文章目录
参考资料
文章大部分内容主要来自参考资料,旨在于更方便学习记忆查找,不作其他用途。
在上一篇整理总结了扩展卡尔曼滤波。扩展卡尔曼滤波通过一阶泰勒展开得到近似的线性状态转移矩阵与观测矩阵。EKF的一个最大的问题就是求解雅可比矩阵计算量比较大,因此这里再介绍另一种可用于非线性系统的卡尔曼滤波——无迹卡尔曼滤波(Unscented Kalman Filter,UKF)。
1. 无迹变换
在应用KF时面临的主要问题就是非线性过程模型和观测模型的处理。
对于我们想要估计的状态,在k时刻满足均值为 x k ∣ k x_{k|k} xk∣k,方差为 P k ∣ k P_{k|k} Pk∣k的一个高斯分布,KF能够使用的前提就是所处理的状态是满足高斯分布的,对于非线性的情况下,EKF是寻找一个线性函数来近似这个非线性函数,而UKF就是去找一个与真实分布近似的高斯分布。
UKF的基本思路就是: 近似非线性函数的概率分布要比近似非线性函数本身要容易
如何去找一个与真实分布近似的高斯分布呢?——找一个与真实分布有着相同的均值和协方差的高斯分布。
如何去找这样的均值和方差呢?——无迹变换。
1.1 无迹变换基本概念
无迹变换的核心理念:
- 近似概率分布比近似任意的非线性函数或变换要相对容易。
无迹变换要解决的问题是:已知某随机变量(多维情形下是随机向量)的概率分布(均值和方差),求其经过某非线性函数 g ( ⋅ ) g(⋅) g(⋅)变换后的概率分布。
基于上述思想,无迹变换的主要步骤为:
-
根据某种规则对随机变量的概率分布进行确定性采样,并为采样点分配权重(均值权重和方差权重),采样点我们通常称之为
sigma点; -
将每一个
sigma点进行非线性变换,得到新的sigma点; -
对非线性变换后的新的
sigma点进行加权求和,分别计算加权均值和加权方差,用加权均值和加权方差近似表征随机变量经非线性变换后的概率分布。
无迹变换主要包括两种形式:一般形式的无迹变换和比例无迹变换。两种无迹变换的区别主要体现在采样规则和权重计算上。比例无迹变换是对前者做出的改进。
1.2 一般形式的无迹变换
假设存在 n n n维随机向量 X X X,其服从均值 μ x \mu_x μx 和协方差 Σ x \Sigma_x Σx的正态分布:
X ∼ N ( μ x , Σ x ) X \sim \mathcal{N}\left(\mu_{x}, \Sigma_{x}\right) X∼N(μx,Σx)
将 X X X 经过非线性函数 g ( ⋅ ) g(⋅) g(⋅) 进行变换,得到随机向量 Y Y Y,我们使用一般形式的无迹变换估计 Y Y Y 的概率分布。一般形式的无迹变换最早由 Julier 等人提出,其主要操作流程如下所述:
-
步骤一:参数选择与权重计算
一般形式的无迹变换只涉及一个外部引入参数 κ \kappa κ,各
sigma点(共 2 n + 1 2n+1 2n+1 个)的权重分配如下:
W ( i ) = { κ n + κ i = 0 1 2 ( n + κ ) i = 1 , ⋯ , 2 n W^{(i)}= \begin{cases}\frac{\kappa}{n+\kappa} & i=0 \\ \frac{1}{2(n+\kappa)} & i=1, \cdots, 2 n\end{cases} W(i)={ n+κκ2(n+κ)1i=0i=1,⋯,2n其中, κ ∈ R \kappa \in \mathbb{R} κ∈R, 表征了
sigma点相对均值的散布程度, κ \kappa κ 越大,非均值处的sigma点距离均值越远,且所占权重越小, 而均值处 sigma 点所占权重则相对越 大。对于高斯问题, n + κ = 3 n+\kappa=3 n+κ=3 是一个比较好的选择,对于非高斯问题(无迹变换也适用于非高斯问题), κ \kappa κ 应该选择其它更恰当的值。 -
步骤二:确定性采样
通常情况下,
sigma点位于均值处及对称分布于主轴的协方差处(每维两个)。按照如下方法采样得到 2 n + 1 2 n+1 2n+1 个sigma点, 构成 n × ( 2 n + 1 ) n \times(2 n+1) n×(2n+1) 的点集矩阵 X \mathcal{X} X :
X ( i ) = { μ x i = 0 μ x + ( ( n + κ ) Σ x ) ( i − 1 ) i = 1 , ⋯ , n μ x − ( ( n + κ ) Σ x ) ( i − n − 1 ) i = n + 1 , ⋯ , 2 n \mathcal{X}^{(i)}= \begin{cases}\mu_{x} & i=0 \\ \mu_{x}+\left(\sqrt{(n+\kappa) \Sigma_{x}}\right)^{(i-1)} & i=1, \cdots, n \\ \mu_{x}-\left(\sqrt{(n+\kappa) \Sigma_{x}}\right)^{(i-n-1)} & i=n+1, \cdots, 2 n\end{cases} X(i)=⎩⎪⎪⎪⎨⎪⎪⎪⎧μxμx+((n+κ)Σx)(i−1)μx−((n+κ)Σx)(i−n−1)i=0i=1,⋯,ni=n+1,⋯,2n
其中, ( ( n + κ ) Σ x ) ( i − 1 ) \left(\sqrt{(n+\kappa) \Sigma_{x}}\right)^{(i-1)} ((n+κ)Σx)(i−1) 表示矩阵 ( n + κ ) Σ x (n+\kappa) \Sigma_{x} (n+κ)Σx 作 Cholesky分解后下三角矩阵的第 i − 1 i-1 i−1 列, ( ( n + κ ) Σ x ) ( i − n − 1 ) \left(\sqrt{(n+\kappa) \Sigma_{x}}\right)^{(i-n-1)} ((n+κ)Σx)(i−n−1) 同理。Cholesky分解
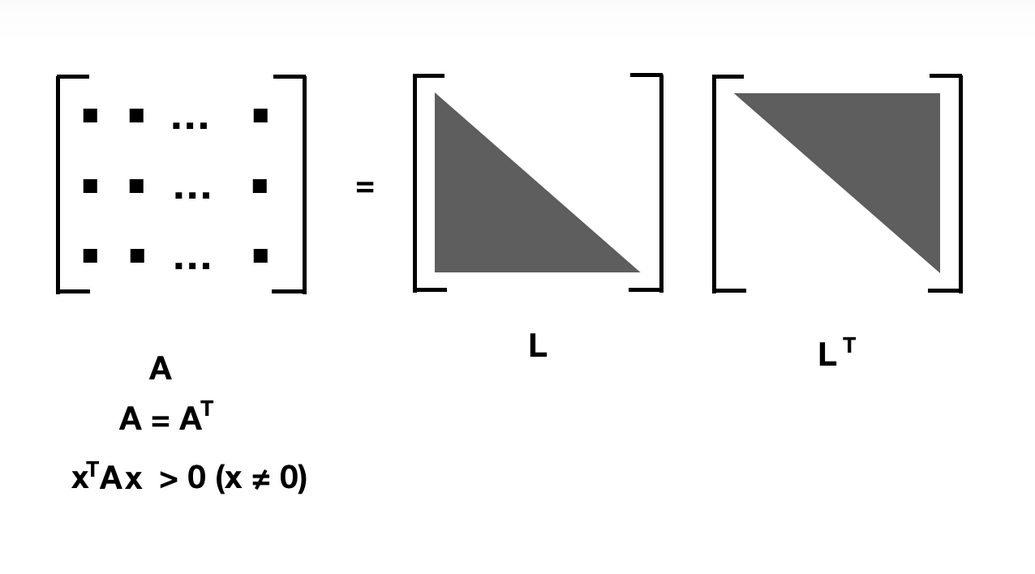
当 A 是一个 Symmetric positive definite matrix的时候,就可以分解成 lower triangle 矩阵 L 和它的转置也就是 upper triangle -
步骤三:
sigma点非线性变换将每个
sigma点(即 X \mathcal{X} X 的每一列)进行 g ( ⋅ ) g(\cdot) g(⋅) 的非线性变换,得到变换后的新的点集矩阵 Y \mathcal{Y} Y :
Y ( i ) = g ( X ( i ) ) i = 0 , ⋯ , 2 n \mathcal{Y}^{(i)}=g\left(\mathcal{X}^{(i)}\right) \quad i=0, \cdots, 2 n Y(i)=g(X(i))i=0,⋯,2n -
步骤四:加权计算近似均值与近似协方差
μ y = ∑ i = 0 i = 2 n W ( i ) Y ( i ) Σ y = ∑ i = 0 i = 2 n W ( i ) [ Y ( i ) − μ y ] [ Y ( i ) − μ y ] T \begin{gathered} \mu_{y}=\sum_{i=0}^{i=2 n} W^{(i)} \mathcal{Y}^{(i)} \\ \Sigma_{y}=\sum_{i=0}^{i=2 n} W^{(i)}\left[\mathcal{Y}^{(i)}-\mu_{y}\right]\left[\mathcal{Y}^{(i)}-\mu_{y}\right]^{T} \end{gathered} μy=i=0∑i=2nW(i)Y(i)Σy=i=0∑i=2nW(i)[Y(i)−μy][Y(i)−μy]T
1.3 比例无迹变换
当参数 κ < 0 \kappa<0 κ<0 时, 权重 W ( 0 ) = κ n + κ < 0 W^{(0)}=\frac{\kappa}{n+\kappa}<0 W(0)=n+κκ<0, 加权算得 的近似协方差可能存在非半正定的情况。为应对该问题, Julier 等人后来提出无迹变换的改进形式一一比例无迹变换,并由 Merwe 等人对其进行了简化。
比例无迹变换与一般形 式的无迹变换的主要区别体现在参数选取与 sigma 点权重计算上,其主要操作流程如下所述:
-
步骤一:参数选择与权重计算
比例无迹变换引入了四个外部参数: α 、 β 、 κ \alpha 、 \beta 、 \kappa α、β、κ 和 λ \lambda λ, 各 sigma 点 ( 2 n + 1 (2 n+1 (2n+1 个 ) ) ) 的权重 分配如下:
W m ( i ) = { λ n + λ i = 0 1 2 ( n + λ ) i = 1 , ⋯ , 2 n W c ( i ) = { λ n + λ + 1 − α 2 + β i = 0 1 2 ( n + λ ) i = 1 , ⋯ , 2 n \begin{gathered} W_{m}^{(i)}= \begin{cases}\frac{\lambda}{n+\lambda} & i=0 \\ \frac{1}{2(n+\lambda)} & i=1, \cdots, 2 n\end{cases} \\ W_{c}^{(i)}= \begin{cases}\frac{\lambda}{n+\lambda}+1-\alpha^{2}+\beta & i=0 \\ \frac{1}{2(n+\lambda)} & i=1, \cdots, 2 n\end{cases} \end{gathered} Wm(i)={ n+λλ2(n+λ)1i=0i=1,⋯,2nWc(i)={ n+λλ+1−α2+β2(n+λ)1i=0i=1,⋯,2n
其中, W m ( i ) W_{m}^{(i)} Wm(i) 表示计算近似均值时 sigma 点的权重, W c ( i ) W_{c}^{(i)} Wc(i) 表示计算近似协方差时 sigma 点的权重。参数 λ \lambda λ 满足:
λ = α 2 ( n + κ ) − n \lambda=\alpha^{2}(n+\kappa)-n λ=α2(n+κ)−n参数 β \beta β用于引入随机变量概率分布的高阶矩信息,如果分布是精确的高斯分布,则 β = 2 \beta=2 β=2 是最优选择。
参数 α \alpha α 和 κ \kappa κ 为确定
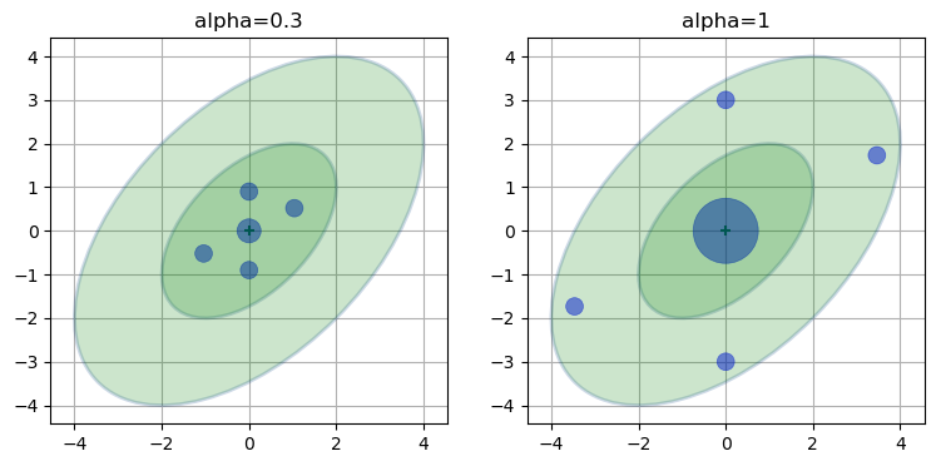
sigma点分布在均值多远的范围内的比例参数。 α \alpha α 满足 1 0 − 4 ≤ α ≤ 1 10^{-4} \leq \alpha \leq 1 10−4≤α≤1, 为避免强非线性系统中的非局部效应问题, α \alpha α 通常取一个较小值; κ \kappa κ 满 足 κ ≥ 0 \kappa \geq 0 κ≥0 ,通常取 κ = 3 − n \kappa=3-n κ=3−n 或 κ = 0 \kappa=0 κ=0 。下图呈现了当 α \alpha α 取值分别为 0.3 0.3 0.3 和 1 时,
sigma点的分布情况,从图中可以发现, α \alpha α 取值越大,非均值处的 sigma 点距离均值越远。
-
步骤三:
sigma点非线性变换将每个 sigma 点(即 X \mathcal{X} X 的每一列)进行 g ( ⋅ ) g(\cdot) g(⋅) 的非线性变换, 得到变换后的新的点集矩 阵 Y \mathcal{Y} Y :
Y ( i ) = g ( X ( i ) ) i = 0 , ⋯ , 2 n \mathcal{Y}^{(i)}=g\left(\mathcal{X}^{(i)}\right) \quad i=0, \cdots, 2 n Y(i)=g(X(i))i=0,⋯,2n -
步骤四:加权计算近似均值与近似协方差
μ y = ∑ i = 0 i = 2 n W m ( i ) Y ( i ) Σ y = ∑ i = 0 i = 2 n W c ( i ) [ Y ( i ) − μ y ] [ Y ( i ) − μ y ] T \begin{gathered} \mu_{y}=\sum_{i=0}^{i=2 n} W_{m}^{(i)} \mathcal{Y}^{(i)} \\ \Sigma_{y}=\sum_{i=0}^{i=2 n} W_{c}^{(i)}\left[\mathcal{Y}^{(i)}-\mu_{y}\right]\left[\mathcal{Y}^{(i)}-\mu_{y}\right]^{T} \end{gathered} μy=i=0∑i=2nWm(i)Y(i)Σy=i=0∑i=2nWc(i)[Y(i)−μy][Y(i)−μy]T
2. 无迹卡尔曼滤波
只介绍可加性噪声条件下的无迹卡尔曼滤波算法。
UKF同样也分为预测和更新。
假设系统的状态方程和观测方程为:
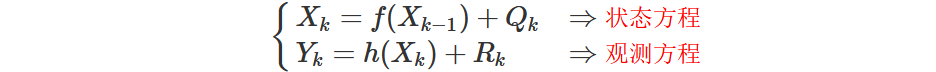 从上式中我们可以发现, 过程噪声 Q k Q_{k} Qk 和观测噪声 R k R_{k} Rk 是以线性可加项的形式存在于系统状态方程和观测方程中的,这种形式的表述基于这样的前提假设:过程噪声 Q k Q_{k} Qk 对系统状态转移过程的影响是线性的,观测噪声 R k R_{k} Rk 对系统观测过程的影响也是线性的。很明显, 此种情况下, Q k Q_{k} Qk 与 X k X_{k} Xk 是同维的, R k R_{k} Rk 与 Y k Y_{k} Yk 是同维的。
从上式中我们可以发现, 过程噪声 Q k Q_{k} Qk 和观测噪声 R k R_{k} Rk 是以线性可加项的形式存在于系统状态方程和观测方程中的,这种形式的表述基于这样的前提假设:过程噪声 Q k Q_{k} Qk 对系统状态转移过程的影响是线性的,观测噪声 R k R_{k} Rk 对系统观测过程的影响也是线性的。很明显, 此种情况下, Q k Q_{k} Qk 与 X k X_{k} Xk 是同维的, R k R_{k} Rk 与 Y k Y_{k} Yk 是同维的。
假设有如下已知条件:

基于以上已知条件与符号定义,我们总结一下可加性噪声条件下的无迹卡尔曼滤波算法步骤(使用比例无迹变换)。
2.1 初始化
-
选定滤波初值
根据观测量初值 z 0 z_{0} z0 及观测函数 h ( ⋅ ) h(\cdot) h(⋅) 计算对应的状态量初始均值 μ X 0 + \mu_{X_{0}}^{+} μX0+, 设定状态量协方差 初值 Σ X 0 。 + \Sigma_{X_{0} \text { 。 }}^{+} ΣX0 。 + -
选定无迹变换参数
设定比例无迹变换参数 α 、 β 、 κ \alpha 、 \beta 、 \kappa α、β、κ 和 λ \lambda λ 的参数值, 若使用一般形式的无迹变换, 仅需设定 κ \kappa κ 的取值。 -
sigma 点权重计算
根据无迹变换参数取值及权重计算公式计算各 sigma 点权重。
W m ( i ) = { λ n + λ i = 0 1 2 ( n + λ ) i = 1 , ⋯ , 2 n W c ( i ) = { λ n + λ + 1 − α 2 + β i = 0 1 2 ( n + λ ) i = 1 , ⋯ , 2 n \begin{gathered} W_{m}^{(i)}= \begin{cases}\frac{\lambda}{n+\lambda} & i=0 \\ \frac{1}{2(n+\lambda)} & i=1, \cdots, 2 n\end{cases} \\ W_{c}^{(i)}= \begin{cases}\frac{\lambda}{n+\lambda}+1-\alpha^{2}+\beta & i=0 \\ \frac{1}{2(n+\lambda)} & i=1, \cdots, 2 n\end{cases} \end{gathered} Wm(i)={ n+λλ2(n+λ)1i=0i=1,⋯,2nWc(i)={ n+λλ+1−α2+β2(n+λ)1i=0i=1,⋯,2n
对 k = 1 , 2 , 3 , ⋯ k=1,2,3, \cdots k=1,2,3,⋯, 执行——
2.2 sigma采样
对 k − 1 k-1 k−1 时刻状态量 X k − 1 X_{k-1} Xk−1 的后验概率分布进行 sigma 采样
X k − 1 + ( i ) = { μ X k − 1 + i = 0 μ X k − 1 + + γ ( Σ X k − 1 + ) ( i − 1 ) i = 1 , ⋯ , n μ X k − 1 + − γ ( Σ X k − 1 + ) ( i − n − 1 ) i = n + 1 , ⋯ , 2 n \mathcal{X}_{k-1}^{+(i)}= \begin{cases}\mu_{X_{k-1}}^{+} & i=0 \\ \mu_{X_{k-1}}^{+}+\gamma\left(\sqrt{\Sigma_{X_{k-1}}^{+}}\right)^{(i-1)} & i=1, \cdots, n \\ \mu_{X_{k-1}}^{+}-\gamma\left(\sqrt{\Sigma_{X_{k-1}}^{+}}\right)^{(i-n-1)} & i=n+1, \cdots, 2 n\end{cases} Xk−1+(i)=⎩⎪⎪⎪⎨⎪⎪⎪⎧μXk−1+μXk−1++γ(ΣXk−1+)(i−1)μXk−1+−γ(ΣXk−1+)(i−n−1)i=0i=1,⋯,ni=n+1,⋯,2n
其中, γ = ( n + λ ) \gamma=\sqrt{(n+\lambda)} γ=(n+λ) 。
2.3 预测步
1. 状态转移非线性变换
X k − ∗ ( i ) = f ( X k − 1 + ( i ) , u k ) , i = 0 , 1 , 2 , ⋯ , 2 n \mathcal{X}_{k}^{-*(i)}=f\left(\mathcal{X}_{k-1}^{+(i)}, u_{k}\right), \quad i=0,1,2, \cdots, 2 n Xk−∗(i)=f(Xk−1+(i),uk),i=0,1,2,⋯,2n
2. 加权计算 k 时刻状态量的先验概率分布
μ X k − = ∑ i = 0 i = 2 n W m ( i ) X k − ∗ ( i ) Σ X k − = ∑ i = 0 i = 2 n W c ( i ) [ X k − ∗ ( i ) − μ X k − ] [ X k − ∗ ( i ) − μ X k − ] T + Σ Q \begin{gathered} \mu_{X_{k}}^{-}=\sum_{i=0}^{i=2 n} W_{m}^{(i)} \mathcal{X}_{k}^{-*(i)} \\ \Sigma_{X_{k}}^{-}=\sum_{i=0}^{i=2 n} W_{c}^{(i)}\left[\mathcal{X}_{k}^{-*(i)}-\mu_{X_{k}}^{-}\right]\left[\mathcal{X}_{k}^{-*(i)}-\mu_{X_{k}}^{-}\right]^{T}+\Sigma_{Q} \end{gathered} μXk−=i=0∑i=2nWm(i)Xk−∗(i)ΣXk−=i=0∑i=2nWc(i)[Xk−∗(i)−μXk−][Xk−∗(i)−μXk−]T+ΣQ
由于过程噪声是线性可加的,所以此处 Σ Q \Sigma_Q ΣQ 直接加在了加权协方差的末尾。
2.4 对 k 时刻状态量的先验概率分布进行 sigma 采样
X k − ( i ) = { μ X k − i = 0 μ X k − + γ ( Σ X k − ) ( i − 1 ) i = 1 , ⋯ , n μ X k − − γ ( Σ X k − ) ( i − n − 1 ) i = n + 1 , ⋯ , 2 n \mathcal{X}_{k}^{-(i)}= \begin{cases}\mu_{X_{k}}^{-} & i=0 \\ \mu_{X_{k}}^{-}+\gamma\left(\sqrt{\Sigma_{X_{k}}^{-}}\right)^{(i-1)} & i=1, \cdots, n \\ \mu_{X_{k}}^{-}-\gamma\left(\sqrt{\Sigma_{X_{k}}^{-}}\right)^{(i-n-1)} & i=n+1, \cdots, 2 n\end{cases} Xk−(i)=⎩⎪⎪⎪⎨⎪⎪⎪⎧μXk−μXk−+γ(ΣXk−)(i−1)μXk−−γ(ΣXk−)(i−n−1)i=0i=1,⋯,ni=n+1,⋯,2n
某些时候,为降低运算量会省略此步, 而在下一步骤中直接使用2.2节中的 sigma 点集 X k − ∗ ( i ) \mathcal{X}_{k}^{-*(i)} Xk−∗(i), 这样做在一定程度上会降低精度。
更新步
1. 观测非线性变换
Z k ( i ) = h ( X k − ( i ) ) , i = 0 , 1 , 2 , ⋯ , 2 n \mathcal{Z}_{k}^{(i)}=h\left(\mathcal{X}_{k}^{-(i)}\right), \quad i=0,1,2, \cdots, 2 n Zk(i)=h(Xk−(i)),i=0,1,2,⋯,2n
2. 加权计算 k k k 时刻观测量 Z k Z_{k} Zk 的概率分布
μ Z k = ∑ i = 0 i = 2 n W m ( i ) Z k ( i ) Σ Z k = ∑ i = 0 i = 2 n W c ( i ) [ Z k ( i ) − μ Z k ] [ Z k ( i ) − μ Z k ] T + Σ R \begin{gathered} \mu_{Z_{k}}=\sum_{i=0}^{i=2 n} W_{m}^{(i)} \mathcal{Z}_{k}^{(i)} \\ \Sigma_{Z_{k}}=\sum_{i=0}^{i=2 n} W_{c}^{(i)}\left[\mathcal{Z}_{k}^{(i)}-\mu_{Z_{k}}\right]\left[\mathcal{Z}_{k}^{(i)}-\mu_{Z_{k}}\right]^{T}+\Sigma_{R} \end{gathered} μZk=i=0∑i=2nWm(i)Zk(i)ΣZk=i=0∑i=2nWc(i)[Zk(i)−μZk][Zk(i)−μZk]T+ΣR
由于观测噪声是线性可加的,所以此处 Σ R \Sigma_{R} ΣR 直接加在了加权协方差的末尾。
3. 计算状态量与观测量的互协方差
Σ X k Z k = ∑ i = 0 i = 2 n W c ( i ) [ X k − ( i ) − μ X k − ] [ Z k ( i ) − μ Z k ] T \Sigma_{X_{k} Z_{k}}=\sum_{i=0}^{i=2 n} W_{c}^{(i)}\left[\mathcal{X}_{k}^{-(i)}-\mu_{X_{k}}^{-}\right]\left[\mathcal{Z}_{k}^{(i)}-\mu_{Z_{k}}\right]^{T} ΣXkZk=i=0∑i=2nWc(i)[Xk−(i)−μXk−][Zk(i)−μZk]T
4. 计算卡尔曼增益
K k = Σ X k Z k Σ Z k − 1 K_{k}=\Sigma_{X_{k} Z_{k}} \Sigma_{Z_{k}}^{-1} Kk=ΣXkZkΣZk−1
5. 计算 k 时刻状态量的后验概率分布
μ X k + = μ X k − + K k ( z k − μ Z k ) Σ X k + = Σ X k − − K k Σ Z k K k T \begin{gathered} \mu_{X_{k}}^{+}=\mu_{X_{k}}^{-}+K_{k}\left(z_{k}-\mu_{Z_{k}}\right) \\ \Sigma_{X_{k}}^{+}=\Sigma_{X_{k}}^{-}-K_{k} \Sigma_{Z_{k}} K_{k}^{T} \end{gathered} μXk+=μXk−+Kk(zk−μZk)ΣXk+=ΣXk−−KkΣZkKkT
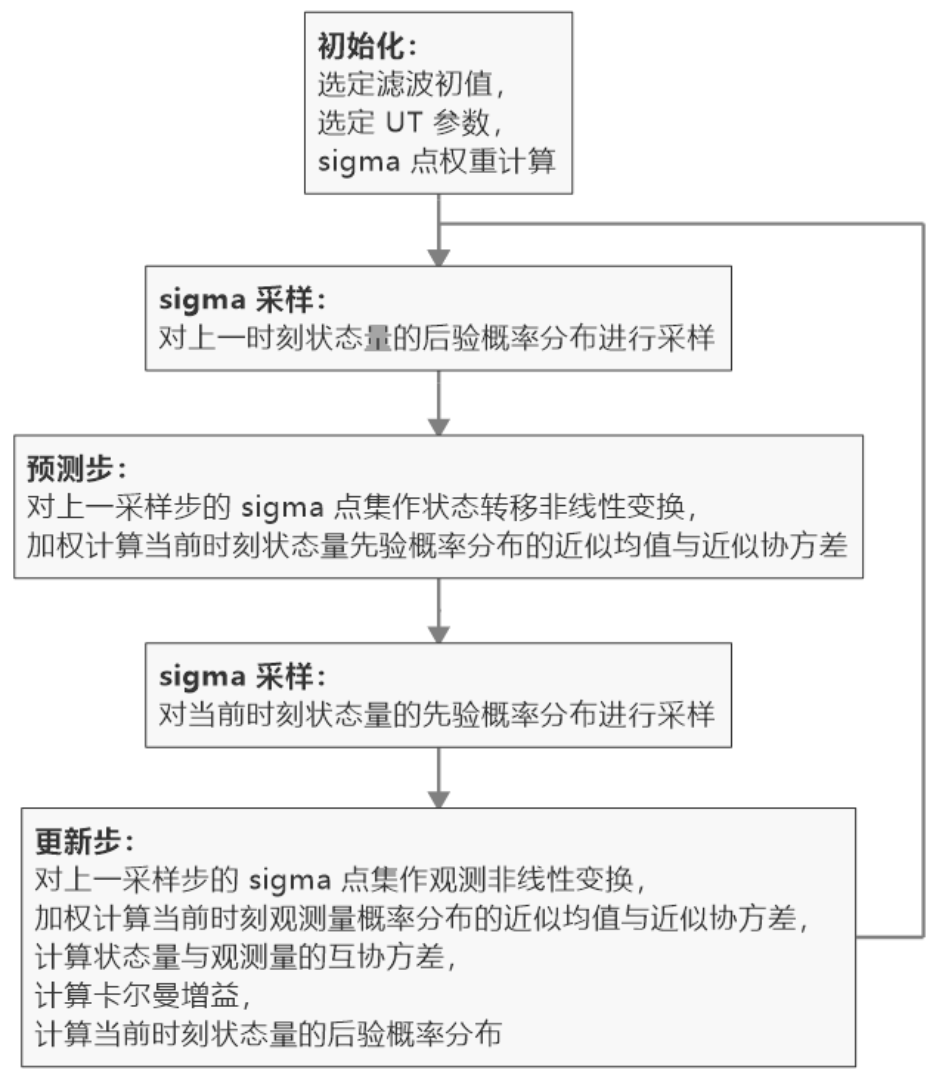
可加性噪声条件下的无迹卡尔曼滤波算法流程可总结为:
3. 应用——移动机器人应用
python实现——见于github代码仓库。