1. 为什么用多头注意力机制
-
所谓自注意力机制就是通过某种运算来直接计算得到句子在编码过程中每个位置上的注意力权重;然后再以权重和的形式来计算得到整个句子的隐含向量表示。
-
自注意力机制的缺陷就是:模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置, 因此作者提出了通过多头注意力机制来解决这一问题。
2. 什么是多头注意力机制
在实践中,当给定相同的查询、键和值的集合时,我们希望模型可以基于相同的注意力机制学习到不同的行为,然后将不同的行为作为知识组合起来,例如捕获序列内各种范围的依赖关系(例如,短距离依赖和长距离依赖)。因此,允许注意力机制组合使用查询、键和值的不同的 子空间表示(representation subspaces)可能是有益的。
为此,与使用单独的一个注意力池化不同,我们可以独立学习得到 h h h 组不同的 线性投影(linear projections)来变换查询、键和值。然后,这 h h h 组变换后的查询、键和值将并行地进行注意力池化。最后,将这 h h h 个注意力池化的输出拼接在一起,并且通过另一个可以学习的线性投影进行变换,以产生最终输出。这种设计被称为 多头注意力,其中 h h h 个注意力池化输出中的每一个输出都被称作一个 头 Vaswani.Shazeer.Parmar.ea.2017。下图展示了使用全连接层来实现可以学习的线性变换的多头注意力。
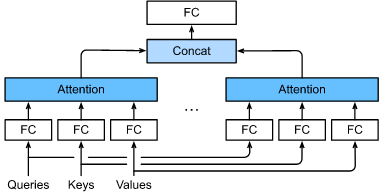
3. 多头注意力机制模型和理论计算
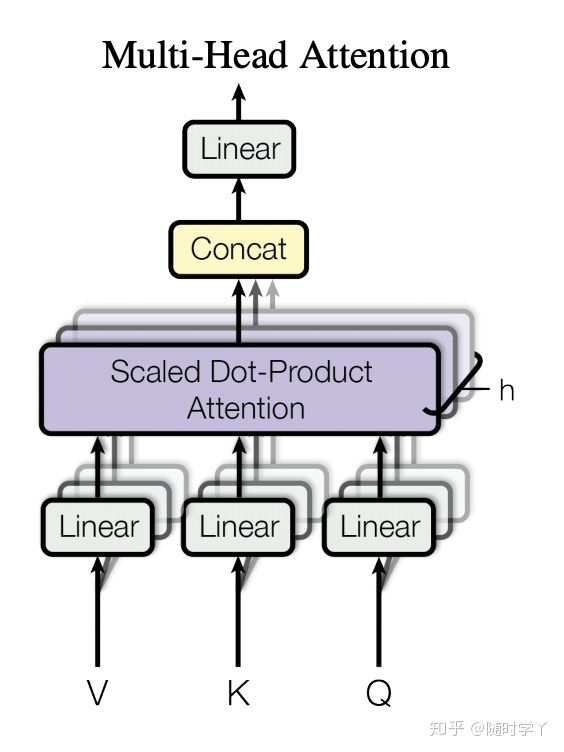
在实现多头注意力之前,让我们用数学语言将这个模型形式化地描述出来。给定查询 q ∈ R d q \mathbf{q} \in \mathbb{R}^{d_q} q∈Rdq、键 k ∈ R d k \mathbf{k} \in \mathbb{R}^{d_k} k∈Rdk 和值 v ∈ R d v \mathbf{v} \in \mathbb{R}^{d_v} v∈Rdv,每个注意力头 h i \mathbf{h}_i hi ( i = 1 , … , h i = 1, \ldots, h i=1,…,h) 的计算方法为
h i = f ( W i ( q ) q , W i ( k ) k , W i ( v ) v ) ∈ R p v , \mathbf{h}_i = f(\mathbf W_i^{(q)}\mathbf q, \mathbf W_i^{(k)}\mathbf k,\mathbf W_i^{(v)}\mathbf v) \in \mathbb R^{p_v}, hi=f(Wi(q)q,Wi(k)k,Wi(v)v)∈Rpv,
其中,可学习的参数包括 W i ( q ) ∈ R p q × d q \mathbf W_i^{(q)}\in\mathbb R^{p_q\times d_q} Wi(q)∈Rpq×dq、 W i ( k ) ∈ R p k × d k \mathbf W_i^{(k)}\in\mathbb R^{p_k\times d_k} Wi(k)∈Rpk×dk 和 W i ( v ) ∈ R p v × d v \mathbf W_i^{(v)}\in\mathbb R^{p_v\times d_v} Wi(v)∈Rpv×dv ,以及代表注意力池化的函数 f f f 可以是可加性注意力和缩放的“点-积”注意力。多头注意力的输出需要经过另一个线性转换,它对应着 h h h 个头拼接后的结果,因此其可学习参数是 W o ∈ R p o × h p v \mathbf W_o\in\mathbb R^{p_o\times h p_v} Wo∈Rpo×hpv:
W o [ h 1 ⋮ h h ] ∈ R p o . \mathbf W_o \begin{bmatrix}\mathbf h_1\\\vdots\\\mathbf h_h\end{bmatrix} \in \mathbb{R}^{p_o}. Wo⎣⎢⎡h1⋮hh⎦⎥⎤∈Rpo.
基于这种设计,每个头都可能会关注输入的不同部分。可以表示比简单加权平均值更复杂的函数。
有掩码的多头注意力:
- 解码器对序列中一个元素输出时,不应该考虑该元素之后的元素
- 通过掩码进行实现:在计算 x i x_i xi输出时,假装当前序列长度为i
微观下的多头Attention可以表示为:
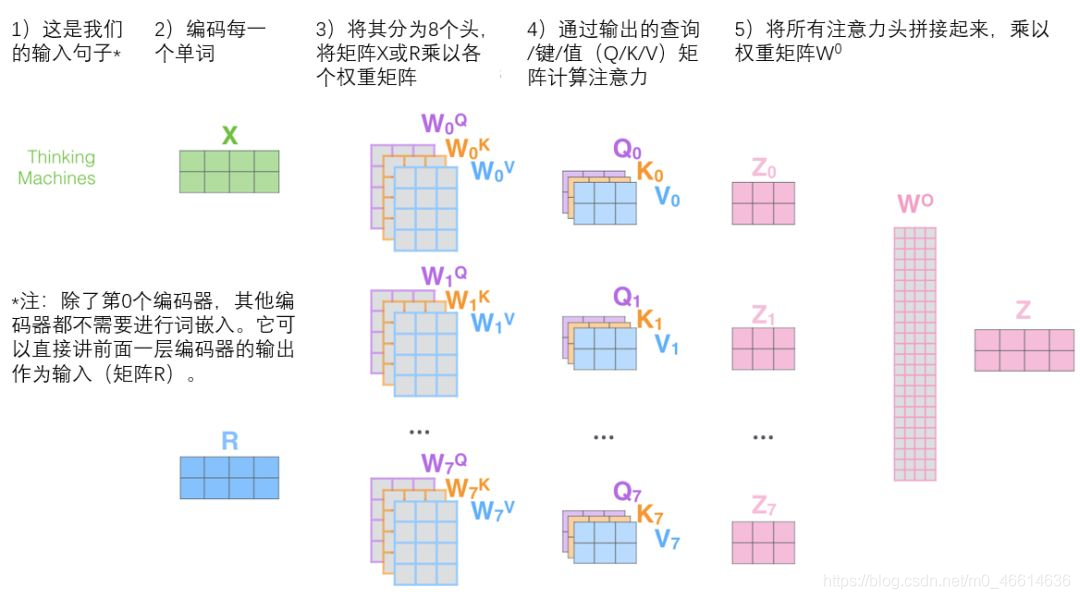
4. 动手实现多头注意力机制层
在实现过程中,我们选择了缩放的“点-积”注意力作为每一个注意力头。为了避免计算成本和参数数量的显著增长,我们设置了 p q = p k = p v = p o / h p_q = p_k = p_v = p_o / h pq=pk=pv=po/h。值得注意的是,如果我们将查询、键和值的线性变换的输出数量设置为 p q h = p k h = p v h = p o p_q h = p_k h = p_v h = p_o pqh=pkh=pvh=po,则可以并行计算 h h h 头。在下面的实现中, p o p_o po 是通过参数num_hiddens 指定的。
import math
import torch
from torch import nn
from d2l import torch as d2l
def transpose_qkv(X,num_heads):
# 输入 `X` 的形状: (`batch_size`, 查询或者“键-值”对的个数, `num_hiddens`).
# 输出 `X` 的形状: (`batch_size`, 查询或者“键-值”对的个数, `num_heads`,`num_hiddens` / `num_heads`)
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# 输出 `X` 的形状: (`batch_size`, `num_heads`, 查询或者“键-值”对的个数,`num_hiddens` / `num_heads`)
X = X.permute(0, 2, 1, 3)
# `output` 的形状: (`batch_size` * `num_heads`, 查询或者“键-值”对的个数,`num_hiddens` / `num_heads`)
return X.reshape(-1, X.shape[2], X.shape[3])
def transpose_output(X,num_heads):
"""逆转 `transpose_qkv` 函数的操作"""
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
class MultiHeadAttention(nn.Module):
def __init__(self,key_size,query_size,value_size,num_hiddens,
num_heads,dropout,bias=False,**kwargs):
super(MultiHeadAttention,self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
self.W_q = nn.Linear(query_size,num_hiddens,bias=bias) # 将输入映射为(batch_size,query_size/k-v size,num_hidden)大小的输出
self.W_k = nn.Linear(key_size,num_hiddens,bias=bias)
self.W_v = nn.Linear(value_size,num_hiddens,bias=bias)
self.W_o = nn.Linear(num_hiddens,num_hiddens,bias=bias)
def forward(self,queries,keys,values,valid_lens):
# `queries`, `keys`, or `values` 的形状:
# (`batch_size`, 查询或者“键-值”对的个数, `num_hiddens`)
# `valid_lens` 的形状:
# (`batch_size`,) or (`batch_size`, 查询的个数)
# 经过变换后,输出的 `queries`, `keys`, or `values` 的形状:
# (`batch_size` * `num_heads`, 查询或者“键-值”对的个数,`num_hiddens` / `num_heads`)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads) # 将多个头的数据堆叠在一起,然后进行计算,从而不用多次计算
if valid_lens is not None:
valid_lens = torch.repeat_interleave(valid_lens,
repeats=self.num_heads,
dim=0)
output = self.attention(queries,keys,values,valid_lens) # output->(10,4,20)
# return output
output_concat = transpose_output(output,self.num_heads) # output_concat -> (2,4,100)
return self.W_o(output_concat)
让我们使用键和值相同的小例子来测试我们编写的 MultiHeadAttention 类。多头注意力输出的形状是(batch_size、num_queries、num_hiddens)。
# 线性变换的输出为100个,5个头
num_hiddens, num_heads = 100, 5
attention = MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,num_hiddens, num_heads, 0.5)
attention.eval()
MultiHeadAttention(
(attention): DotProductAttention(
(dropout): Dropout(p=0.5, inplace=False)
)
(W_q): Linear(in_features=100, out_features=100, bias=False)
(W_k): Linear(in_features=100, out_features=100, bias=False)
(W_v): Linear(in_features=100, out_features=100, bias=False)
(W_o): Linear(in_features=100, out_features=100, bias=False)
)
# 2个batch,4个query,6个键值对
batch_size, num_queries, num_kvpairs, valid_lens = 2, 4, 6, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens)) # query(2,4,100)
Y = torch.ones((batch_size, num_kvpairs, num_hiddens)) # key和value (2,6,100)
output = attention(X, Y, Y, valid_lens) # 输出大小与输入的query的大小相同
output.shape
torch.Size([2, 4, 100])
小结
- 多头注意力融合了来自于相同的注意力池化产生的不同的知识,这些知识的不同来源于相同的查询、键和值的不同的子空间表示。
- 基于适当的张量操作,可以实现多头注意力的并行计算。
练习
- 分别可视化这个实验中的多个头的注意力权重。
- 假设我们已经拥有一个完成训练的基于多头注意力的模型,现在希望修剪最不重要的注意力头以提高预测速度。应该如何设计实验来衡量注意力头的重要性?