什么是后处理
屏幕后处理,指的是在渲染完场景内所有物体到颜色缓冲区后,再对该颜色缓冲区进行处理,实现各种屏幕特效,提升最终画面呈现品质的重要渲染技术
与渲染模型的区别
正常模型渲染时,cpu将模型数据提交给gpu,执行顶点着色器和像素着色器,在shader中可以对模型数据包括顶点坐标,法线,uv坐标等等进行访问。
而unity后处理的实现为,生成一个只有四个顶点的正方形面片覆盖整个屏幕,将之前已经渲染好的颜色缓冲作为一张纹理贴图传进后处理使用的shader,因此后处理shader的顶点着色器只会执行4次。正常情况下,后处理使用的shader只能访问到之前的颜色缓冲每个像素的颜色,而访问不到该像素对应的模型信息,所以后处理时能访问到的数据其实很少,能实现的效果和对单个模型使用的shader相比也有限。不过通过一些特殊pass的帮助,也可以访问到一些有限的额外信息例如该像素点对应的深度和法线。
因此对某些后处理效果,例如全局雾效,既可以将其写在模型所使用的shader上,也可以写在后处理中统一处理,统一处理的好处为不用修改所有的已有shader代码来添加某种效果,坏处就是可能获取不到需要的数据,可以实现的效果有限。
一些后处理算法与数字图像处理领域所用的算法类似,但是一般图像处理都是使用cpu进行离线处理,而游戏中的后处理,需要每帧进行更新而且大部分运行在gpu上,所以算法细节有所不同,很多耗费大量时间的离线计算就没法用在游戏的后处理中。
后处理示例图
下图为unity中一个场景开启和关闭一些常见后处理的效果对比。其中用到了全局雾效,bloom,景深,移轴模糊,体积光,环境光遮蔽,抗锯齿,色调映射,对比度饱和度调整等
可以看出,后处理对最终画面品质的影响相当大。


Unity如何实现后处理
OnRenderImage
在unity中挂载在摄像机上的脚本可以声明OnRenderImage函数,和Start,Update之类的函数类似,OnRenderImage也是由unity调用的,OnRenderImage的默认调用时机为所有透明和非透明的pass执行完毕之后。但是可以通过添加[ImageEffectOpaque]属性调整为只在非透明shader执行完之后调用,而不对透明shader起效果。
当我们在脚本中声明此函数后,Unity会把当前颜色缓冲存储在第一个参数对应的源渲染纹理中,第二个参数对应的渲染纹理最后会显示到屏幕上,因此我们在该函数中的操作就是需要根据源纹理做一些操作,最后写入到第二个参数中。
void OnRenderImage(RenderTexture src, RenderTexture dest)
Graphics.Blit
我们通常使用Graphics.Blit函数来完成对渲染纹理的处理,参数src对应了源纹理,参数dest是目标纹理,参数mat是我们使用的材质,其中材质又需要设置该材质对应的shader,src纹理会被固定传入材质对应的shader中命名为_MainTex的纹理属性。除了固定传入的源纹理外,还可以设置其他属性来调节参数。对于一些复杂的屏幕效果,需要多次调用Graphics.Blit来重复处理。
public static void Blit(Texture source, RenderTexture dest, Material mat)
一个调用的例子
private void OnRenderImage(RenderTexture src, RenderTexture dest)
{
Material material = new Material(shader);
material.SetFloat("brightness", brightness);
material.SetFloat("saturation", saturation);
material.SetFloat("contrast", contrast);
Graphics.Blit(src, dest, material);
}
后处理效果的堆叠
多个后处理效果,可以都挂载在同个摄像机上,执行顺序为从上到下,上一个输出的目标纹理会被设置为下一个脚本里OnRenderImage函数的源纹理,直到执行完所有的OnRenderImage,最后输出的目标纹理会显示到屏幕上。
目前已经很少用这种原始的形式来堆叠后处理效果,一般为了优化会对多种后处理效果进行合并,例如合并某些共用某一阶段的shader。而unity官方也有提供一个Post Processing的包,其中包括各种写好的常见后处理效果,也可以把自己写的后处理继承它的基类,合并到它的后处理堆栈中。

后处理shader通用设置
在后处理shader中,一般会设置以下几个状态,
ZTest Always 深度测试总是通过,这是因为屏幕后处理效果就是显示在最上层的,无需进行深度测试。
ZWrite Off 关闭深度写入,如果不关闭且该后处理执行完之后还有物体需要渲染,则该物体会被挡住。
Cull Off 关闭背面剔除,主要用于不同设备兼容性
这些状态可以认为是用于屏幕后处理的Shader的‘标配’
Cull Off ZWrite Off ZTest Always
模糊后处理
模糊是一种后处理的类别,效果就是让图像变得模糊,其中包括均值模糊,高斯模糊,径向模糊,方向模糊,中值模糊,光圈模糊,粒状模糊,散景模糊等等…模糊不仅是是作为单一的后处理效果来使用,其还用在很多其他后处理效果的某一阶段,例如bloom效果,Sun Shaft,镜头眩光光晕,景深等等。
后处理效果都需要c#脚本和shader文件配合来实现效果,其中模糊算法c#脚本都具有类似的过程,大概如下所示
private void OnRenderImage(RenderTexture src, RenderTexture dest)
{
//-----------降采样----------
var width = src.width >> downSample;
var height = src.height >> downSample;
var tempBuffer = RenderTexture.GetTemporary(width, height);
tempBuffer.filterMode = FilterMode.Bilinear;
Graphics.Blit(src,tempBuffer);
//------------------------------
//-----------迭代----------------
for (int i = 0; i < interation; i++)
{
var tempBuffer2 = RenderTexture.GetTemporary(width, height);
tempBuffer2.filterMode = FilterMode.Bilinear;
//设置其他参数
mat.SetFloat(BlurDistance,blurDistance*(i+1));
Graphics.Blit(tempBuffer,tempBuffer2,mat);
RenderTexture.ReleaseTemporary(tempBuffer);
tempBuffer = tempBuffer2;
}
//--------------------------------
//-----------写入目标纹理--------------
Graphics.Blit(tempBuffer,dest);
RenderTexture.ReleaseTemporary(tempBuffer);
//------------------------------------
}
通用步骤1-降采样
首先使用RenderTexture.GetTemporary(width, height)获取一张临时纹理来存储迭代过程中的中间值,该临时纹理的分辨率一般不与源分辨率相同,如果临时纹理的分辨率小于源纹理的分辨率则称之为降采样。
例如将一个10241024分辨率的源纹理塞进一个256256分辨率的临时纹理中,需要特别注意的是,一般不认为这种操作并不会影响模糊的品质,因为什么是好模糊什么是坏模糊本身就很难界定,一般来说,这种降采样的分辨率反而会提升模糊的效果。因为这种降低分辨率的过程本身就可以带来一定程度的模糊效果,反而如果没有这一步的操作,直接在原图像上进行模糊,得到的图像会比较清晰,要经过更多次的迭代才能达到理想的效果。
至于大分辨率的图像是怎么塞进低分辨率的图像,对低分辨率的每个像素而言,他到底对应的是高分辨率的哪个像素呢?这里篇幅有限不展开,可以搜索图像缩放的算法。
一般使用双线性插值算法即可,双线性插值大概就是对高分辨率图像的几个点进行方形线性插值,得到低分辨率图像的一个点。此操作是目前大部分显卡直接支持的,运算速度非常快,我们只需要设置对应的模式即可
在unity中使用tempBuffer.filterMode = FilterMode.Bilinear就可以设置rt的过滤模式为双线性插值。
通用步骤2-迭代
第二步即为迭代,一般模糊效果很难在一次迭代内完成,因此需要将一次模糊得到的目标纹理,再次作为源纹理,进行模糊设置进下一个目标纹理中,一般我们只用一个临时变量加上unity本身传来的源纹理两个纹理就可以来回的进行这种迭代操作,每次迭代时还需要设置其他参数。
在每次迭代过程中,都会调用 Graphics.Blit,该方法需要传入源纹理和目标纹理,以及材质。该材质对应的shader文件完成了真正的一次模糊算法,在材质中还可以设置一些其他参数传入。在每次迭代的最后,我们交换源纹理和临时变量的位置,这样就可以让目标纹理作为下一次迭代的源纹理,同时需要调用RenderTexture.ReleaseTemporary释放创建出来的临时纹理。
通用步骤3-写入目标纹理
最后一步,迭代完成之后,将临时纹理中的数据写入目标纹理,即OnRenderImage的第二个参数中,该目标纹理最后会被显示到屏幕上。注意在这里临时纹理的分辨率和目标纹理的分辨率也是不同的,所以有一个放大临时纹理的操作,该放大操作使用的算法也是通过设置filterMode来指定,一般使用双线性插值效果就足够好了。
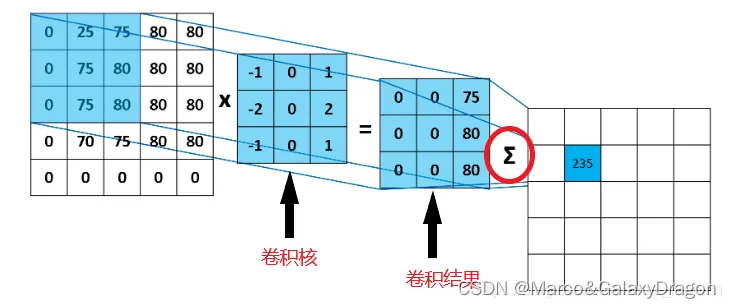
卷积核
上面主要是介绍了c#脚本方面的编写,接下来介绍shader方面的编写,所有的模糊算法shader也都有一定的共性。
所有的模糊算法,大致都有如下的处理过程,遍历源图像的所有像素,对每个像素通过对应的卷积核执行一个卷积操作。
在数学定义中,卷积是两个变量在某范围内相乘后求和的结果。
在模糊后处理中,我们可以简单的将卷积这样理解,一个小区域中像素加权平均后成为输出图像中的每个对应像素。
如下图是一个3x3的卷积核,因此对每个像素我们需要做如下操作。
首先将该像素置于该卷积核的中心位置,然后根据该卷积核,遍历一共9个像素,将它们各自的颜色或者其他值乘上它们对应的权值求和,对该卷积核而言,就是
左上角的像素颜色乘上权值1+上方的像素颜色乘上权值1+右上角的像素颜色乘上权值1+左方的像素颜色乘上权值1+中心的像素颜色乘上权值1+右方的像素颜色乘上权值1+左下角的像素颜色乘上权值1+下方的像素颜色乘上权值1+右下角的像素颜色乘上权值1
全部加起来之后,除以该卷积核的总权值9,得出的结果就是该像素在应用了该卷积核进行卷积后的结果。
至于上方,下方到底是间隔几个像素的上方下方,这个可以由参数决定,不同的参数效果不同,一般而言可以取间隔为1像素。
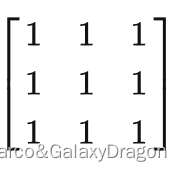
除了正方形的卷积核外,还有很多其他形状的卷积核对应不同的模糊效果。
卷积核越大,效果相对越好,但是需要处理的像素数目越多。
模糊后处理都有几个通用的参数,
采样间隔:指卷积核中每个位置之间的像素间隔。
迭代次数:因为单次采样效果不明显,所以需要多遍执行该卷积核,得到更好效果。
降采样比例:该模糊图像以什么分辨率进行处理,一般为性能着想都不以屏幕分辨率进行模糊
下面我们一一介绍不同的模糊算法以及其对应的卷积核,对下面这张图进行处理

均值模糊
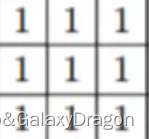
均值模糊又称盒式模糊,其卷积核为权值都为1的正方形,通常用3x3的卷积核或5x5的卷积核。
box blur效果一般,需要多次迭代才能达到一定的模糊效果,所以性能也较差。
使用的3x3卷积核
关键代码
fixed4 frag(v2f i) : SV_Target
{
fixed4 col = tex2D(_MainTex, i.uv + fixed2(0, 0) * _BlurDistance*_MainTex_TexelSize.xy) * 1/9;
col += tex2D(_MainTex, i.uv + fixed2(0, 1) * _BlurDistance*_MainTex_TexelSize.xy) * 1/9;
col += tex2D(_MainTex, i.uv + fixed2(-1, 0) * _BlurDistance*_MainTex_TexelSize.xy) * 1/9;
col += tex2D(_MainTex, i.uv + fixed2(-1, -1) * _BlurDistance*_MainTex_TexelSize.xy) * 1/9;
col += tex2D(_MainTex, i.uv + fixed2(0, -1) * _BlurDistance*_MainTex_TexelSize.xy) * 1/9;
col += tex2D(_MainTex, i.uv + fixed2(1, -1) * _BlurDistance*_MainTex_TexelSize.xy) * 1/9;
col += tex2D(_MainTex, i.uv + fixed2(-1, 1) * _BlurDistance*_MainTex_TexelSize.xy) * 1/9;
col += tex2D(_MainTex, i.uv + fixed2(0, 1) * _BlurDistance*_MainTex_TexelSize.xy) * 1/9;
col += tex2D(_MainTex, i.uv + fixed2(1, 1) * _BlurDistance*_MainTex_TexelSize.xy) * 1/9;
return col;
}
最后效果

高斯模糊
高斯模糊得名于高斯分布曲线,又称正态分布,其卷积核的值对应于正态分布函数的对应离散值。
高斯模糊在达到一定模糊效果时所需要的迭代次数要小于均值模糊,同时高斯模糊所提供的模糊效果也较好。
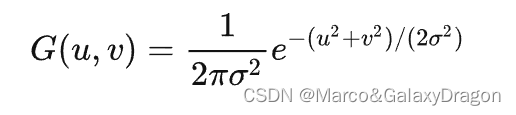
其中r为模糊半径
正态分布曲线示意图,靠近中间区域值权重高,离开中心后迅速降低。
离散化之后的5x5卷积核为

代码地址
应用之后的效果为

Kawase模糊
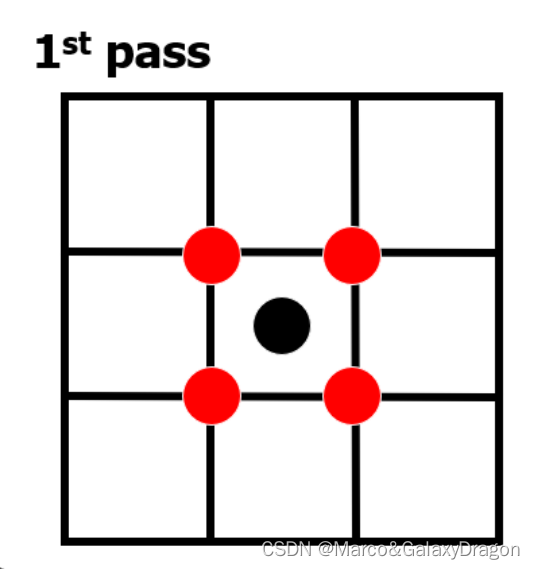
Kawase模糊的卷积核类似均值模糊,但与均值模糊不同,其每次迭代时采样间隔都会翻倍。
采样间隔不断变大
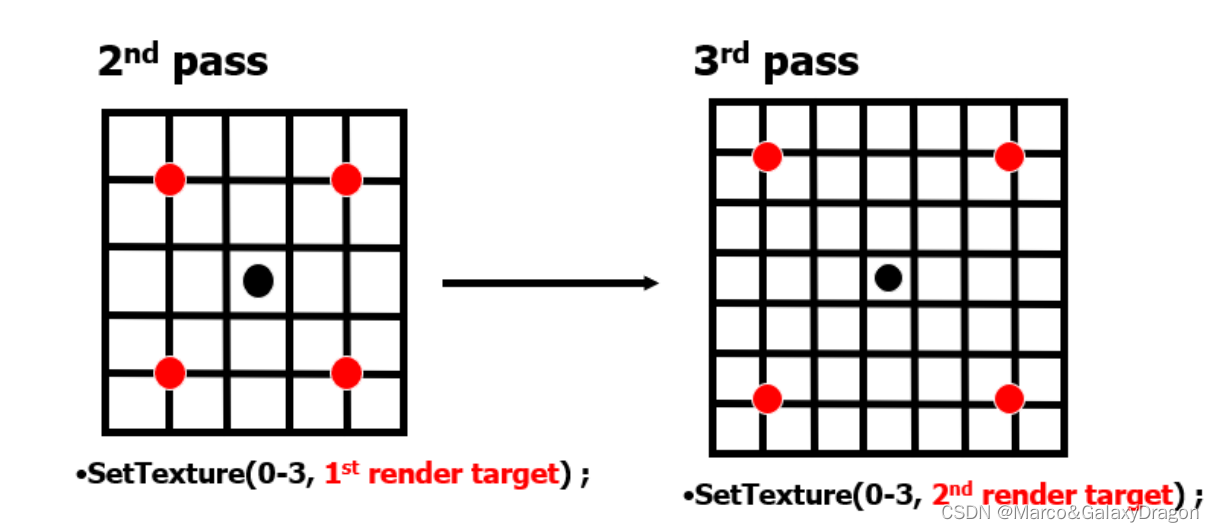

所以KawaseBlur的shader代码基本也和均值模糊相同,只是在c#脚本方需要调整

代码地址
Kawase模糊能比均值模糊更快收敛到相同的模糊效果,且采样次数也较少(2x2卷积核,均值模糊一般用3x3卷积核)
而且不用像经过优化的高斯模糊一样每一轮需要做两个pass,因此性能较好

径向模糊
径向模糊的卷积核非正方形,而是从该像素到整张图中心点的一条直线,该直线上的像素点权重可以为1,也可以随着离中心的距离越远权重越低。
如下图所示,绿点代表某个需要渲染的像素点,则渲染绿点所需要采样的点就是沿着红色箭头直到屏幕中心的点,至于到底要采样几个点,采样的间隔都可以根据参数而定。
在一些实现中,中心点也可以通过参数设置,使之不是处于屏幕正中央,而是某个特定的点。
关键代码
fixed4 frag(v2f i) : SV_Target
{
fixed4 col;
float totalWeight = 0;
fixed2 direction = i.uv - _Center.xy;
for (int index = 0; index < _Iteration; index++)
{
float2 newUV = i.uv + direction * index * _MainTex_TexelSize.xy * _Radius;
float singleWeight = 1 - dot(direction.x, direction.y);
col += tex2D(_MainTex, newUV) * singleWeight;
totalWeight += singleWeight;
}
return col / totalWeight;
}

方向模糊
方向模糊类似于径向模糊,只是其卷积核不是从像素点到中心点的直线,而是从像素点沿着某个指定方向的直线。
如下图所示,几个绿点是需要渲染的任意像素,渲染它们所需要采样的点就是沿着一个给定的方向,即红色箭头方向上的点
fixed4 frag (v2f i) : SV_Target
{
fixed4 col;
float totalWeight=0;
for(int index=0;index<_Iteration;index++)
{
float weight=(float)1/(index+1);
totalWeight+=weight;
col+=tex2D(_MainTex,i.uv+index*_Direction*_MainTex_TexelSize.xy)*weight;
}
return col/totalWeight;
}

散景模糊
散景模糊的卷积核近似为圆形,如下图所示,但是采样点之间的间隔不固定,该卷积核的形状是通过在一个循环中每次用旋转矩阵旋转采样点,同时不断增大采样间隔得来。

关键代码
fixed4 frag(v2f i) : SV_Target
{
fixed4 finalColor;
float singleWeight = 1;
float totalWeight = 0;
float2 offset = float2(0, _Radius);
float rotateCos = cos(_RotateDistance);
float rotateSin = sin(_RotateDistance);
float2x2 rotateMatrix = float2x2(float2(rotateCos, rotateSin),
float2(-rotateSin, rotateCos));
for (int index = 0; index < _SampleCount; index++)
{
singleWeight+=1/singleWeight;
offset = mul(rotateMatrix, offset);
fixed4 color= tex2D(_MainTex, i.uv + offset * _MainTex_TexelSize.xy*(1-singleWeight));
finalColor +=color;
totalWeight += 1;
}
return finalColor / totalWeight;
}

移轴模糊
移轴模糊主要是基于对其他的模糊效果使用遮罩,来达到一种模糊效果强度变化从而使画面焦点变化的效果。
移轴模糊使用的遮罩大致如下,中间模糊效果强,上下两边模糊效果弱

这种遮罩可以使用实际的图片,也可以直接在shader中进行处理。
如果直接在shader中进行处理,就是写一个输入uv值,返回模糊强度的方法
例如
fixed gridentUV(fixed2 uv)
{
return saturate(pow(abs((uv.y - 0.5+_Offset) * 2), _Pow/10));
}

光圈模糊
光圈模糊和移轴模糊一样,也是基于对其他全屏模糊效果应用遮罩,只是光圈模糊的遮罩是圆形。
如果需要在代码中生成这样的遮罩,方法如下,输入uv返回模糊强度

fixed gridentUV(fixed2 uv)
{
fixed2 distance=(uv-fixed2(0.5,0.5))*2;
return saturate(pow(abs(dot(distance,distance)),_Pow));
}

模糊后处理的相关优化
模糊对性能的损耗相当大,假设用一个5x5卷积核做高斯模糊,迭代15次,那么在没有任何优化的情况下,对每个像素就需要采样其他375个像素做运算,在2k分辨率下,一共需要采样25601440375=138240000个像素,而且是每帧都需要采样这么多。更别说一般在游戏中后处理不止一个,而不少后处理都依赖于各种模糊作为中间步骤,因此完全没有经过任何优化的模糊开销是非常大的,更别说一些手持设备的gpu性能离高端显卡有相当大的差距,但分辨率又较高,如果不做任何优化,这种开销会大大影响帧率。
我们从上面的伪码开始,一步一步的进行优化。这些优化之间并不冲突,可以叠加使用。
优化1
第一步就是降低临时rt的分辨率,只要降低一半的宽高,采样数目就可以下降到原来的1/4。
这种降低分辨率的过程本身就可以带来一定程度的模糊效果,反而如果没有这一步的操作,直接在原图像上进行模糊,得到的图像就不是特别模糊。一般而言使用原来分辨率1/4或者1/8的宽高,可以同时带来不错的模糊效果和性能提升。
假设原来为2k分辨率,那么在1/4宽高下临时rt的分辨率就是640*360,需要采样的像素数下降为原来的1/16。
优化2
降低迭代次数也可以线性的降低需要采样的像素数目,少迭代一半次数,需要采样的像素数就下降一半。
由于各个模糊算法收敛到合适的模糊效果所需要的迭代次数不同,游戏中追求的效果也不同,所以很难说多少的迭代次数是合适的,只能是逐步调整到一个期望值,但是这个值一般都会大于10,否则模糊效果就会不太明显。
优化3
这是所有shader都可以通用的优化方法,即尽可能将代码上移,从像素着色器上移到顶点着色器,从顶点着色器上移至cpu侧,因为像素着色器的执行次数要远大于顶点着色器,在后处理中,像素着色器对屏幕分辨率内的每个像素执行一次,而顶点着色器只会执行四次,cpu侧的代码只会执行一次。
但并不是所有代码都可以上移,只有满足线性插值后结果正确的值才可以从像素着色器上移到顶点着色器。
而从顶点着色器上移至cpu侧一般是一些常量的计算,而且需要均衡cpu侧和gpu侧的负载,也并不是所有计算都上移至cpu就最好的,毕竟如果这样还要gpu做什么,对大部分矩阵,矢量运算来说,即使会导致重复执行,gpu执行速度也比cpu快得多,因为大部分gpu都有针对矩阵和矢量运算优化的硬件。
从像素着色器上移至顶点着色器的例子有,模糊中计算卷积核内每个像素uv的代码可以上移至顶点着色器。
从顶点着色器上移至cpu侧的例子,径向模糊中在cpu侧直接根据角度计算出一个方向向量传入着色器,而不是在顶点着色器中重复根据角度计算方向向量。
该优化的效果不好估量,但有时可以起到很大的优化效果
优化4
利用函数的线性可分性质。部分正方形卷积核具有该性质,至于什么样的函数具有该性质以及如何判别,这里不再展开。
高斯分布即具有线性可分性质,根据该性质
使用
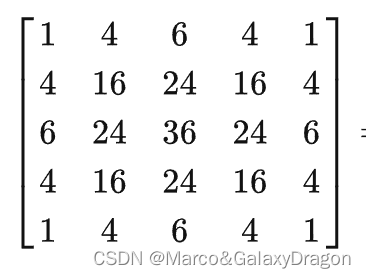
卷积核进行卷积,等价于先使用
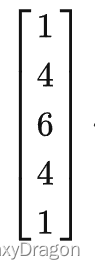
进行一次卷积,再使用进行一次卷积。
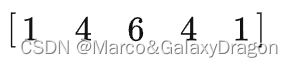
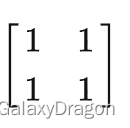
通过这种优化,对5x5的卷积核而言,采样次数从25下降至10,该优化可以平方级的降低采样次数,但迭代数从1上升至2。
因此是提升了cpu端的消耗降低了gpu端的消耗。
不过总的来说,该方法能降低大量的gpu端消耗,所以一般都会采用这种优化。
优化5
现在几乎所有显卡都支持硬件级的双线性插值功能,即对非像素中心的访问可以直接得到双线性插值后的结果。
如下图代表四个像素,假设它们的像素坐标分别为(0,0) (0,1) (1,0) (1,1),使用这些坐标就可以访问到它们对应的像素颜色。
那么如果使用非整数坐标访问呢,例如访问(0.5),(0.5),此时硬件会直接使用该坐标以及四个像素,采用双线性插值算法返回对应的颜色结果。这个采样的速度略低于直接访问像素中心,但是比你自己在像素着色器中分别采样四个像素中心再手动进行双线性插值要快得多。

通过利用该硬件上的加速,我们可以优化之前的一些模糊,例如2x2的均值模糊本来需要采样四个点,通过利用硬件级的双线性插值,直接访问中心点的坐标就是我们需要的结果了。
对于高斯模糊,也可以通过该硬件支持进行优化,但是高斯模糊使用该性质进行优化后需要重新计算每个点对应的权值。
优化6
对很多模糊效果来说,其并不需要每帧都进行更新,或者是不在每帧更新,肉眼也难以察觉出不同,例如前景层清晰,背景层模糊,根据一些视觉认知理论,此时人会更加关注前景层,那么背景层模糊的更新频率就可以降低而难以察觉。
这种优化也可以线性的降低采样次数。
实例
如果叠加使用这几种优化,就假设对上面的5x5高斯模糊卷积核进行优化,首先写入1/4源宽高的rt,降低一半的迭代次数,使用线性可分将25个采样点下降到10个,再使用硬件双线性插值将10个采样点下降为6个。最后每3帧更新一次。
那么最后平均每帧需要采样的像素数目就可以下降为1/166/251/3=0.005即原来的千分之五。
对2K分辨率而言,就是将每帧需要采样的像素数目从138240000下降为691200个。
但即使如此,对一些低端手持设备而言,使用模糊的开销还是难以承受,因此最好的办法也只能是通过其他美术效果,例如一些静态图来替代实时的模糊效果。
同样,上面所有的优化其实都会影响到最后模糊的效果,但是还是那句话,模糊的’好坏’很难界定,一般而言,只要和美术沟通选择一个合适的效果即可,并不是说这些参数就越大效果越好,或者越小就性能越好。