一、概述:
1. 在GitHub上下载SSD模型代码
2. 准备自己的VOC数据集
3. 搭建Pytorch环境
4. 用Pytorch框架在Pycharm中跑模型
5. 遇到的问题和解决方法
6. 模型预测效果的检验和检测指标的查看
二、本文使用电脑配置:
硬件:联想拯救者R9000P 2021(R7 5800H/16GB/512GB/RTX3070)
软件:Win10系统、Anaconda3、Python3.8.0、pycharm
Pytorch配置:pytorch1.7.1和torchvision0.8.2
三、详细步骤:
1. 在GitHub上下载SSD模型代码
链接:https://github.com/bubbliiiing/ssd-pytorch
首先前往Github下载对应的仓库,下载完后利用解压软件解压,之后用编程软件打开文件夹。
注意打开的根目录必须正确,否则相对目录不正确的情况下,代码将无法运行。
一定要注意打开后的根目录是文件存放的目录。
2. 准备自己的VOC数据集
本文使用VOC格式进行训练,训练前需要自己制作好数据集,如果没有自己的数据集,可以通过Github连接下载VOC12+07的数据集尝试下。
VOC12+07的数据集链接:
①训练前将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的Annotation中。
②训练前将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中。
然后是数据集的处理:
在完成数据集的摆放之后,我们需要对数据集进行下一步的处理,目的是获得训练用的2007_train.txt以及2007_val.txt,需要用到根目录下的voc_annotation.py。
voc_annotation.py里面有一些参数需要设置。
分别是annotation_mode、classes_path、trainval_percent、train_percent、VOCdevkit_path,第一次训练可以仅修改classes_path,对应指向我们在model_data文件夹中新建的cls_classes.txt(内容就是我们要训练的类标签)
3. 搭建Pytorch环境
这里我用的Pytorch配置为pytorch1.7.1和torchvision0.8.2,具体配置方法,见下面这篇博客,链接:
4. 用Pytorch框架在Pycharm中跑模型
环境配置好以后就可以打开Pycharm进行模型的训练啦!
训练第一步:导入自己的数据集
训练第二步:修改模型参数
训练第三步:Debug
训练第四步:开始训练
训练第五步:训练完成后对模型检测精度的检测
具体步骤见我的另一篇博客,
或者在BliBli中跟着Bubbliiiing进行学习~
Pytorch 搭建自己的SSD目标检测平台(Bubbliiiing 深度学习 教程)_哔哩哔哩_bilibili
5. 遇到的问题和解决方法
这里就是上一步中提到的Debug环境啦!
问题一:在第一轮训练未开始就失败,或者训练几轮(此时的训练数据加载得会特别慢)然后失败,报错均为如下情况:RuntimeError: CUDA out of memory. Tried to allocate 2.14 GiB (GPU 0; 8.00 GiB total capacity; 279.45 MiB already allocated; 5.81 GiB free; 338.00 MiB eserved in total by PyTorch)
提醒:出现内存够,但是运行内存超出的情况。

解决:按下述方式修改输入的图片尺寸,并改小Batch_Size。
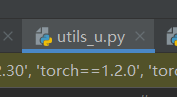
①修改utils_u.py中的img_min_side为224

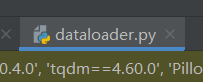
②修改dataloader.py中的input_shape为[224,224]

③修改train.py中的input_shape为[224,224],并改小batch_size,此相处我改成了1。



再次运行,问题解决可以训练了!

问题二:训练进行了一段时间,又出现了如下报错:
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://www.intel.com/software/products/support/.

解决:
在train.py文件中添加如下代码:
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"再次训练中途就没有出现报错啦,问题解决!
6. 模型预测效果的检验和检测指标的查看
模型预测效果的检验:
修改predict.py文件
指标的查看方法:
Pytorch 搭建自己的SSD目标检测平台(Bubbliiiing 深度学习 教程)_哔哩哔哩_bilibili
①修改frcnn.py文件中的model_path,使其指向logs文件夹中由训练新生成的.pth文件,修改classes_path,使其指向model_data文件夹下的cls_classes.txt。
②修改get_map.py文件中的classes_path为model_data文件夹下的cls_classes.txt。
③运行get_map.py。就可以在新生成的文件下的result中查看模型的训练精度等各种参数了。