会议:2021 icassp
作者:Jordi Bonada, Merlijn Blaauw
单位:西班牙巴塞罗那 Universitat Pompeu Fabra
abstract
idea:提出一种半监督的歌唱合成器,不需要phn的信息,可以仅从音频数据中学到新的voice。
方法:
introduction
传统的TTS或者SVS合成新音色都需要phn对齐的数据,这些都需要人工标注或者自动标注后人工对齐,本文的目的在于仅通过音频数据学到新的音色。
本文将歌唱合成分成两步:(1)pitch model通过lyrics和note生成F0曲线;(2)timbre model通过F0和对齐的phn序列生成最终的声学特征。也有工作将这两步合并,但是作者认为两个过程的限制和需求不一样,因此仍然分开做。
Relation to Prior Work
之前non-parallel VC有一些类似的经验可以借鉴。
- 设计information restrictive BN:通过时间降采样,精心的设定维度,variational regularization,vector quantization;然后与decoder结合,decoder会输入非文本的信息,比如F0, Speaker embedding。
- 可以通过数据增广使得encoder对我们想要过滤的信息更加鲁棒,比如pitch shift,time stretching;
- 可以用negative gradient of an auxiliary classifier 帮助过滤BN中不想要的信息,比如用说话人判别器减少BN中和说话人相关的部分;
- Cycle-consistency 也是一种方法,保证转换中不变信息的可逆性;通常和对抗训练一起用,比如Backtranslation
Proposed Method
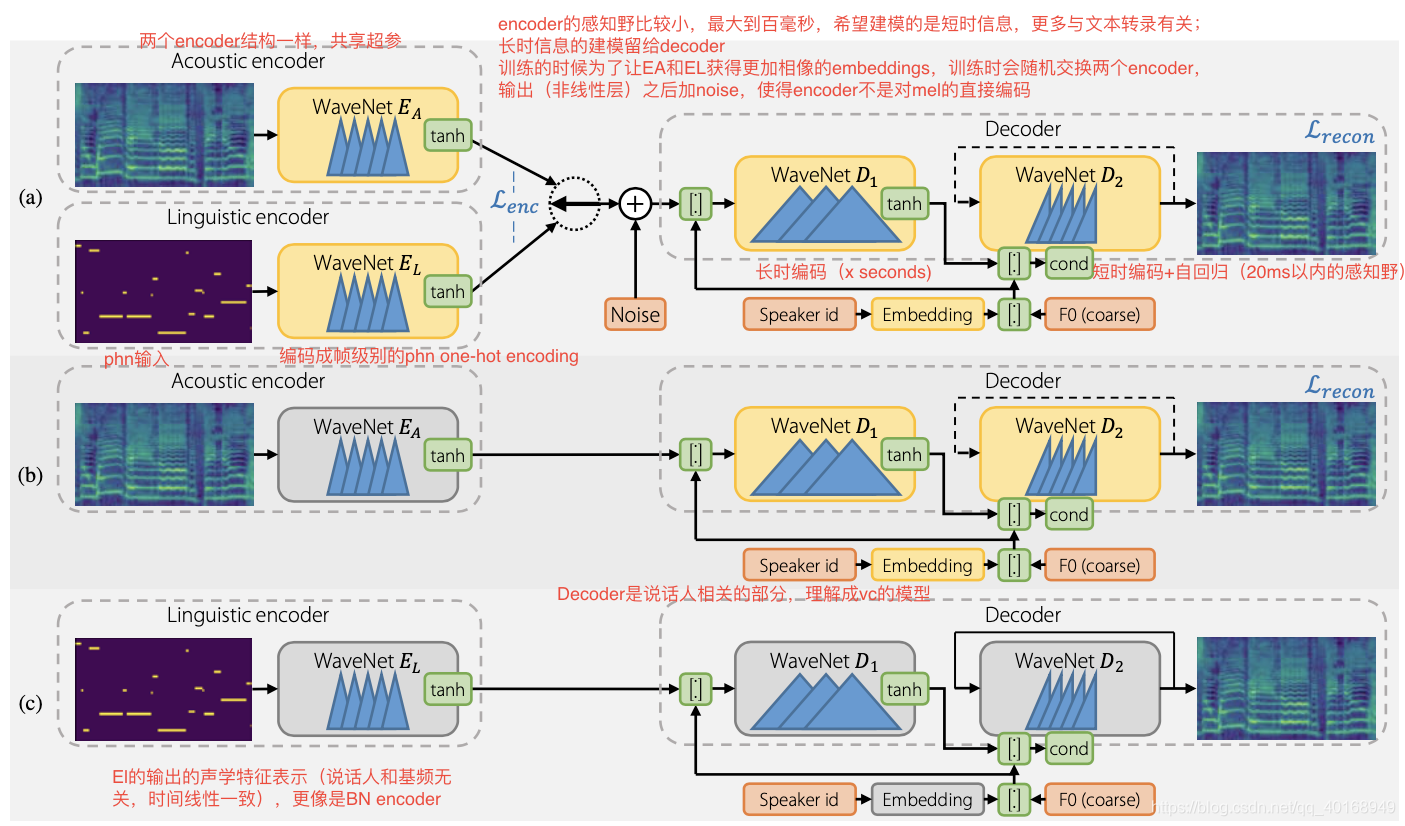
Encoder
- 两个encoder结构一样,且共享超参;encoder的感知野比较小,最大到百毫秒,希望建模的是短时信息,更多与文本转录有关;长时信息的建模留给decoder
- Ea输入是mel;EL输入是phn,输出是帧级别编码的phn one-hot encoding
- 训练的时候为了让EA和EL获得更加相像的embeddings,训练时会随机交换两个encoder,输出(非线性层)之后加noise,使得encoder不是对mel的直接编码
Decoder
有long-scope和short-scope两种形式,D1用于编码长范围(x seconds)量级的音色变动;D2用于生成音色输出的细节;
- vowels有的可能持续数秒,因此需要D1中大的感知野捕捉phn context。D1是非因果的,输入是encoder_output+F0+Speaker embedding
- D2是自回归的卷积结构,感知野范围小于20ms,input=上一帧mel + D1 outputs+F0+speaker embedding
Training loss
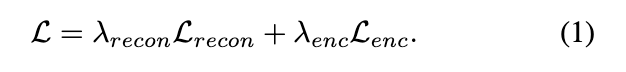
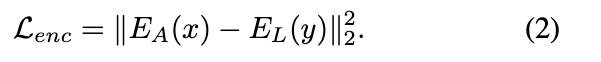
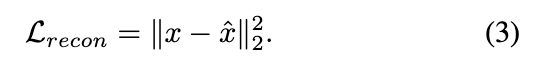
- x是mel特征表示;
- y是文本特征
Data-augmentation for improved invariance
将信号进行时域线性放缩,并且移动基频。但是文本是不变的,输出相似的acoustic embdding,可以帮助linguistc encoder建模speaker and pitch independent embedding。
experiment
(a) train stage: 7个人10首歌,5h47
(b) finetune:一个人41首歌,2h7用于finetune decoder;另外测试只使用3min的数据finetune的效果