紧接上回:【动手深度学习-笔记】注意力机制(二)注意力评分函数
在实践中,我们希望模型可以基于相同的注意力机制学习到不同的行为,抽取不同的信息(比如长距离依赖关系和短距离依赖关系),再将这些信息组合起来。
为此,与其只使用单独一个注意力汇聚, 我们可以用独立学习得到的 h h h组不同的线性投影(linear projections)来变换查询、键和值,并行地送入到注意力汇聚,再将 h h h组汇聚结果拼接到一起。
这种设计被称作多头注意力(multihead attention),融合了来自于多个注意力汇聚的不同知识,这些知识的不同来源于相同的查询、键和值的不同的子空间表示。
这里的“头”的概念类似于“通道”的概念,一个头表示一个注意力汇聚。
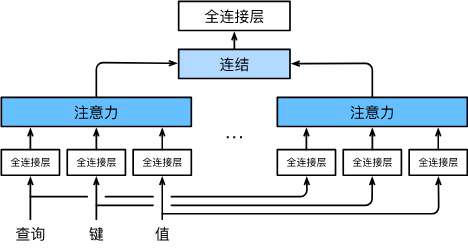
模型
给定查询 q ∈ R d q \mathbf{q} \in \mathbb{R}^{d_q} q∈Rdq,键 k ∈ R d k \mathbf{k} \in \mathbb{R}^{d_k} k∈Rdk,值 v ∈ R d v \mathbf{v} \in \mathbb{R}^{d_v} v∈Rdv,每个注意力头 h i ( i = 1 , … , h ) \mathbf{h}_i(i = 1, \ldots, h) hi(i=1,…,h)的计算方法:
h i = f ( W i ( q ) q , W i ( k ) k , W i ( v ) v ) ∈ R p v , (1) \mathbf{h}_i = f(\mathbf W_i^{(q)}\mathbf q, \mathbf W_i^{(k)}\mathbf k,\mathbf W_i^{(v)}\mathbf v) \in \mathbb R^{p_v},\tag{1} hi=f(Wi(q)q,Wi(k)k,Wi(v)v)∈Rpv,(1)
原本 q \mathbf{q} q、 k \mathbf{k} k、 v \mathbf{v} v的维度分别为 d q d_q dq、 d k d_k dk、 d v d_v dv,经过 W i \mathbf{W}_i Wi线性投影为 p q p_q pq、 p k p_k pk、 p v p_v pv维度;
输入到注意力汇聚函数 f f f得到汇聚结果 h i ∈ R p v \mathbf{h}_i\in \mathbb{R}^{p_v} hi∈Rpv, f f f可以是加性注意力或者是缩放点积注意力等;
然后将得到的 h i \mathbf{h}_i hi组合,经过 W o ∈ R p o × h p v \mathbf W_o\in\mathbb R^{p_o\times hp_v} Wo∈Rpo×hpv进行另一个线性转换,得到最终输出:
W o [ h 1 ⋮ h h ] ∈ R p o . \begin{split}\mathbf W_o \begin{bmatrix}\mathbf h_1\\\vdots\\\mathbf h_h\end{bmatrix} \in \mathbb{R}^{p_o}.\end{split} Wo⎣
⎡h1⋮hh⎦
⎤∈Rpo.
其中的可学习参数为 W i ( q ) ∈ R p q × d q \mathbf W_i^{(q)}\in\mathbb R^{p_q\times d_q} Wi(q)∈Rpq×dq、 W i ( k ) ∈ R p k × d k \mathbf W_i^{(k)}\in\mathbb R^{p_k\times d_k} Wi(k)∈Rpk×dk、 W i ( v ) ∈ R p v × d v \mathbf W_i^{(v)}\in\mathbb R^{p_v\times d_v} Wi(v)∈Rpv×dv、 W o ∈ R p o × h p v \mathbf W_o\in\mathbb R^{p_o\times hp_v} Wo∈Rpo×hpv;
每个头都可能会关注输入的不同部分, 可以表示比简单加权平均值更复杂的函数。
参考
10.5. 多头注意力 — 动手学深度学习 2.0.0-beta1 documentation