KMeans算法是无监督学习算法,用在聚类任务中。可以使用的业务场景有:客户分群、商品分类、推荐系统、图像分割等。本期用一份简单的数据集带大家了解KMeans算法在客户分群的使用。
导入数据
import pandas as pd
data = pd.read_excel('/kaggle/input/customer-age-and-income/Customer age and income.xlsx')
data.info()数据集已上转至kaggle,有需要的可以在下方评论找地址自行下载哟。
数据探索
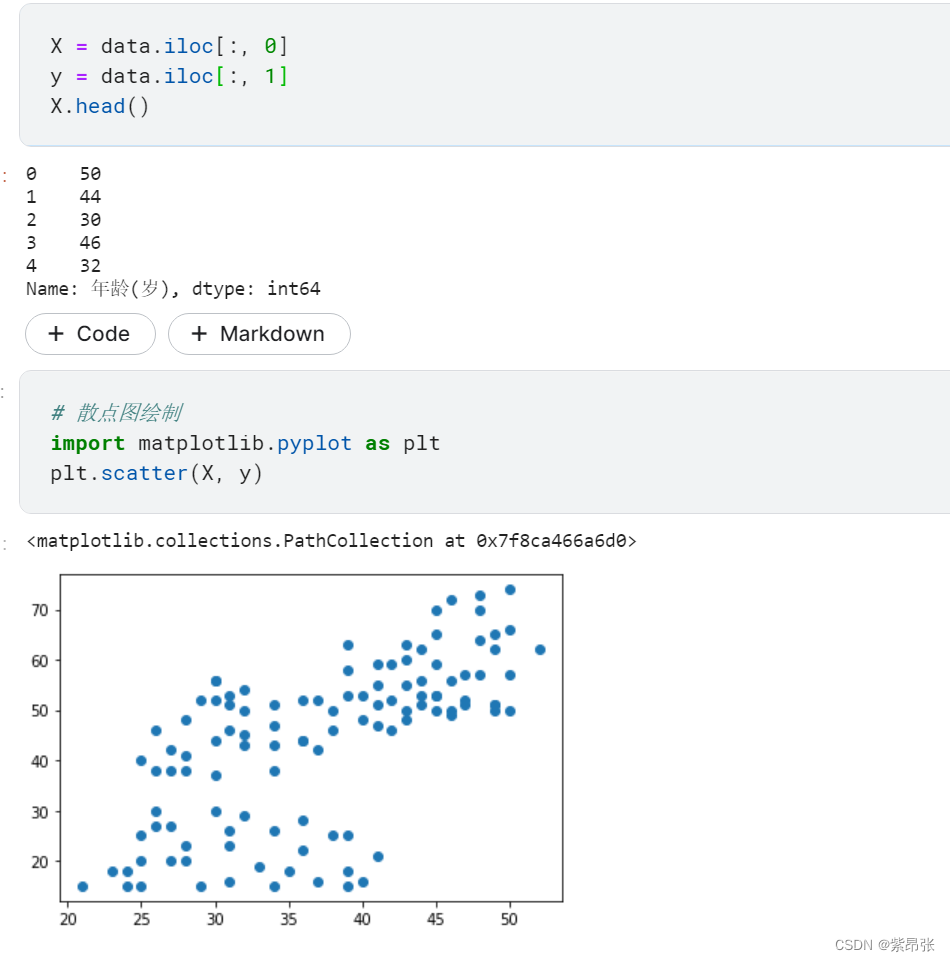
X = data.iloc[:, 0]
y = data.iloc[:, 1]
# 散点图绘制
import matplotlib.pyplot as plt
plt.scatter(X, y)代码讲解:
scatter()是用于绘制散点图的函数;
X是我们定义的横坐标,代表年龄;y是纵坐标代表收入;
运行结果:
训练模型
扫描二维码关注公众号,回复:
14749210 查看本文章

from sklearn.cluster import KMeans
kms = KMeans(n_clusters=3, random_state=123)
kms.fit(data)
label = kms.labels_
label代码讲解:
导入KMeans包,并把模型赋值给我们自定义的参数kms;
n_clusters=3指定了聚类的数量为3个,是我们手动定义簇的数据,通过上面的散点图也可以发现数据大致分为3块;
random_state是随机种子,可以自定义一个数字,以确保每次运行的结果都一样;
模型.fit()的写法在每次训练模型都有写到,fit()里面写数据集,将参数传入进行模型训练;
KMeans的labels_属性可以返回每个数据点所属的聚类,但是这样不够直观,我们继续把类别标签用图形表示;
运行结果:

绘制聚类结果
plt.scatter(X[label == 0], y[label == 0], c="red")
plt.scatter(X[label == 1], y[label == 1], c="green")
plt.scatter(X[label == 2], y[label == 2], c="yellow") 代码讲解:
scatter()是用于绘制散点图的函数;
X是我们定义的横坐标,代表年龄;y是纵坐标代表收入;
运行结果:
