文章目录
推荐阅读:
Pseudo-Label:深度学习中一种简单有效的半监督方法
伪标记,只是选取具有最大预测概率的类,就像它们是真实的标签一样使用。
熵正则化和熵最小化:Entropy Minimization & Regularization
GitHub的官方源码:google-research/mixmatch
摘要
MixMatch统一了目前半监督学习的主流方法,产生了一种新的算法,它为数据增强的未标记的例子猜测低熵标签,并使用MixUp混合标记和未标记的数据。
1. Introduction
许多半监督学习方法是在未标记的数据上,计算一个损失项,损失项属于下列三类之一:
(1)熵最小化:它鼓励模型在未标记的数据上输出有信心的预测;
(2)一致性正则化:它鼓励模型在其输入被扰动时产生相同的输出分布;
(3)通用正则化:它鼓励模型进行良好的泛化并避免对训练数据的过度适应。
MixMatch,一种SSL算法,它引入了一个单一的损失,优雅地统一了这些半监督学习的主流方法。
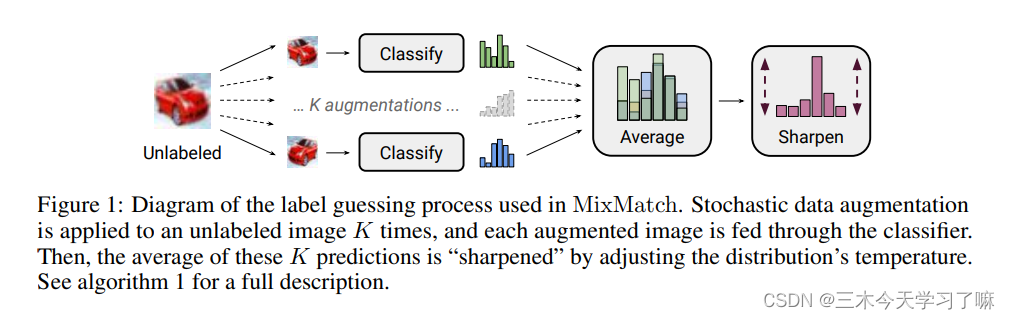
图1:MixMatch中使用的标签猜测过程示意图。随机数据增强被应用于一个无标签的图像上K次,每个增强的图像都被送入分类器。然后,通过调整分布的temperature,对这K个预测的平均值进行 “锐化”。
2. Related work
2.1 Consistency Regularization 自洽正则化
监督学习中常见的正则化技术是数据增强,它应用了假定不影响类语义的输入变换。例如,在图像分类中,常见的是对输入图像进行弹性变形或添加噪声,这可以极大地改变图像的像素内容而不改变其标签
自洽正则化对未标记数据进行数据增强,产生的新数据输入分类器,预测结果应保持自洽。即同一个数据增强产生的样本,模型预测结果应保持一致。此规则被加入到损失函数中

请注意,Augment(x)是一个随机变换,所以公式(1)中的两个项并不完全相同。
MixMatch 通过对图像使用标准数据增强(随机水平翻转和裁剪)来利用自洽正则化形式。
2.2 Entropy Minimization
许多半监督学习方法的一个共同基本假设是,分类器的决策边界不应经过边际数据分布的高密度区域。 强制执行的一种方法是要求分类器在未标记的数据上输出低熵预测。有一个损失项,它使模型预测无标签数据的熵最小。
"Pseudo-Label"通过从对无标签数据的高置信度预测中构建硬(1-hot)标签,并将其作为标准交叉熵损失的训练目标,隐性地实现了熵的最小化。MixMatch也通过对无标签数据的目标分布使用 "锐化 "函数隐含地实现了熵最小化。
2.3 Traditional Regularization

我们使用权重衰减,对模型参数的L2准则进行惩罚。我们还在MixMatch中使用MixUp。我们利用MixUp作为正则器(应用于标记的数据点)和半监督学习方法(应用于未标记的数据点)。MixUp之前已经被应用于半监督学习;
3. MixMatch
X是带标签的数据,U是不带数据的标签,X_hat是增强数据并且是带标签的,U_hat是增强数据并且不带标签。


3.1 Data augmentation
在有标签和无标签数据上都使用数据增强功能。对于标签数据X批次中的每个xb,我们生成一个转换版本xˆb = Augment(xb)。对于一批无标签数据U中的每个ub,我们生成K个增强版本uˆb,k = Augment(ub), k∈ (1, …, K)。
3.2 Label Guessing
对于U中的每一个未标记的例子,MixMatch使用模型的预测结果对该例子的标签产生一个 “猜测”。这个猜测后来被用于无监督的损失项中。为此,我们通过以下方式计算模型在ub的所有K个增量中预测的类别分布的平均值。
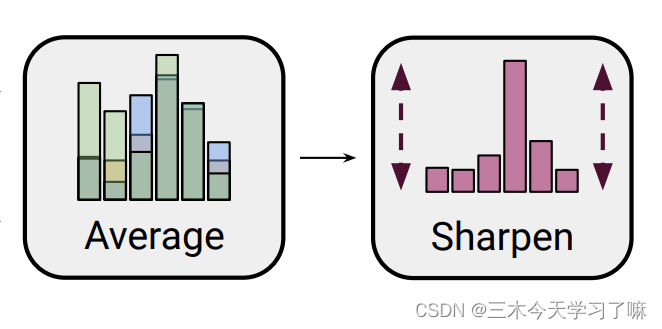
Sharpening锐化: 使得概率分布的方差更小,预测结果更加自洽,系统熵更小。换句人话就是:概率越高的会被拉的更高,低的会更低。





伪代码: 结合图1进行阅读

3.3 3.3 MixUp
4. Experiments
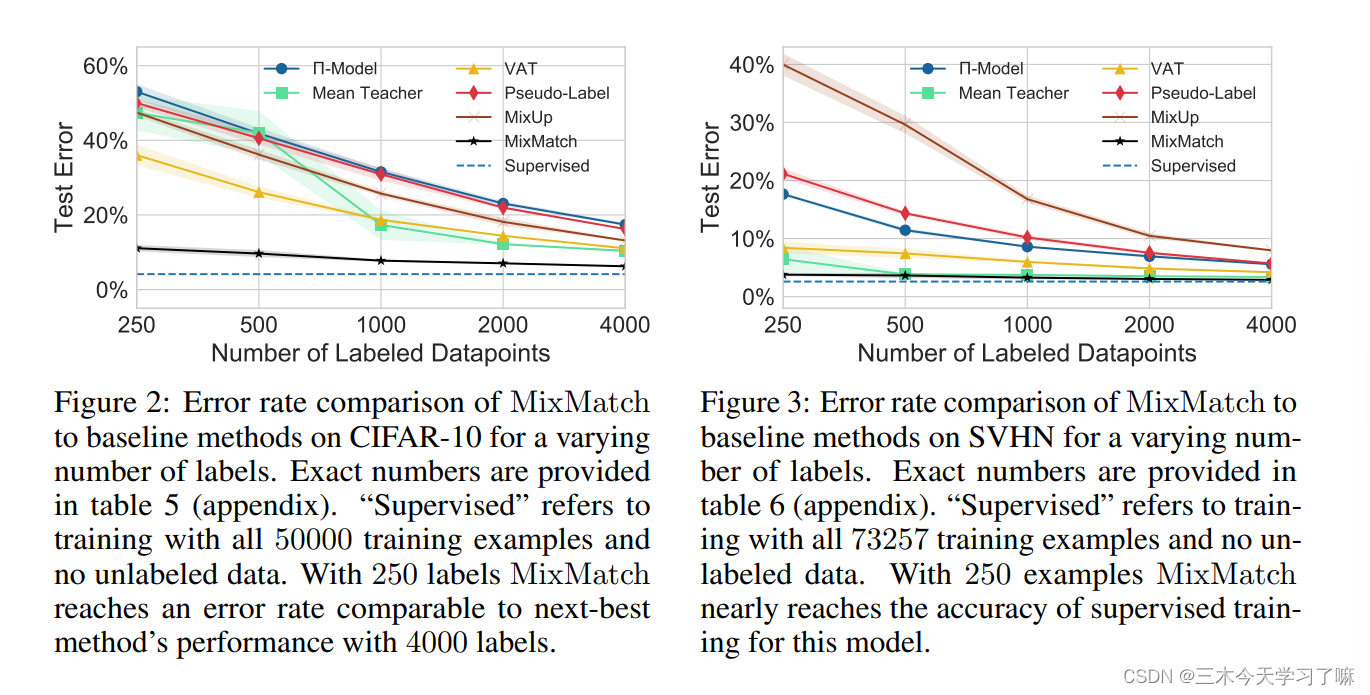
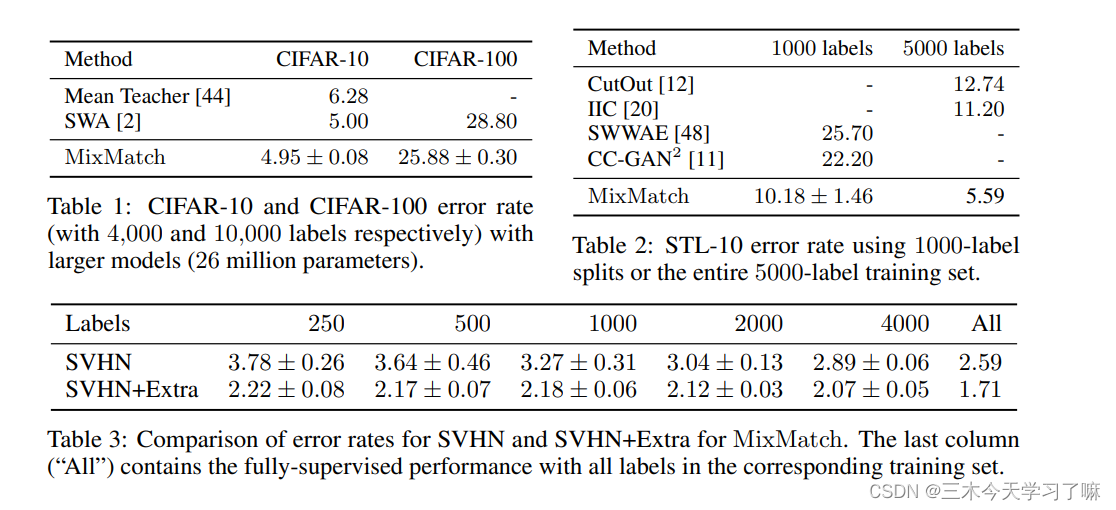
不同方法的比较:
:
解剖各部分贡献 (Ablation Test ):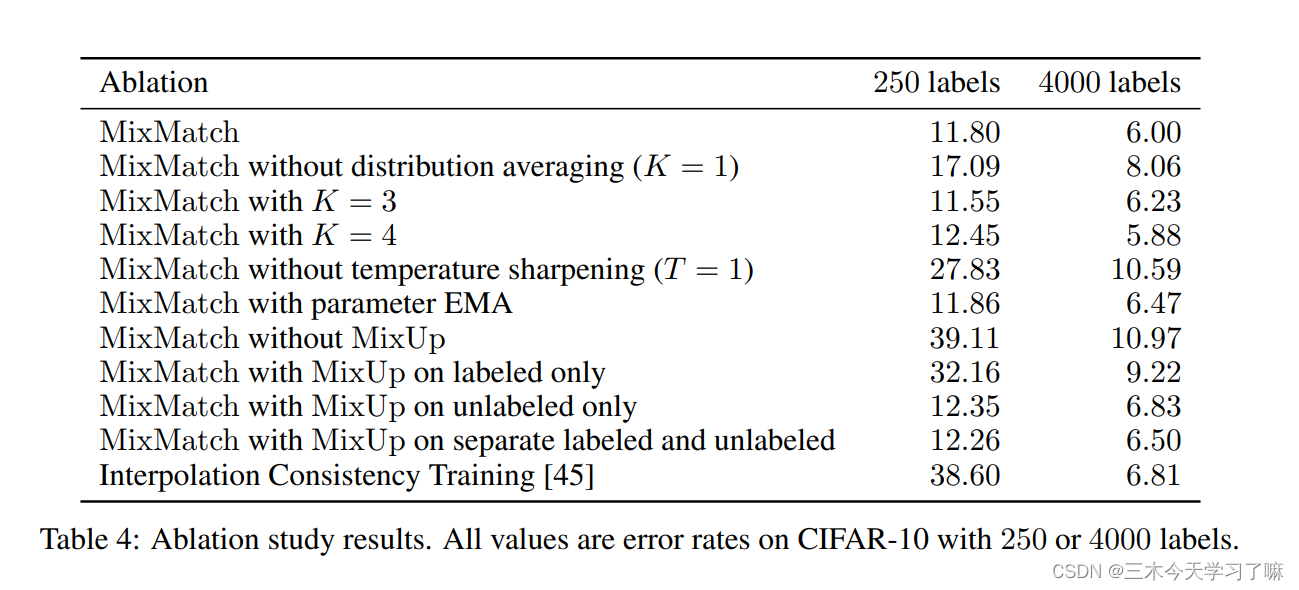
半监督算法结果的对比:
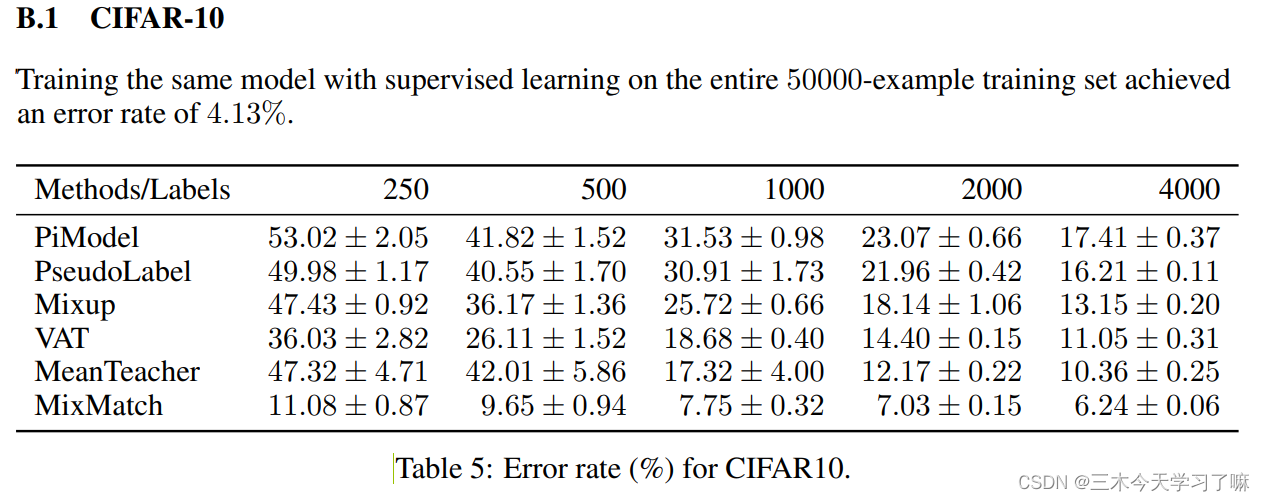
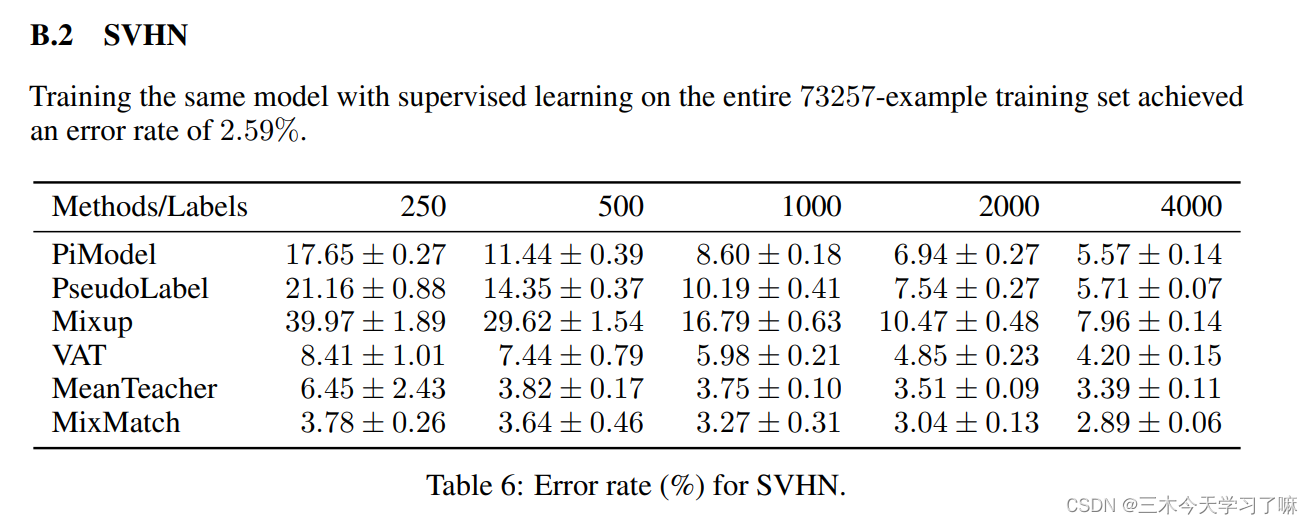
5. Conclusion
MixMatch :创新点总结
( 1 ) MixMatch集成了自洽正则化,在数据增强时使用了对图像进行随机左右翻转和剪切
( 2 ) MixMatch利用Sharpening函数,最小化无标签数据的分类熵。
( 3 ) MixMatch在使用Adam作为优化器,并使用了L2正则化进行权重衰减。
( 4 ) MixMatch使用了Mixup作为数据增强的思想。