE TPAMI, 2021.中改进OmniMVS,提供了一种基于uncertainty of prior guidance的正则化
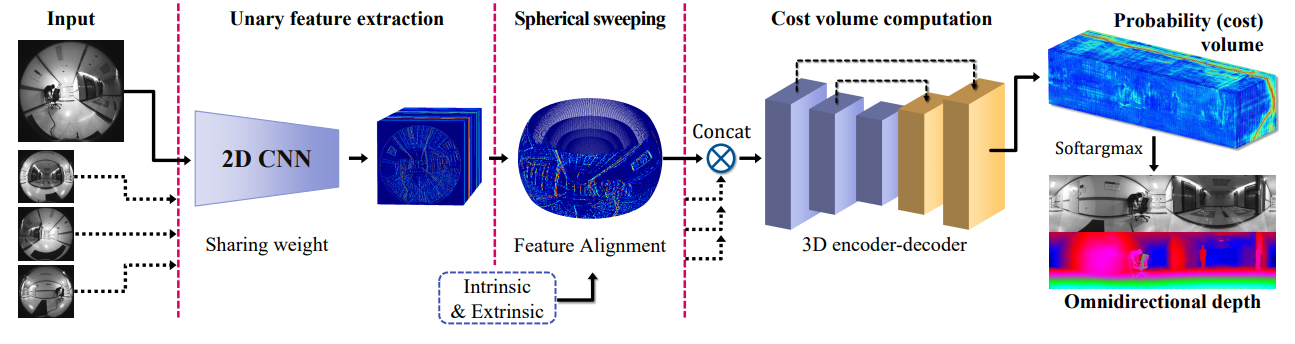
ODV:omnidirectional video
在这一研究领域中只有少数几种方法,一片荒地。
- 作为一项与时间相关的任务,将transformer机制应用于ODV摘要可能是有益的。
- 此外,以前的工作只考虑了ERP格式,这是最严重的失真问题。因此,最好将CP、切线投影或球体格式作为ODV的输入。