1. 训练误差和泛化误差
- 训练误差:模型在训练数据上的误差(比如:模拟高考,可以有很多次)
- 泛化误差:模型在新数据上的误差(比如:真实高考,只有一次)





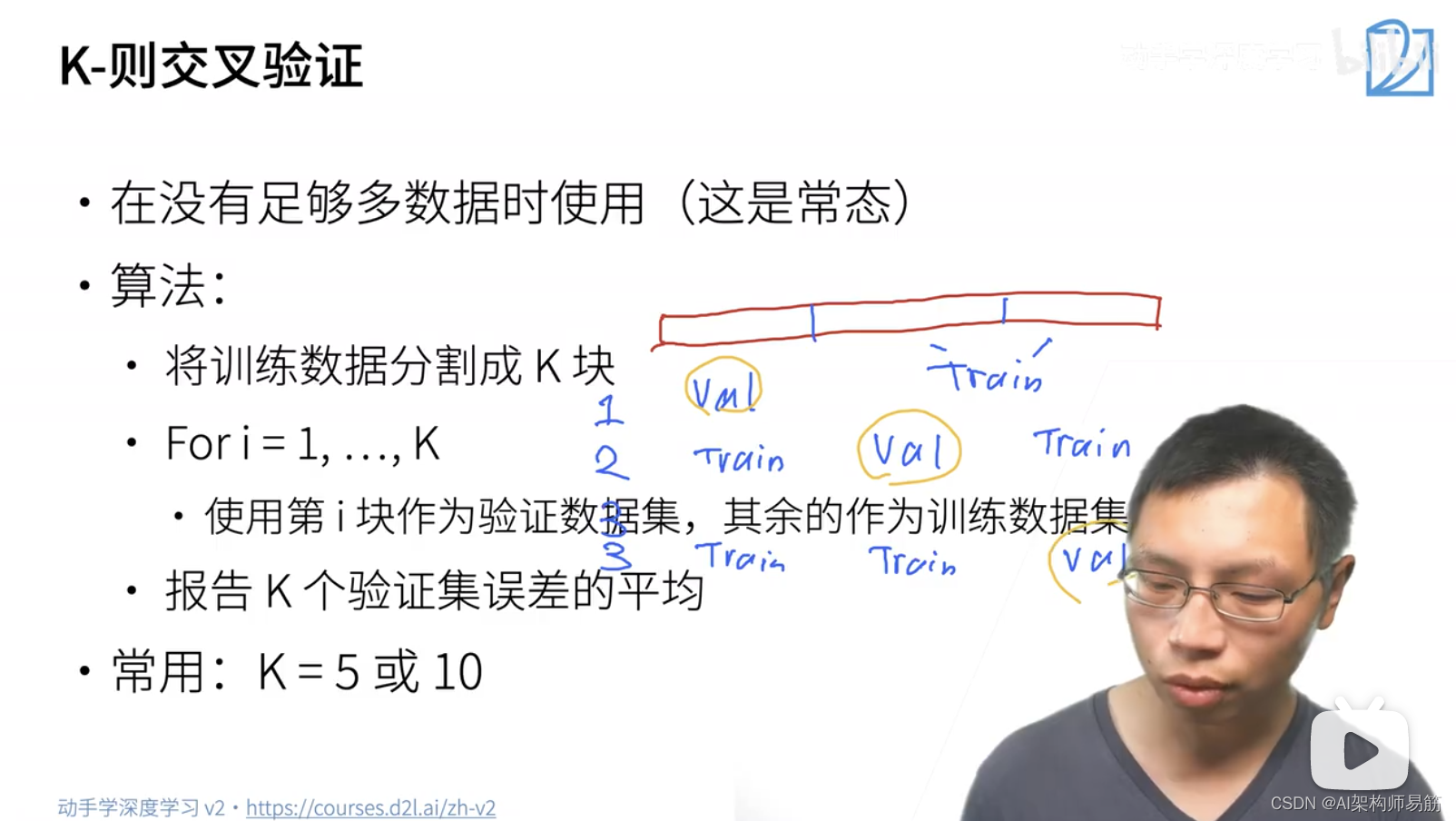
K-则交叉验证

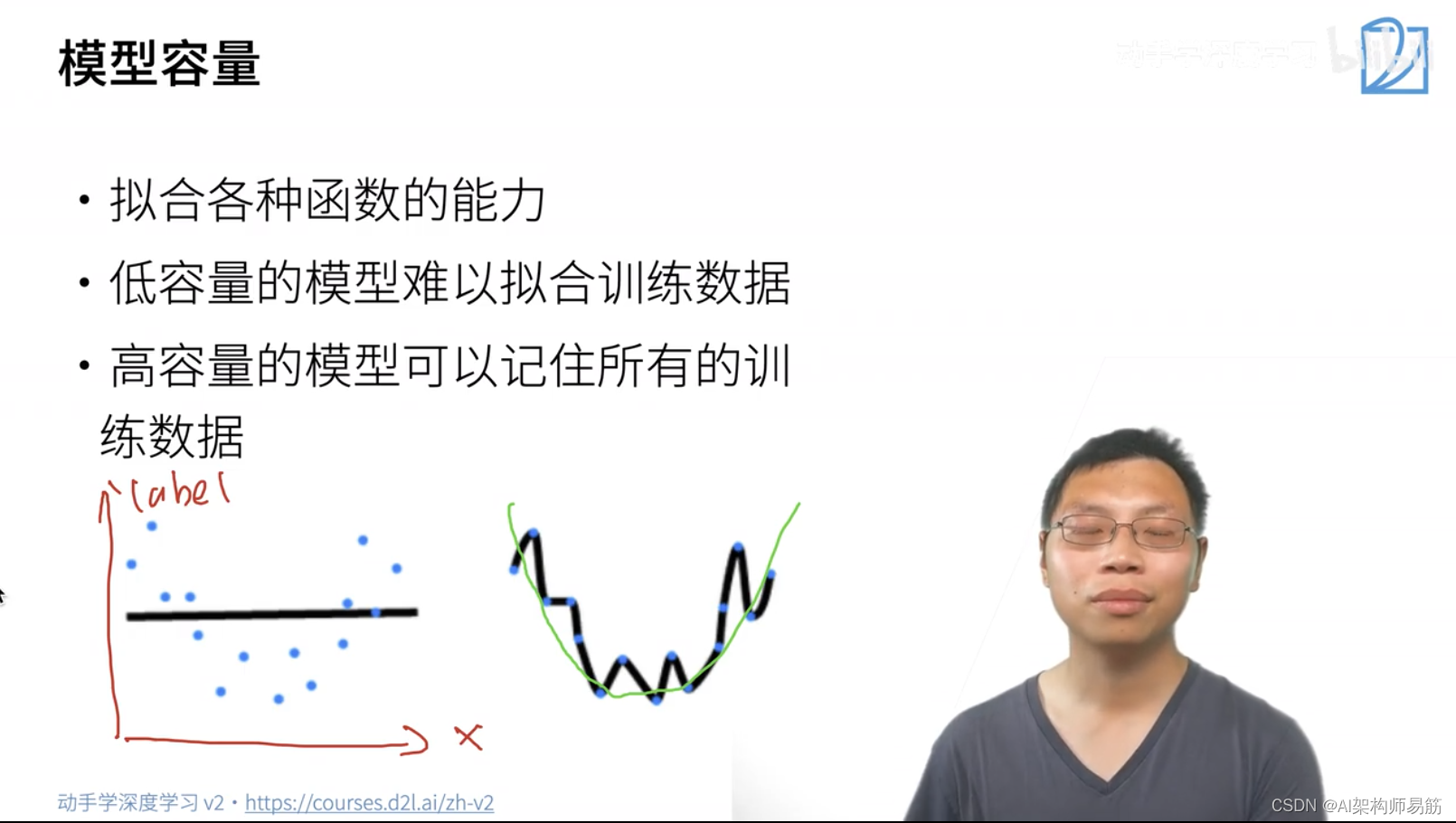
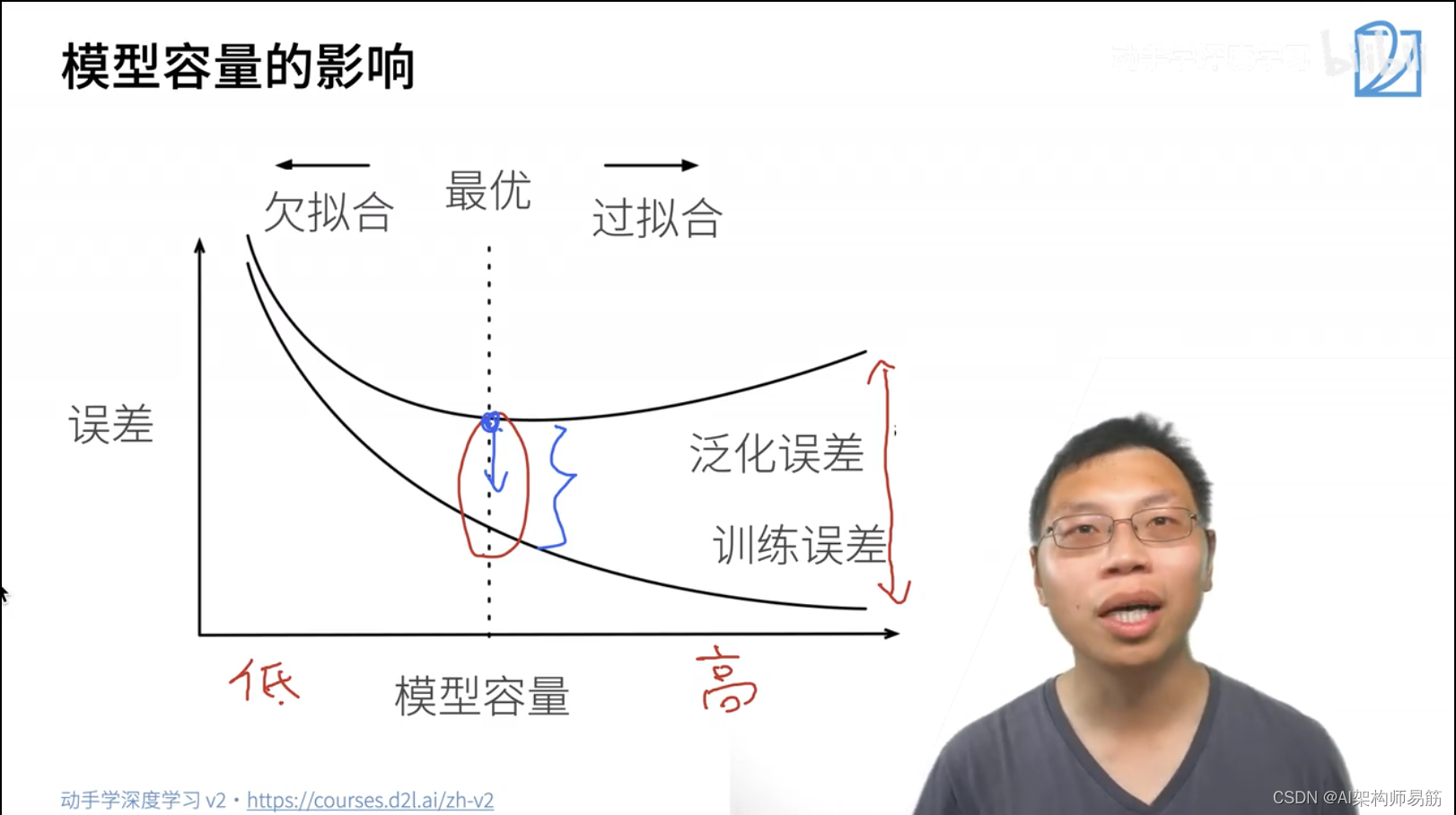
2. 过拟合和欠拟合

模型容量:模型的复杂度
简单数据集:比如线性模型的数据,比如ax+b=y
复杂数据集举例:ImageNet


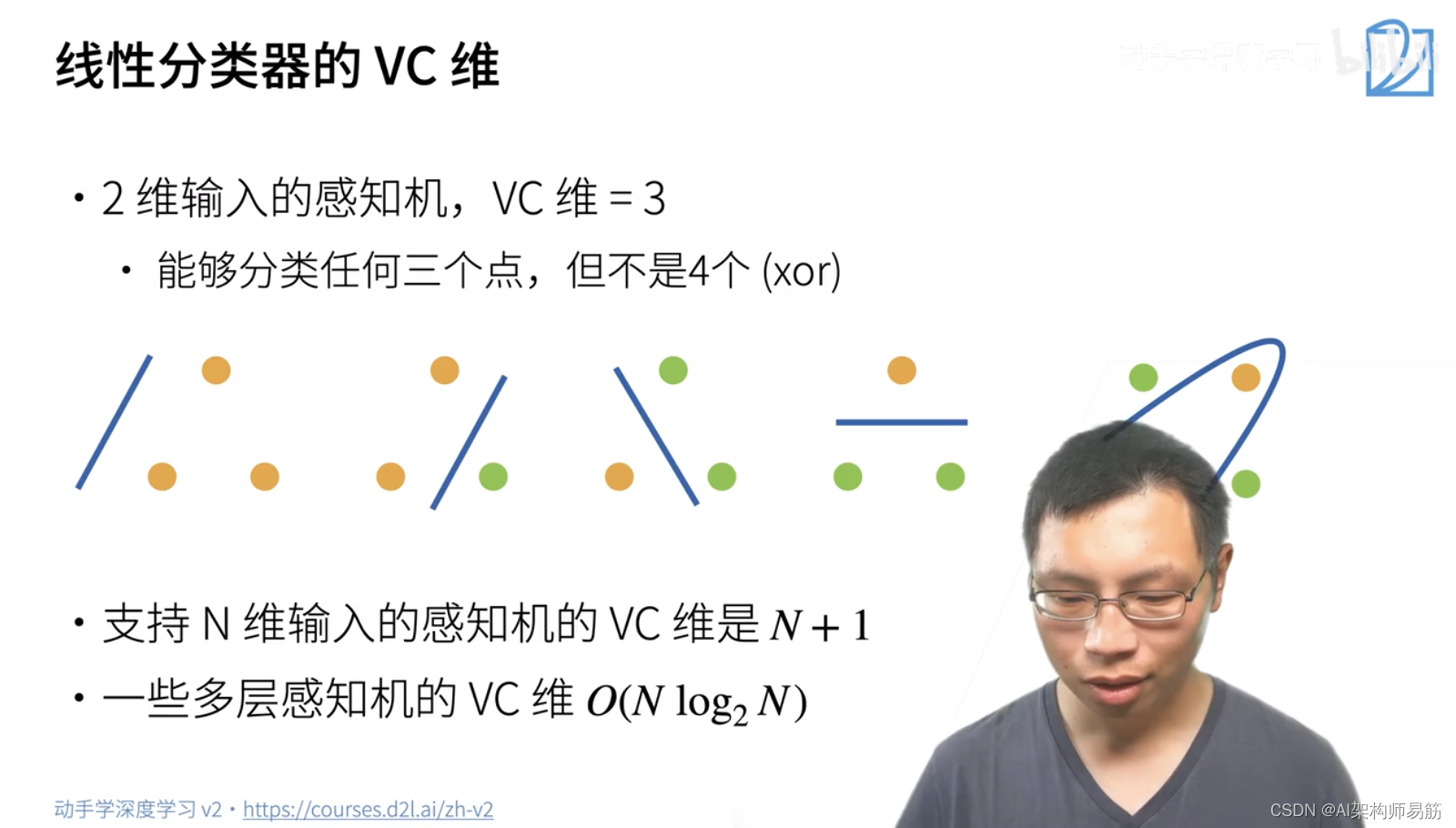
2.1 VC 维
- 统计学习理论的一个核心思想
- 对于一个分类模型,VC等于一个最大的数据集的大小,不管如何给定标号,都存在一个模型来对它进行完美分类。




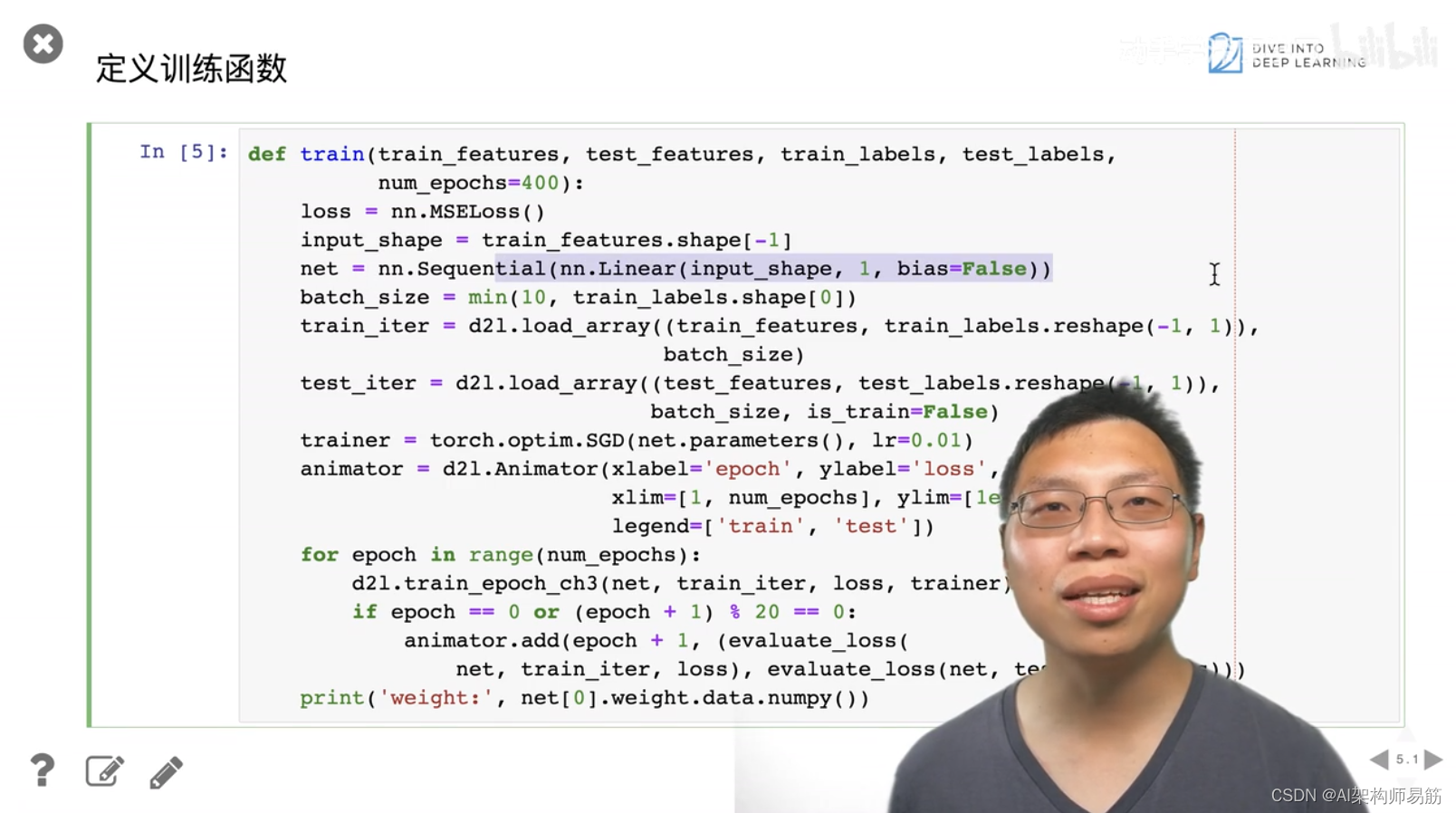
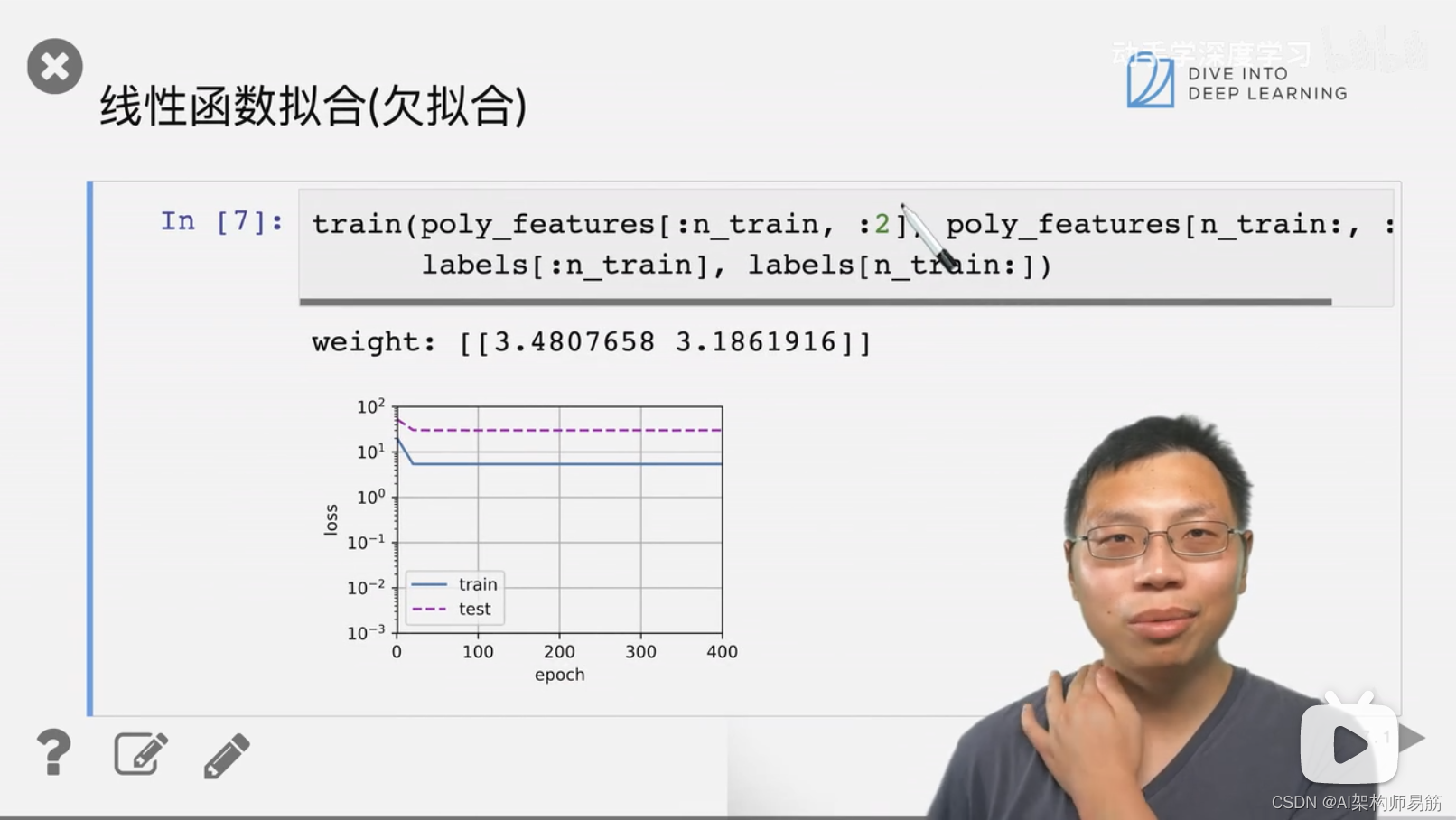
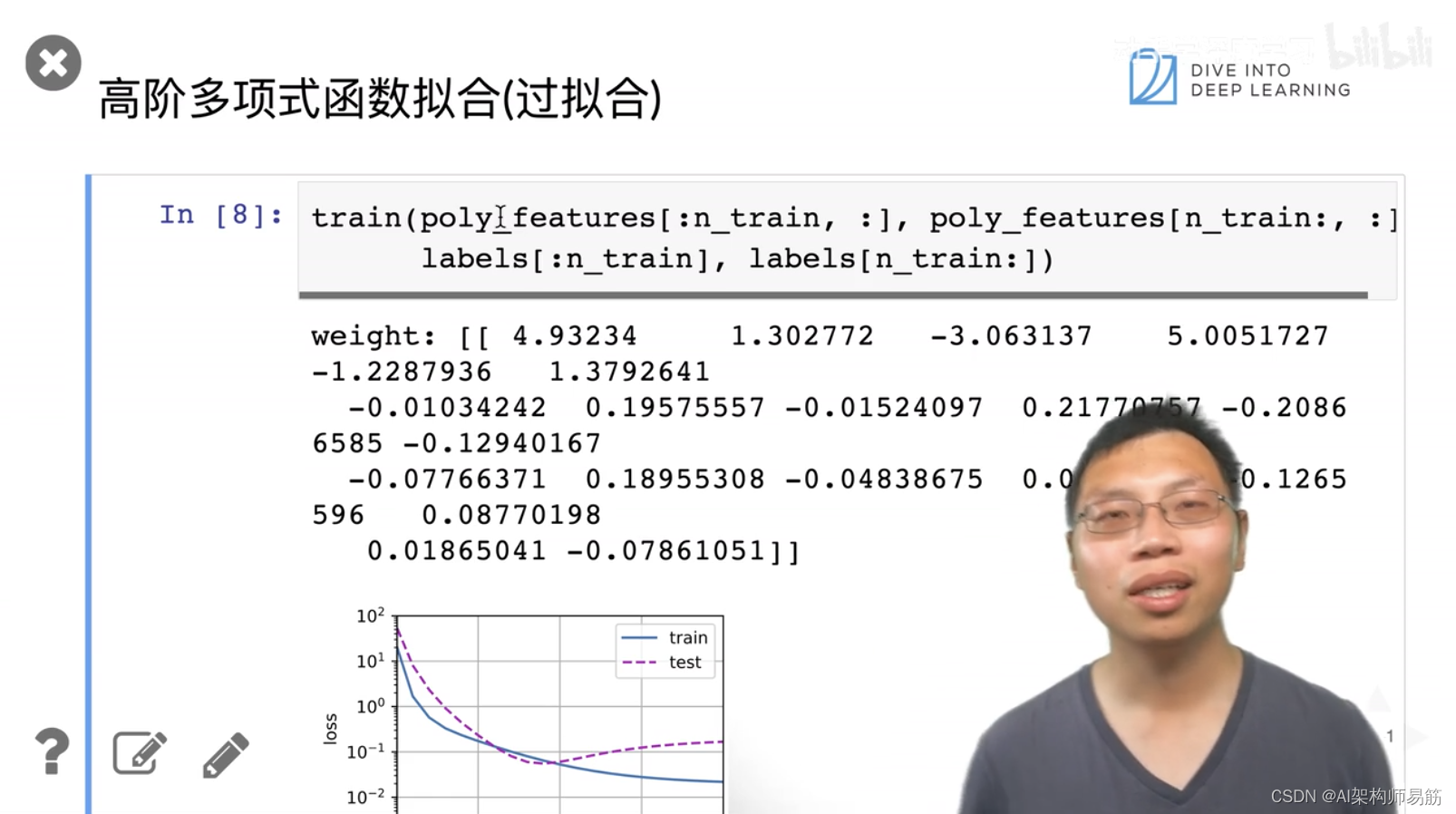
3. 代码样例 过拟合 欠拟合
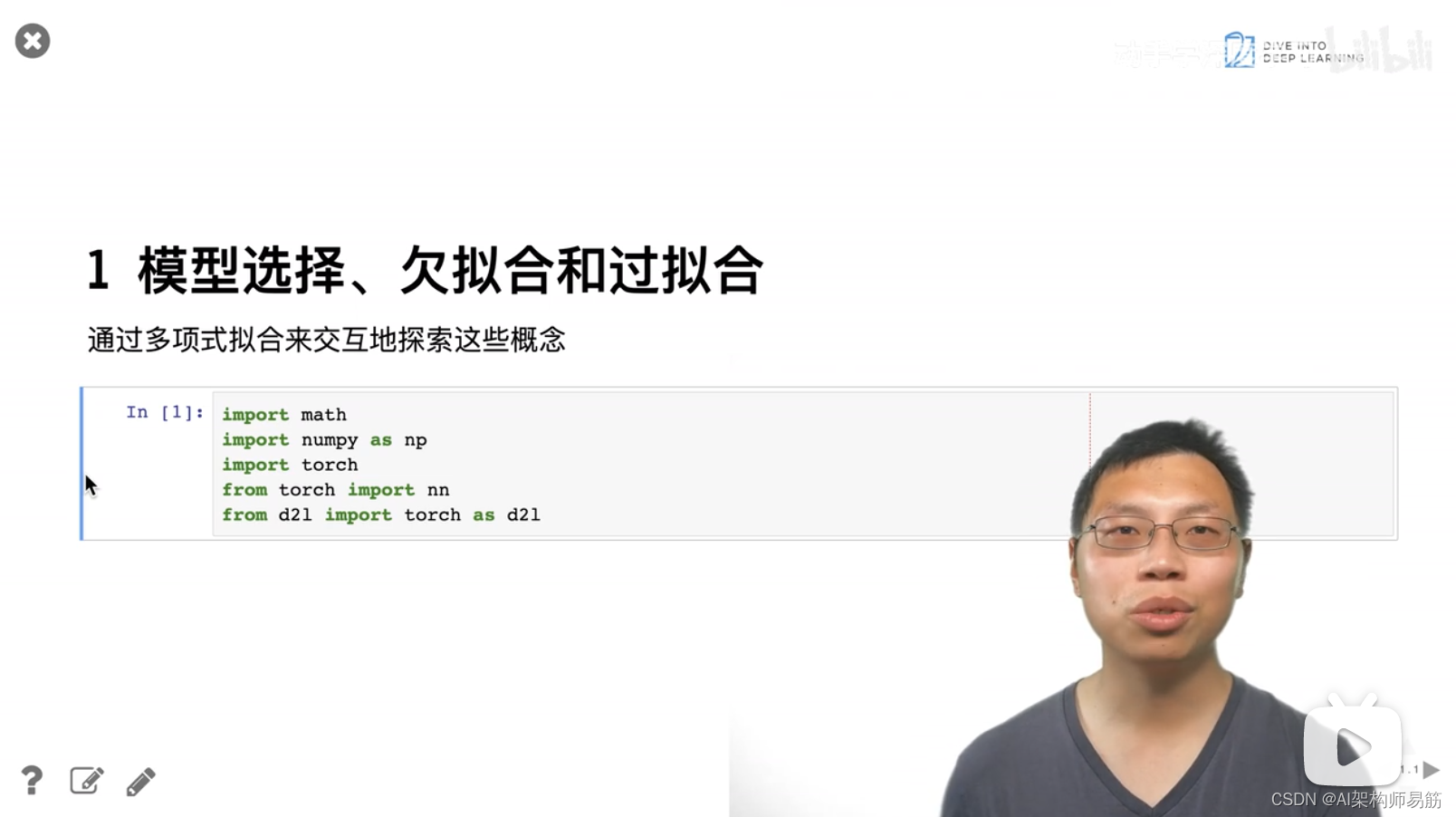
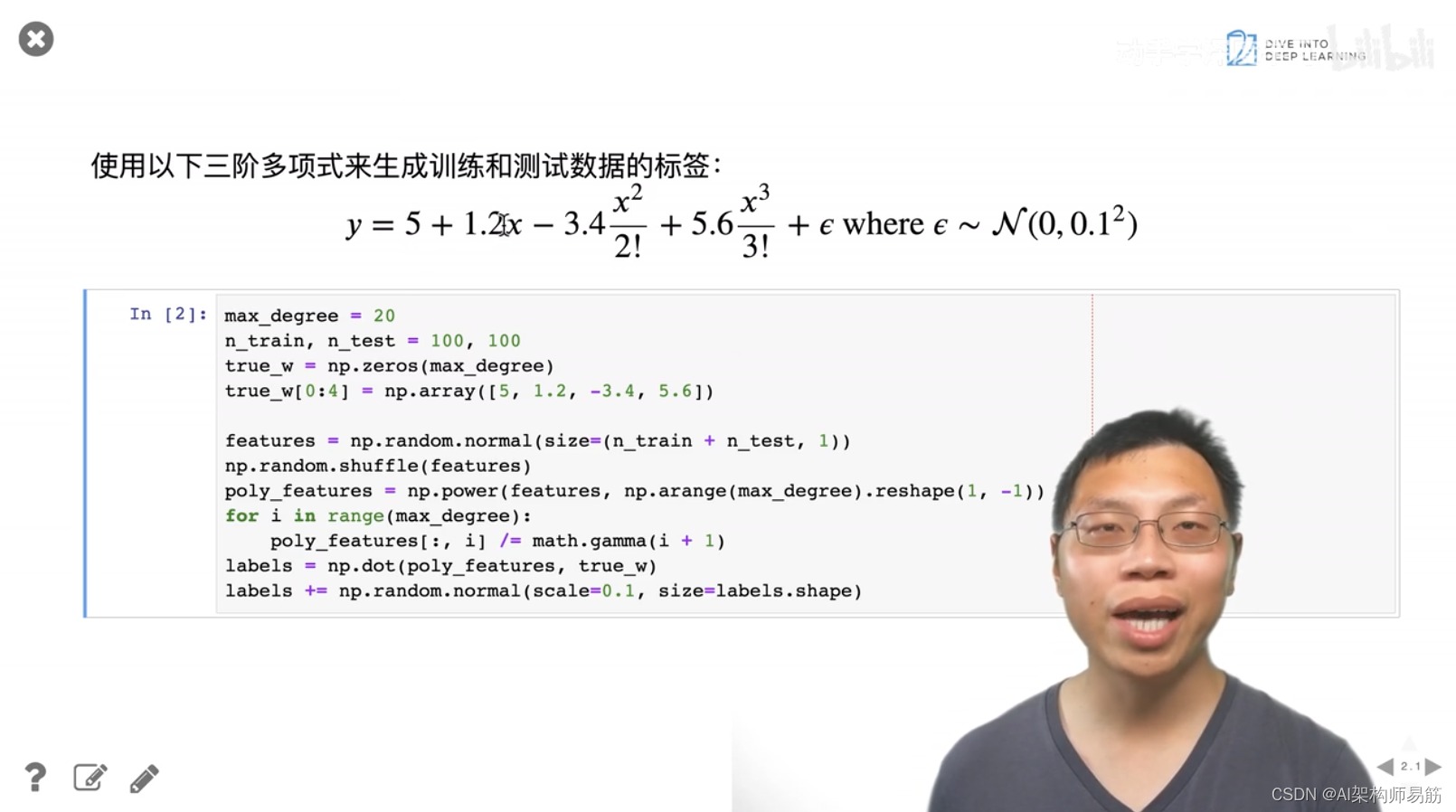
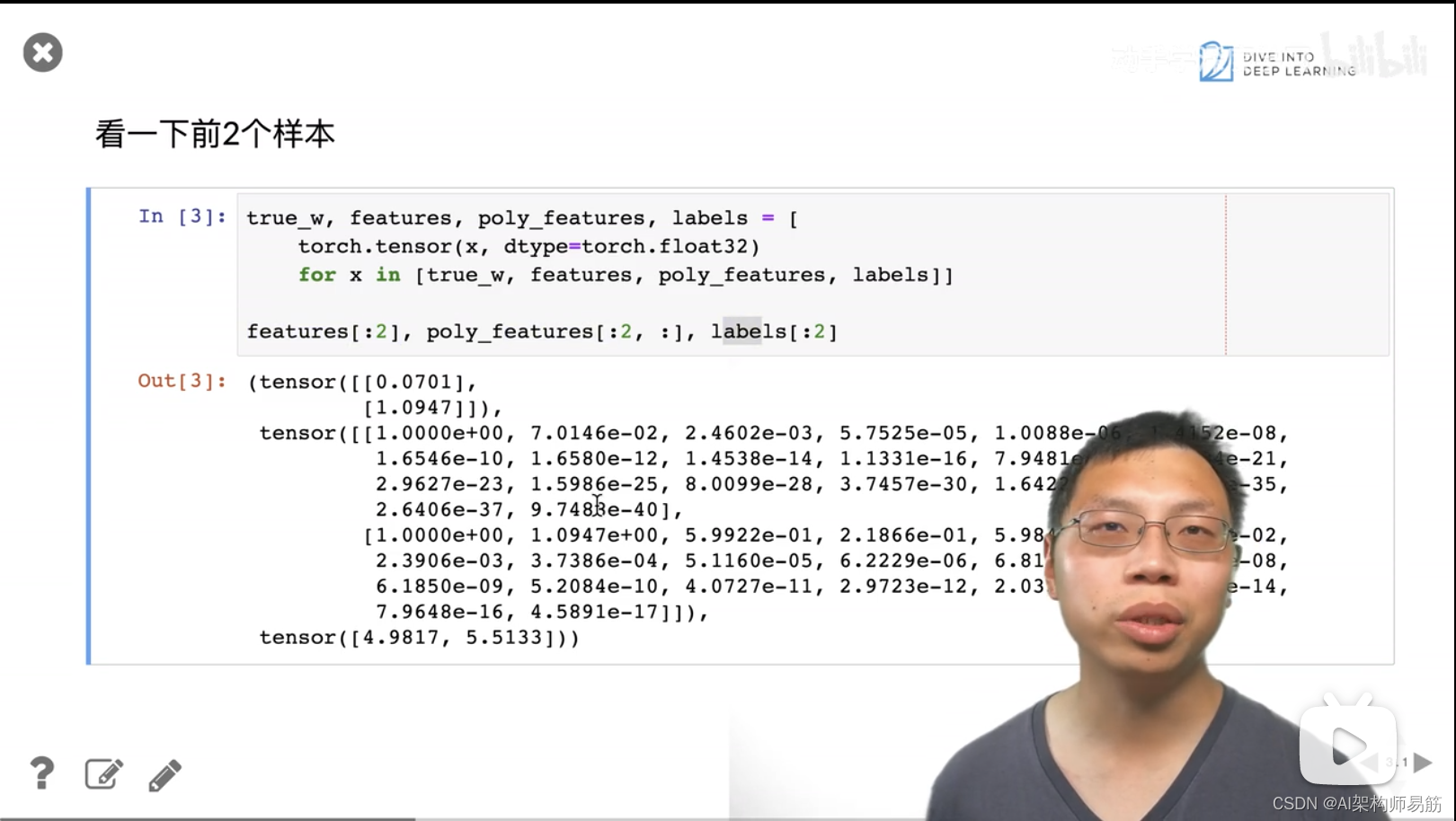
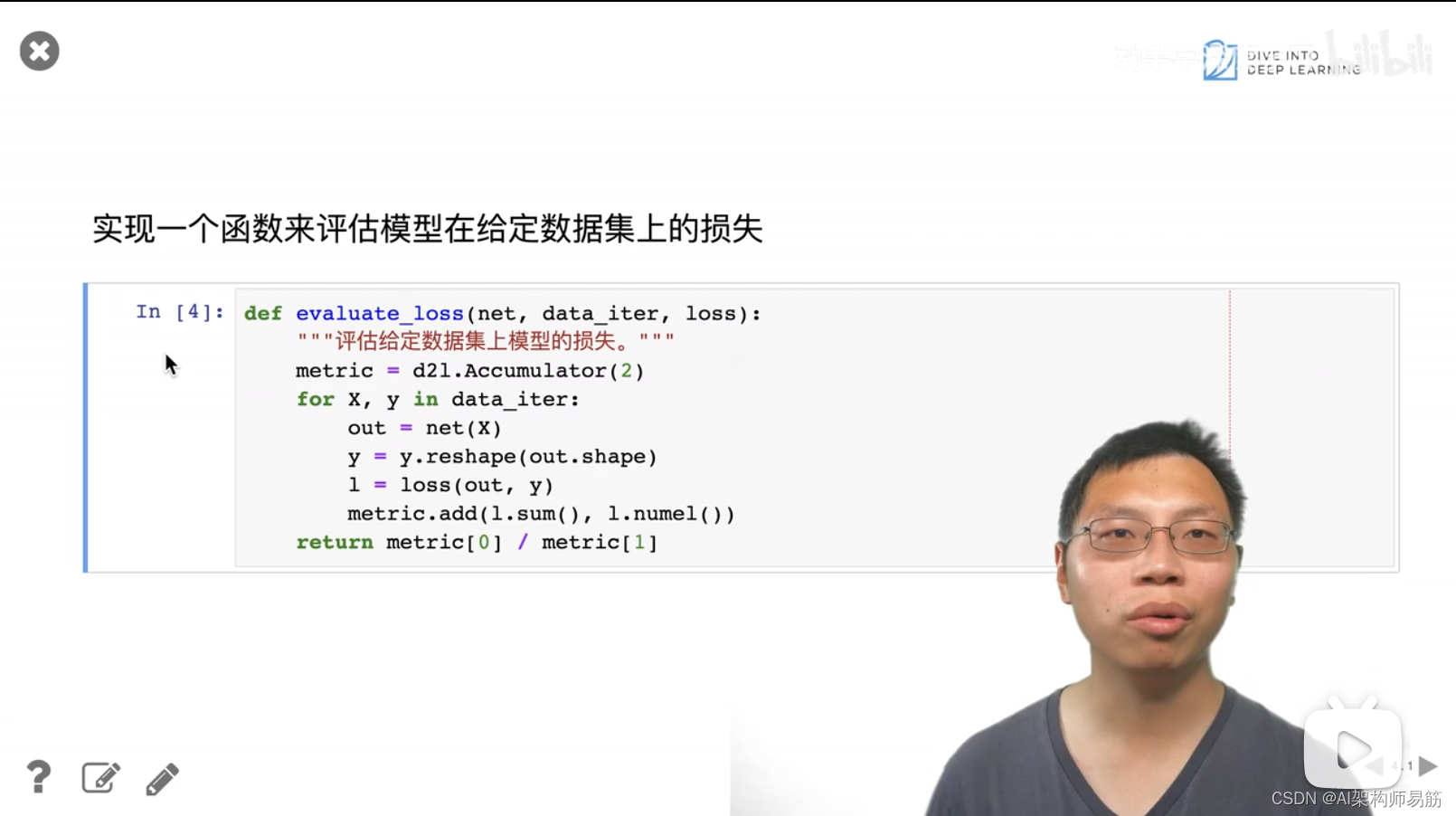

4. QA
- SVM很难训练100万的数据量,SVM可以调的参数很少,特征的分类,提取是分开处理的;神经网络GPT 3 训练的参数都超过1750亿个。神经网络是个语言,可以做很灵活编程。
- k则交叉验证,在神经网络上用的比较少,因为数据集都比较大。k则交叉验证应用于数据比较少的情况,k的选择原则,在于能接受的计算量的情况下。
- 深度学习 打败 svm ,因为效果很好,比如图片识别的精度很高,但是深度学习可解释性不好。svm 打败 多层感知机,因为svm有理论证明,并且容易调参,并且可调参数很少,比较简单。
- VC维衡量模型,简单来说是可以记住的数的维度,比如能备注π的100位小数,就是100VC维。
- 科学、工程、艺术:神经网络有一部分是艺术,可解释性不强,靠猜测。
参考
https://www.bilibili.com/video/BV1kX4y1g7jp?p=1