实例
本篇博文尝试将上篇博文介绍的拉格朗日松弛启发式算法应用于下面的优化模型,该模型是一个整数规划(0-1规划)模型,是选址问题中经典的p-中值模型。模型中的符号含义如下表所示。
| 符号 | 含义 |
|---|---|
| I I I | 需求点集合 |
| J J J | 候选投放点集合 |
| d i d_i di | 需求点 i i i 的需求量 |
| c i j c_{ij} cij | 需求点 i i i 与候选投放点 j j j 的距离 |
| p p p | 投放点总数 |
| x j x_{j} xj | 0-1变量,表示是否选择投放点 j j j |
| y i j y_{ij} yij | 0-1变量,表示需求点 i i i 是否由投放点 j j j 提供服务 |
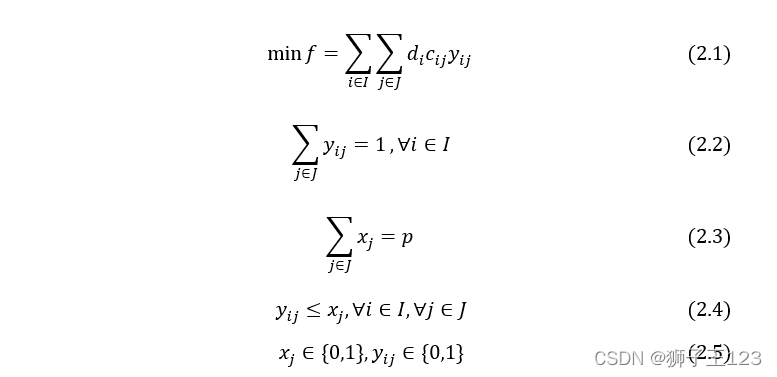
观察上述模型可以发现约束 ( 2.4 ) (2.4) (2.4) 关联两类决策变量,给问题带来了“耦合”的现象,属于复杂约束。因此,选择将该约束进行松弛,松弛后的问题如下。
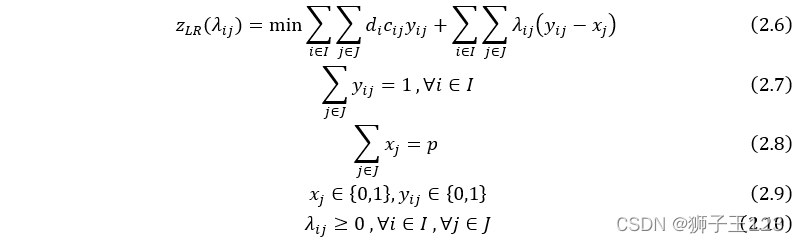
对偶问题如下。
z L D = max z L R ( λ i j ) z_{LD}=\text{max}\space z_{LR}(\lambda_{ij}) zLD=max zLR(λij)次梯度优化算法的应用有两个重要部分:一是次梯度的计算,二是给定 λ \lambda λ 后松弛问题的求解。
对于次梯度的计算,回顾定义 7.4.2可以发现次梯度不可能直接由定义计算得到。
定义 7.4.2 若函数 g : R m → R g:\Bbb{R^m}\to\Bbb{R} g:Rm→R 为凹函数,且在点 x ∗ ∈ R m x^*\in\Bbb{R^m} x∗∈Rm 处,向量 s ∈ R m s\in\Bbb{R^m} s∈Rm 满足
g ( x ∗ ) + s T ( x − x ∗ ) ≥ g ( x ) , ∀ x ∈ R m \begin{array}{ll} g(x^*)+s^T(x-x^*)\ge g(x) , \forall x\in \Bbb{R^m} \end{array} g(x∗)+sT(x−x∗)≥g(x),∀x∈Rm则称 s ∈ R m s\in\Bbb{R^m} s∈Rm 为函数 g ( x ) g(x) g(x) 在 x ∗ x^* x∗处的一个次梯度。 g ( x ) g(x) g(x) 在 x ∗ x^* x∗ 处的所有次梯度组成的集合记为 ∂ g ( x ∗ ) \partial g(x^*) ∂g(x∗)。
笔者在查阅相关资料12后发现论文中多将松弛问题的目标函数里 λ \lambda λ 前的系数作为次梯度,结合本例可得第 t t t 次迭代的次梯度 s ( t ) s^{(t)} s(t) 为一大小为 ∣ I ∣ ∣ J ∣ |I||J| ∣I∣∣J∣ 的向量,每个元素由第 t t t 次迭代时的决策变量值运算得到,即 y i j ( t ) − x j ( t ) y_{ij}^{(t)}-x_j^{(t)} yij(t)−xj(t)。
对于给定 λ \lambda λ 后松弛问题的求解,观察式 ( 2.6 ) (2.6) (2.6)至 ( 2.9 ) (2.9) (2.9) 可以发现目标函数和约束条件关于 x x x 和 y y y 都是可分的,故该问题可以等价变换为两个分别关于 x x x 和 y y y 的子问题(拉格朗日分解)。
子问题一:
z L R 1 ( λ i j ) = minimize ∑ i ∈ I ∑ j ∈ J ( d i c i j + λ i j ) y i j subject to ∑ j ∈ J y i j = 1 , ∀ i ∈ I y i j ∈ { 0 , 1 } \begin{array}{ll} z_{LR1}(\lambda_{ij})=\text{minimize} & \sum_{i\in I}\sum_{j\in J} (d_ic_{ij}+\lambda_{ij})y_{ij} \\ \text{subject to} & \sum_{j\in J}y_{ij} = 1, \forall i\in I\\ & y _{ij}\in \{0, 1\} \end{array} zLR1(λij)=minimizesubject to∑i∈I∑j∈J(dicij+λij)yij∑j∈Jyij=1,∀i∈Iyij∈{
0,1}子问题二:
z L R 2 ( λ i j ) = minimize ( − ∑ i ∈ I ∑ j ∈ J λ i j x j ) = minimize ∑ j ∈ J ( − ∑ i ∈ I λ i j ) x j subject to ∑ j ∈ J x j = p x j ∈ { 0 , 1 } \begin{array}{ll} z_{LR2}(\lambda_{ij})=\text{minimize} & (-\sum_{i\in I}\sum_{j\in J}\lambda_{ij}x_j)= \text{minimize} & \sum_{j\in J}(-\sum_{i\in I}\lambda_{ij})x_j \\ \text{subject to} & \sum_{j\in J}x_j = p \\ & x_j\in \{0, 1\} \end{array} zLR2(λij)=minimizesubject to(−∑i∈I∑j∈Jλijxj)=minimize∑j∈Jxj=pxj∈{
0,1}∑j∈J(−∑i∈Iλij)xj由于 x x x 和 y y y 都只能取 0 或 1 0或1 0或1,且目标函数和约束都较为简单,故这两个子问题都较易求解。
关于子问题一,可将目标函数视作两个矩阵( d i c i j + λ i j d_i c_{ij}+λ_{ij} dicij+λij 构成的矩阵和 y i j y_{ij} yij 构成的矩阵)对应元素相乘后再全部求和,约束条件代表后一个矩阵每行有且仅有一个元素为 1 1 1,故为使目标函数最小,只需将每行的 1 1 1 确定在前一个矩阵在该行的最小值处即可。
关于子问题二,约束条件表示有且仅有 p p p 个 x j x_j xj 取 1 1 1,故将 λ i j λ_{ij} λij 按列求和后前 p p p 大的列对应的 x j x_j xj 取为 1 1 1 即可。
编程实现
上述模型的数据来源于2016年SODA上海开放数据创新应用大赛中摩拜单车提供的共享单车订单数据集,该数据集由对在上海市发生的2016年8月1日到8月31日间的所有订单进行随机抽样得到,数据总量为10万条左右。数据字段包括:订单ID、车辆ID、用户ID、订单开始时间、订单起点经纬度、订单结束时间、订单终点经纬度和骑行轨迹坐标。
采取的编程语言为Python 3,开发环境为Jupyter Notebook。
数据准备
首先读取数据。
import pandas as pd
import numpy as np
data = pd.read_csv("./mobike_shanghai_sample_updated.csv")
data.head(10)
接下来对上述数据进行K均值聚类形成对空间的划分,将订单起点定义为该坐标处的需求,并使用聚类中心代表该类中的需求。
#以聚类数量为10,候选点数量为5,从中选3个为例
cluster_num = 10
wait_list_num = 5
p = 3
from sklearn.cluster import KMeans
km = KMeans(n_clusters = cluster_num)
X = data.loc[:,["start_location_x","start_location_y"]]
km.fit(X)
centers = km.cluster_centers_
centers = np.array(centers)
centers = centers[:,0:2]
之后计算每类中的需求量,形成需求向量(代码中变量为d_set)。并将聚类中心中需求量排名靠前的 n n n 个点作为备选点的集合(从中选择 p p p 个)。
#计算各点需求量d_set,排序后选择前n个作为候选点
label = km.labels_
X["label"] = label
import numpy as np
d_set = np.zeros(cluster_num)
for item in label:
d_set[item] = d_set[item] + 1
d_set
import heapq
top_index_list = heapq.nlargest(wait_list_num, range(len(d_set)), d_set.take)
计算所有需求点到所有备选点两两间的距离,形成距离矩阵(代码中变量为c_set)。
def MD(vector1, vector2):
d = np.linalg.norm(vector1-vector2, ord=1)
return d
c_set = np.zeros((cluster_num, wait_list_num))
for i in range(cluster_num):
for j in range(len(top_index_list)):
c_set[i][j] = MD(centers[i], centers[top_index_list[j]])
次梯度优化算法
接着实现次梯度优化算法,相关函数包括求解子问题一、求解子问题二、计算次梯度、更新次梯度。
- 求解子问题一的函数如下。
def solve_subproblem_1(c_set, d_set, lamda_set):
import copy
import numpy as np
sol_index_list = []
sol_value_list = []
A = copy.deepcopy(c_set)
for i in range(len(A)):
for j in range(len(A[0])):
A[i][j] = A[i][j]*d_set[i] + lamda_set[i][j]
A_matrix = np.array(A)
#找到A矩阵每行的最小值对应的列索引
for i in range(len(A)):
sol_index_list.append(np.argmin(A[i]))
sol_value_list.append(np.min(A[i]))
sol_value = np.array(sol_value_list).sum()
sol_matrix = np.zeros((len(A), len(A[0])))
for i in range(len(A)):
sol_matrix[i][sol_index_list[i]]=1
return sol_matrix,sol_value
- 求解子问题二的函数如下。
def solve_subproblem_2(p, lamda_set):
import numpy as np
import heapq
#lamda_set类型可构造为矩阵传入
sum_by_col = lamda_set.sum(axis=0)
top_p_index_list = heapq.nlargest(p,range(len(sum_by_col)),sum_by_col.take)
sol_vector = np.zeros(len(lamda_set[0]))
sol_value = 0
for index in top_p_index_list:
sol_vector[index] = 1
sol_value = sol_value + sum_by_col[index]
return sol_vector, -sol_value
- 计算次梯度的函数如下。
def get_subgradient(y_matrix, x_vector):
import numpy as np
s_matrix = np.zeros((len(y_matrix), len(y_matrix[0])))
for i in range(len(s_matrix)):
for j in range(len(s_matrix[0])):
s_matrix[i][j] = y_matrix[i][j] - x_vector[j]
#将次梯度以矩阵形式存储,事实上其是一个向量
return s_matrix
- 更新次梯度的函数如下。
def update_subgradient(lamda_set, s_matrix, theta):
tag = 1 #标记次梯度是否为零
if np.all(s_matrix == 0):
tag = 0
lamda_set_next = np.zeros(len(lamda_set), len(lamda_set[0]))
else:
lamda_set_next = lamda_set + theta*s_matrix
if np.all(lamda_set_next >= 0):
pass
else:
lamda_set_next = np.zeros((len(lamda_set), len(lamda_set[0])))
return tag, lamda_set_next
解的可行化
最后将次梯度优化算法求得的解可行化,函数包括判断当前解是否可行、将不可行解可行化、计算原问题目标函数值。
- 判断当前解是否可行的函数如下。
def is_feasible_sol(x_vector, y_matrix):
infeasible_loc = []
for i in range(len(y_matrix)):
for j in range(len(y_matrix[i])):
if y_matrix[i][j] > x_vector[j]:
infeasible_loc.append((i,j))
if len(infeasible_loc) == 0:
return infeasible_loc, True
else:
return infeasible_loc, False
- 将不可行解可行化(通过启发式思想)的函数如下。
def make_it_feasible(c_set, sol_x_vector, sol_y_matrix, infeasible_loc):
import copy
for item in infeasible_loc:
feasible_list = []
dic = {
}
for i in range(len(sol_x_vector)):
if sol_x_vector[i] == 1:
dic["no"] = i
dic["c_value"] = c_set[item[0]][i]
dic_1 = copy.deepcopy(dic)
feasible_list.append(dic_1)
min_index = feasible_list[0]["no"]
min_value = feasible_list[0]["c_value"]
for item_1 in feasible_list:
c = item_1["c_value"]
if item_1["c_value"] < min_value:
min_value = item_1["c_value"]
min_index = item_1["no"]
sol_y_matrix[item[0]][item[1]] = 0
sol_y_matrix[item[0]][min_index] = 1
- 计算原问题目标函数值的函数如下。
def get_object_value(sol_y_matrix, c_set, d_set):
sum = 0
for i in range(len(c_set)):
for j in range(len(c_set[0])):
sum = sum + d_set[i]*c_set[i][j]*sol_y_matrix[i][j]
return sum
主流程
主流程如下。
#在算法停止准则的选用中,选择最简单的控制迭代次数和目标函数值多次未改变
import numpy as np
import math
import copy
#初始化
import time
start_1 = time.time()
max_itertimes = 100
problem_size = (cluster_num, wait_list_num)
lamda_set = 4*np.ones(problem_size)
theta = 2
rou = 0.9
z_LR_list = []
best_feasible_val = 0
for i in range(max_itertimes):
sol_y_matrix, z_LR1 = solve_subproblem_1(c_set, d_set, lamda_set)
sol_x_vector, z_LR2 = solve_subproblem_2(p, lamda_set)
z_LR = z_LR1 + z_LR2
subgradient_matrix = get_subgradient(sol_y_matrix, sol_x_vector)
theta = theta*(rou**i)
tag,lamda_set = update_subgradient(lamda_set, subgradient_matrix, theta)
if tag == 0:
#print("次梯度为零向量,达到最优解")
break
z_LR_list.append(z_LR)
#print("第" + str(i) + "次迭代目标函数值为:" + str(z_LR))
if i >= 5:
if z_LR_list[i] == z_LR_list[i-1] and z_LR_list[i] == z_LR_list[i-2]:
print("连续三次值未改变,停止迭代,对偶问题值变化如下")
import matplotlib.pyplot as plt
plt.plot(np.arange(1, len(z_LR_list)+1), z_LR_list)
plt.show()
break
tag_sol_feasible = True
tag_sol_feasible_new = False
infeasible_loc = []
infeasible_loc, tag_sol_feasible = is_feasible_sol(sol_x_vector, sol_y_matrix)
if tag_sol_feasible == True:
best_feasible_val = get_object_value(sol_y_matrix, c_set, d_set)
best_feasible_sol_x = copy.deepcopy(sol_x_vector)
best_feasible_sol_y = copy.deepcopy(sol_y_matrix)
else:
#print("违背原约束的y_ij位置为:")
#print(infeasible_loc)
make_it_feasible(c_set, sol_x_vector, sol_y_matrix, infeasible_loc)
infeasible_loc, tag_sol_feasible_new=is_feasible_sol(sol_x_vector, sol_y_matrix)
#if tag_sol_feasible_new == True:
#print("已修正为可行解")
best_feasible_sol_x = copy.deepcopy(sol_x_vector)
best_feasible_sol_y = copy.deepcopy(sol_y_matrix)
best_feasible_val = get_object_value(sol_y_matrix, c_set, d_set)
time_used = time.time() - start_1
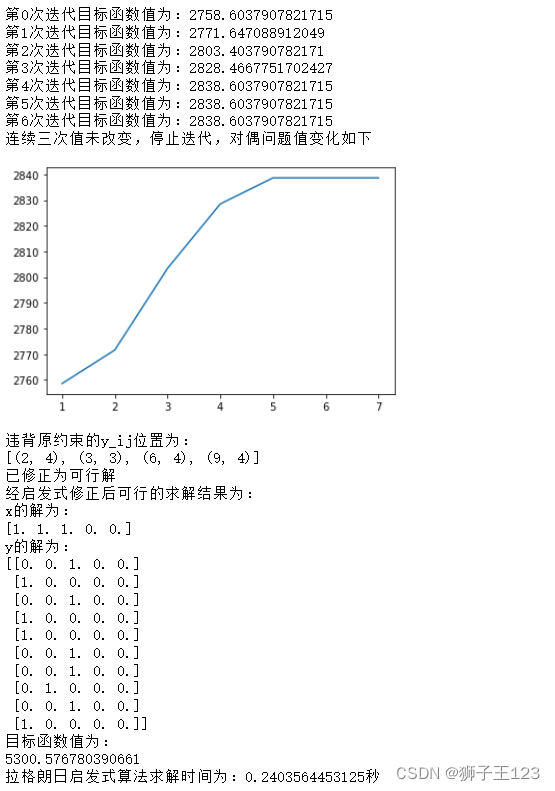
print("经启发式修正后可行的求解结果为:")
print("松弛后问题目标函数值z_LR为:" + str(best_feasible_val))
print("x的解为:")
print(best_feasible_sol_x)
print("y的解为:")
print(best_feasible_sol_y)
print("目标函数值为:")
print(best_feasible_val)
print("拉格朗日启发式算法求解时间为:" + str(time_used) + "秒")
求解结果
以聚类数量(需求点数量)为 10,候选点数量为 5, p p p 值为 3 的情况为例,输出如下。可以看到对偶问题的值随着迭代在不断提升。
与Gurobi求解的对比
笔者还尝试了使用Gurobi求解器进行求解,从官网安装Gurobi后,再通过pip安装gurobipy即可在Python中调用Gurobi求解器。相关代码如下。
首先构造目标函数中的系数。
#将d_i和c_ij乘在一起构成目标函数中的系数
coeffcient_matrix = np.zeros((len(c_set), len(c_set[0])))
for i in range(len(c_set)):
for j in range(len(c_set[0])):
coeffcient_matrix[i][j] = d_set[i]*c_set[i][j]
接着将模型用Gurobi的语言描述出来,最后调用Gurobi求解器即可。
#调用Gurobi求解p中值模型
import gurobipy as grb
from gurobipy import GRB
import time
#创建一个名字为p_median_problem的模型
start = time.time()
m = grb.Model("p_median_problem")
#添加决策变量
y = m.addVars(len(c_set), len(c_set[0]), vtype = grb.GRB.BINARY, name = "y")
x = m.addVars(len(c_set[0]), vtype = grb.GRB.BINARY, name = "x")
#添加约束
#y矩阵按行求和值为1
m.addConstrs((y.sum(i,"*") == 1 for i in range(len(c_set))), name = "demand")
#x向量各分量求和等于p,只添加一个约束函数名不能加s!addConstr
m.addConstr((x.sum("*") == p), name = "pvalue")
for i in range(len(c_set)):
for j in range(len(c_set[0])):
m.addConstr((y[i,j] <= x[j]), name="ouhe")
#添加目标函数
c1 = []
for i in range(len(c_set)):
for j in range(len(c_set[0])):
c1.append((i,j))
coeff = grb.tupledict(c1)
for i in range(len(c_set)):
for j in range(len(c_set[0])):
coeff[(i,j)] = coeffcient_matrix[i][j]
obj = y.prod(coeff)
m.setObjective(obj, GRB.MINIMIZE)
#求解模型
m.optimize()
time_used = time.time() - start
print("Gurobi求解时间为:" + str(time_used) + "秒")
#输出结果
for k in range(len(m.getVars())):
print('%s %g' % (m.getVars()[k].varName, m.getVars()[k].x), end=" ")
if (k+1) % 5 == 0:
print()
运用拉格朗日松弛启发式算法和Gurobi求解器求解的对比如下图所示。
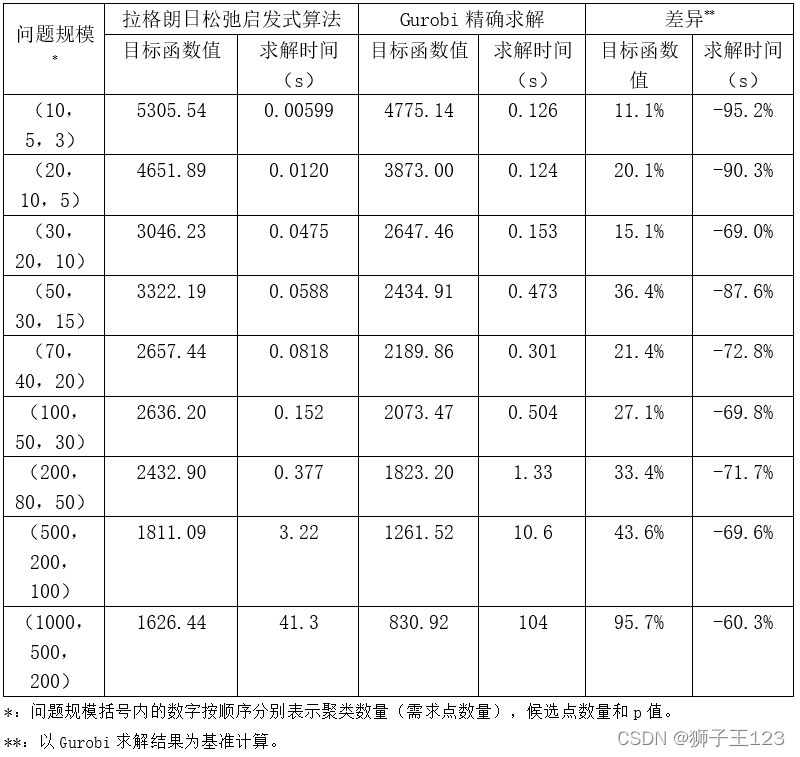
从图中可以看到拉格朗日松弛启发式算法在计算时间方面存在优势,但在解的质量方面存在不足,并且随着问题规模的扩大其与Gurobi求解的差距在扩大,这与我们的拉格朗日松弛启发式算法参数更新和停止准则设置得较为简单有一定关系。
总的来说,拉格朗日松弛的思想和拉格朗日松弛启发式算法是可以尝试的内容。