bmvc 2019
motivation
more attention paid on two types of hard samples:
- hard-to-learn samples predicted by teacher with low certainty
- hard-to-mimic samples with a large gap between the teacher’s and the student’s prediction
ADL
- enlarges the distillation loss for hard-to-learn and hard-to-mimic samples and reduces distillation loss for the dominant easy samples
- single-stage detector
However, when applying it on object detection, due to the ”small” capacity of the student network, it is hard to mimic all feature maps or logits well.
two-stage detector
- Learning efficient object detection models with knowledge distillation , 2017
weighted cross-entropy loss to underweight matching errors in background regions - Mimicking very efficient network for object detection , 2017
mimicked feature maps between the student and the teacher pooled from the same region proposal and discarded those from uninterested regions - Quantization mimic: Towards very tiny cnn for object detection , 2018
introduced quantization mimic to reduce the search scope of the student network
focus on mimicking informative neurons of the teacher network
single-stage detector
- needs to process much more samples due to the setting of dense anchors
- Without the region proposal network (RPN), sample imbalance between easy and hard samples is a special challenge
Adaptive Distillation
总体 loss
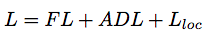
original focal loss
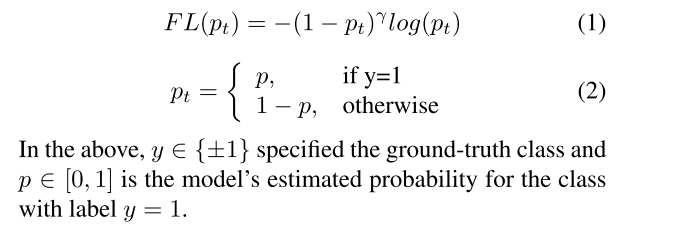
KL
在KL Loss的基础上加了一个Focal loss项
- q as the soft probability value predicted by the teacher
- p as the one predicted by the student
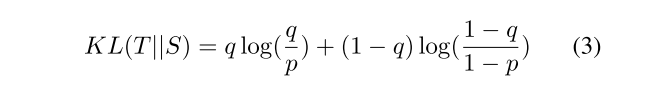
Focal Distillation Loss
joint loss of classification loss and KL

the focal distillation loss
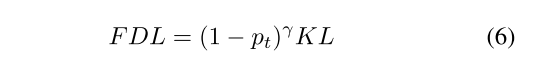
FDL is dominated by the focal term FL, so KL contributes little to the overall loss.
ADL —— Adaptive Distillation Loss
融合了 focal loss 思想的 KL loss
distill weight
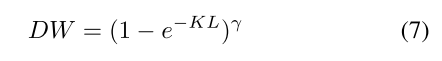
γ controls the rate at which easy examples are down weighted
(1−e−KL) controls the weight of each sample
ADW
to adjust the percentage of overall weights of hard-to-learn samples (PHLS)
PHLS increases when β becomes larger
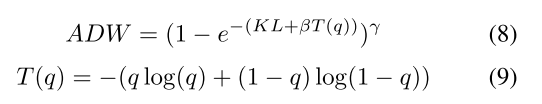
T(q), the entropy of the teacher, reaches maximum when q is 0.5 and minimum when q approaches 0 or 1
When q approaches to 0.5, the corresponding sample is treated as a hard-to-learn sample
a sample with a high KL is treated as a hard-to-mimic sample
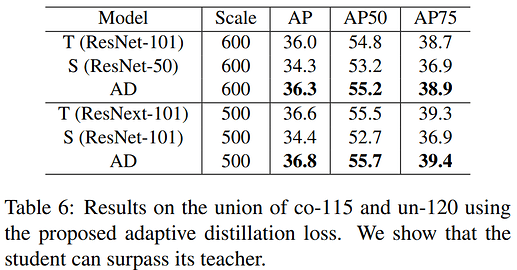
In conclusion
- KL controls the weights of hard-to-mimic samples which are adjustable in the training process
- T(q) controls the weights of hard-to-learn samples initially defined by the teacher
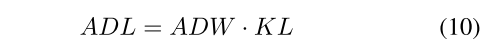
normalizer
To make the KD training more stable and robust, we define the normalizer
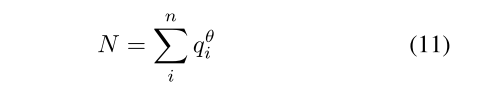
The mark q correspond to soft targets of positive samples predicted by the teacher
N is the sum of probability of positive samples powered by θ over all anchors
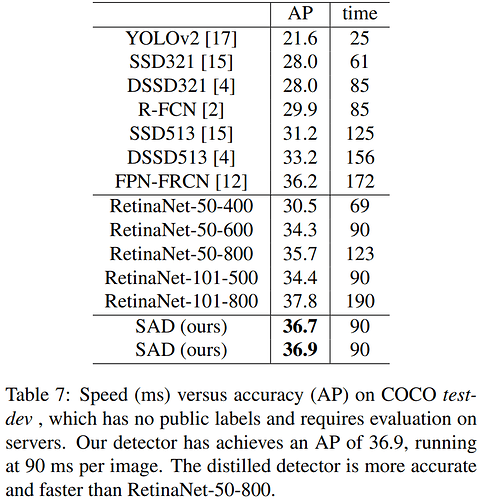
result