本文部分转载自:https://zhuanlan.zhihu.com/p/530377846 仅作学习记录~
一、背景
此部分摘自:https://zhuanlan.zhihu.com/p/536642987
各式各样的常用算法就是构建起整个系统的基础,而卡尔曼滤波算法作为贯穿感知、定位、决策和控制整个自动驾驶系统闭环中最常用的算法之一,自然是学习的重中之重。
目标追踪需要用到卡尔曼滤波,多传感器融合需要用到卡尔曼滤波,定位建图需要用到卡尔曼滤波,轨迹跟踪与控制还是会用到卡尔曼滤波。
这一伟大的算法自上世纪六十年代诞生以来已经应用于无数的工程学术项目中,无论你是学控制的、电子的、通信的、计算机的还是车辆、机械的,一定曾经或多或少听说过、学习过这一算法。但是相信你也会和我有一样的感觉,就是老师讲的总是感觉差了那么点意思,总感觉没有深刻理解其精髓。
下面推荐几个补充阅读的链接:
这里引用一下Kent Zeng在知乎上的一个回答,关于通俗解释kalman滤波
假设你有两个传感器,测的是同一个信号。可是它们每次的读数都不太一样,怎么办?
取平均。
再假设你知道其中贵的那个传感器应该准一些,便宜的那个应该差一些。那有比取平均更好的办法吗?
加权平均。
怎么加权?
假设两个传感器的误差都符合正态分布,假设你知道这两个正态分布的方差,用这两个方差值,(此处省略若干数学公式),你可以得到一个“最优”的权重。
接下来,重点来了:假设你只有一个传感器,但是你还有一个数学模型。模型可以帮你算出一个值,但也不是那么准。怎么办?
把模型算出来的值,和传感器测出的值,(就像两个传感器那样),取加权平均。
OK,最后一点说明:你的模型其实只是一个步长的,也就是说,知道x(k),我可以求x(k+1)。
问题是x(k)是多少呢?
答案:x(k)就是你上一步卡尔曼滤波得到的、所谓加权平均之后的那个、对x在k时刻的最佳估计值。于是迭代也有了。这就是卡尔曼滤波。
至于这个权值(卡尔曼增益)怎么计算出来的,搞清楚这个就搞清楚细节了。
下面对上述文字做进一步扩展解释一下:
卡尔曼滤波器是一种最优化递归数据处理算法。开篇标明其实际含义。卡尔曼是发明者的名字,滤波是一种方法,二者结合对于初学者而言并不知道这是一种什么算法,甚至“滤波”二字还会产生干扰和误解,让人误以为这是一种和低通滤波器类似的滤除某一类信号的东西。
而在之前的学习中,“滤波”的含义已经被解释得非常清楚,即滤除的并非某一类信号,而是不确定性。
当我们去描述一个系统的时候,不确定性主要体现在三个方面:
- 不存在完美的数学模型。世界是复杂多变的,人们可以找到数学模型去描述一个系统,但是总是需要各种各样的理想条件,因此没有一个系统能用数学模型完美描述,只是近似程度高与低的差别;
- 系统的扰动不可控也很难建模。例如车辆行驶在路上突遇暴雨,这种扰动如何建模、如何表示?很难;
- 测量传感器存在误差。这也很好理解,传感器就像量物体长度的尺子,用不同的尺子测总会存在不一样的结果。
接下来就通过上面举的尺子的例子来看一下递归算法的实现。我认为这一例子举得是非常巧妙的,通过简单的数学推导让人领悟到卡尔曼滤波思想的精髓。

它的实际意义就是 当前的估计值 等于 上一次的估计值 + 系数 x(当前的测量值-上一次的估计值)
所以卡尔曼滤波只与上一时刻的信息有关,而不需要在全过程记录以往的数据,这就使得其在内存及计算能力有限的嵌入式设备中广为应用。
二、原理的直观解释
我们假设一辆在公路上行驶的汽车,起点位置A,下一秒汽车驶入林荫道中的B点,再下一秒汽车驶出林荫道来到C点。这辆汽车上安装有 IMU(惯性测量单元) 和 GNSS(全球导航卫星系统)两种定位传感器。
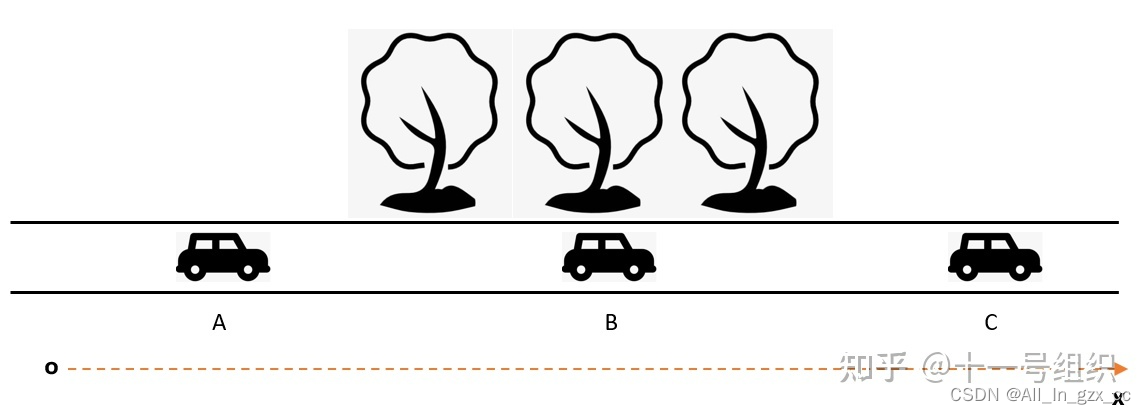
- 起点A的位置和速度假设是已知的,距离惯性坐标系X轴原点的距离为2m,速度为Vt-1。
- 当车辆驶入到B点时,一方面我们可以根据IMU测量得到汽车本体的三轴加速度和三轴角速度,结合初始速度Vt-1,便可以计算得到B点相对于A点在X轴方向行驶距离的 估计值,这里我们假设
估计值为10m。 - 另一方面,通过GNSS我们可以直接测量出来B点的经纬度,通过坐标转换之后可以直接获得B点在X轴方向行驶的 观测值,这里我们假设观测值为13m。
问题来了,距离惯性坐标系点的距离现在有估计值(12m=10m+2m)和观测值(13m)两个值,且两个值不一致,我们该如何确定B点的准确估计值呢?
众所周知,IMU测量汽车本体的加速度和角速度过程中,存在误差和噪声,GNSS通过卫星信号定位车辆经纬度的过程中也存在误差和噪声。两种传感器给出的值都是一种概率最大,意思是在这个位置的概率最大,其它位置不是不可能只是概率较小。而在卡尔曼滤波算法的理论中,无论是汽车上一秒的位置,IMU的测量数据,还是GNSS的直接观测值均被认为服从正态分布。
正态分布是一种概率分布,一般表示为N(均值、方差)。
- 服从正态分布的随机变量取与均值邻近的值的概率大,取与均值越远的值的概率越小。
- 同时方差越小,分布越集中在均值附近,方差越大,分布越分散。
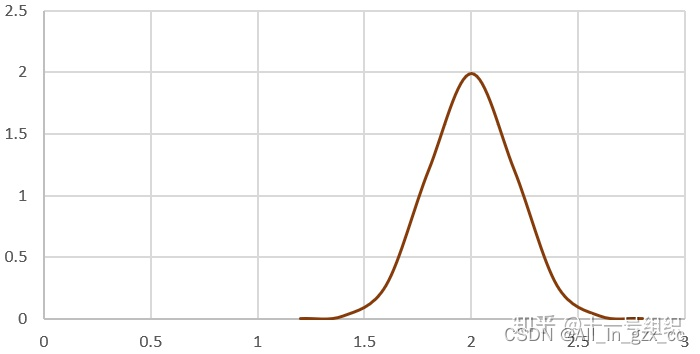
这里我们假设A点位置Xt-1服从N(2, 0.22),如下图所示。从图中可以看出2m处纵坐标最大,概率最大,其它取值概率均小于此处。方差0.22则代表A点位置的误差水平。
而对于IMU和GNSS这两种传感器来说,他们的噪声方差是可以测量的,在使用时是已知的。这里我们省略移动模型建模过程,直接假设
- 基于IMU获得B点相对于A点的距离
估计值XI服从N(10, 0.12) ,方差0.12则代表IMU噪声的误差水平,此误差水平受IMU的精度,测量的累积时长有关。 - GNSS通过卫星信号获得B点相对于原点的
测量值XG服从N(13, 0.42) ,方差0.42代表GNSS噪声的误差水平。此误差水平一方面受GNSS里卫星板卡的精度水平,另一方面主要受所处的环境有关,是否有遮挡,是否多金属环境等。由于B点处于林荫道下,卫星信号时有时无,因此此时0.42的误差水平还是比较高的。
现在我们有了两组数据,
- 一组是B点相对于原点0的
估计值XBOI= XI + XA = N(10, 0.12) + N(2, 0.22) = N(12, 0.12 +0.22), - 一组是B点相对于原点0的
观测值XG= N(13, 0.42)。
全文的高潮点来了,我该如何从两个概率分布中找到最准确的那个估计值呢,可以想象的是这个准确的估计值也遵从正态分布,这个正态分布的均值就是我们苦苦追寻的值。卡尔曼给出的答案是,直接将两个概率分布相乘,即N(12, 0.12 +0.22) * N(13,0.42)。
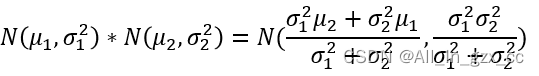
正态分布的乘法公式如上,将N(12, 0.12 +0.22) * N(13,0.42)中的值带入下面公式,则可以得到如下正态分布。
B点准确估计值就是此正态分布的均值12.23m,此准确估计值的误差水平为0.192。0.222/(0.222+0.42)这个参数在卡尔曼滤波算法理论中被称为卡尔曼增益。
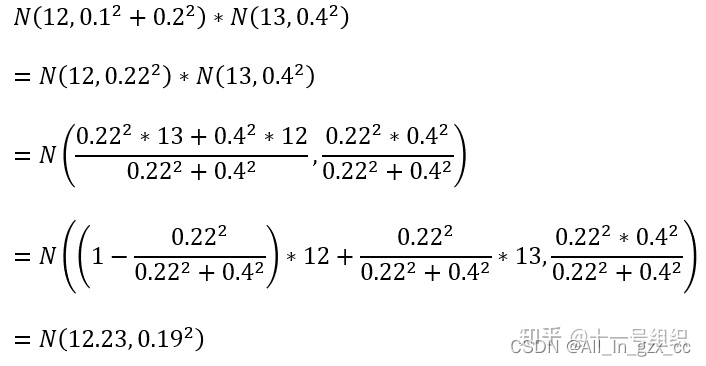
B点的(12.23, 0.192)又将作为计算C点位置的初始值,重复上述过程。
三、算法的理论分析
卡尔曼滤波算法是那种理解起来很难,但用起来非常简单的算法。整个算法只有五个公式,公式的详细推导对于绝大多数人来说没有必要也没有兴趣了解。因此,本段直接给出推导后的预测方程和更新方程,并简单解释变量和方程的含义。
1. 预测方程
xk-1为系统上一时刻状态向量,这个状态向量可以包含任何需要跟踪的信号,且状态向量中的每个变量都服从正态分布。在上文直观理解车辆运动例子中,这个状态变量包含速度和位置。
我们采用预测矩阵F,来刻画上一时刻状态到当前时刻状态的关系。同时考虑到外部因素会带来一些与系统自身状态没有相关性的改变,我们引入外部控制量ut-1及系统参数B。至此,一个考虑了自身和外部因素的状态预测方程便诞生了,如下式所示。

在车辆运动例子中,上一时刻的状态变量中速度和位置变量是存在一定关系的,速度大,运行到当前时刻时,车辆就会行驶得更远。但在其它的系统中,我们可能无法仅凭肉眼就直观的看到变量间的依赖关系,而这也是卡尔曼滤波算法的核心目的,从不确定的系统中,尽可能的挖掘确定的信息。
卡尔曼滤波算法在这里使用的是协方差矩阵Pk-1来衡量上一时刻状态变量中 每个变量的 相关程度。同时将没有跟踪到的噪音干扰当作协方差为Q的噪音来影响,由此我们可以获得当前时刻 考虑外部因素的协方差矩阵,如下式所示。
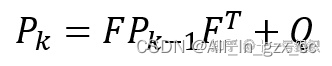
关于协方差矩阵,可以阅读如下blog:
简言之:
- 方差是用来度量单个随机变量的离散程度,
- 协方差则一般用来刻画两个随机变量的相似程度。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。
- 协方差矩阵,只是将所有变量的协方差关系用矩阵的形式表现出来而已。通过矩阵这一工具,可以更方便地进行数学运算。
2. 更新方程
通过上文的预测过程,我们对系统当前时刻的状态有了一个模糊的估计。
与此同时,我们也将通过传感器测量到当前时刻系统状态的观测值zk及其测量的不确定性R。
对于测量量,我们还需要一个变换矩阵H,来将 系统真实状态空间 映射成 观测空间。随后再经过艰苦卓绝的推导便可以得到如下的状态更新方程组。
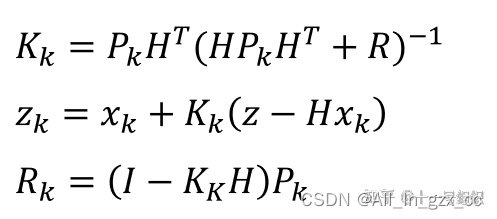
三、应用
卡尔曼滤波算法在自动驾驶的经典应用之一就是融合定位。L4/L5自动驾驶系统基本标配GNSS和IMU。GNSS定位数据更新频率低(典型10Hz),有遮挡或多径影响下,输出的定位数据不可靠。IMU定位数据更新频率高(典型150Hz),但是内部积分运算会随着时间的推移,产生较大的累计误差。
而为了获得全局准确的定位数据,各家利用GNSS可靠的定位数据来对IMU进行校准,消除IMU的累计误差。同时在GNSS定位不可靠时,利用IMU自身推算结果优化GNSS定位不可靠的数据。而从GNSS/IMU的不确定信息中获得更多确定性信息的手段就是利用的卡尔曼滤波算法。
而在障碍物追踪和预测方面,卡尔曼滤波算法广泛被用于通过融合激光雷达和毫米波雷达的数据,估计障碍物的位置和速度。
而在车道线追踪和预测方面,卡尔曼滤波算法可以通过对当前图像的预测来估计下一时刻车道线的位置,并且能识别判断出车道线的走向(左转或右转),提取有效的道路信息进行车道线的跟踪。