Self-aware and Cross-sample Prototypical Learning for Semi-supervised Medical Image Segmentation, MICCAI2023
解读:MICCAI 2023 | SCP-Net: 基于一致性学习的半监督医学图像分割方法 (qq.com)
论文:https://arxiv.org/abs/2305.16214
代码:暂未开源
摘要
在半监督医学图像分割中,一致性学习表现得非常重要,因为它能够利用有限的注释数据和丰富的未注释数据。但其有效性和效率受到预测多样性和训练稳定性的挑战,而这些往往被现有研究所忽视。同时,用于训练的有限的标记数据往往不足以形成伪标签的类内紧性和类间差异。为解决上述问题,
- 本文提出了一种自感知和跨样本原型学习方法(SCP-Net),通过利用来自多个输入的更广泛的语义信息来增强一致性学习中预测的多样性。
- 引入了一种自感知的一致性学习方法,利用未标记数据来提高每个类中伪标签的紧凑性。
- 在交叉样本原型一致性学习方法中集成了双重损失重新加权方法,以提高模型的可靠性和稳定性。
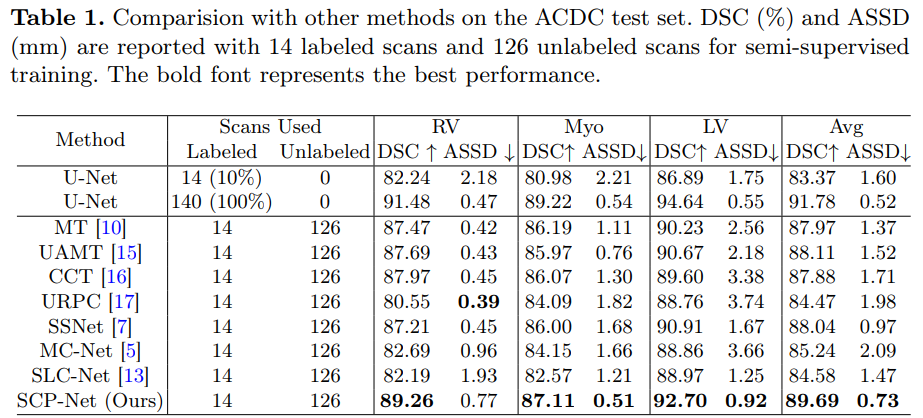
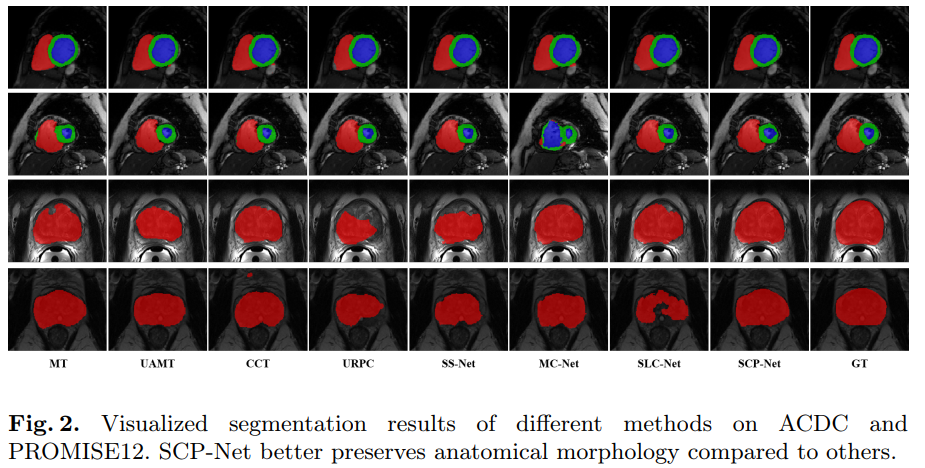
在ACDC数据集和PROMISE12数据集上进行的大量实验验证了SCP-Net优于其他最先进的半监督分割方法,并与有限的监督训练相比实现了显著的性能提升。
引言
先前的研究忽略了考虑预测结果对扰动的稳健性和可变性。为了解决这一问题,论文引入自感知和跨样本类原型,生成两个不同的原型预测,以增强语义信息交互,并确保一致性训练中的分歧。
还使用自感知原型预测和多重预测之间的预测不确定性来重新加权交叉样本原型的一致性约束损失。这样,不仅可以减少标签噪声在低对比度区域或粘合边缘等具有挑战性的区域中的不利影响,从而实现更稳定的一致性约束训练过程,还能提高模型的性能和准确性。最后,论文提出了SCP-Net,一个无参数的半监督分割框架,它结合了两种典型的一致性约束。
方法
SCP-Net网络的目标是通过从未标记的数据集Du中提取额外的知识来提高模型的分割性能。
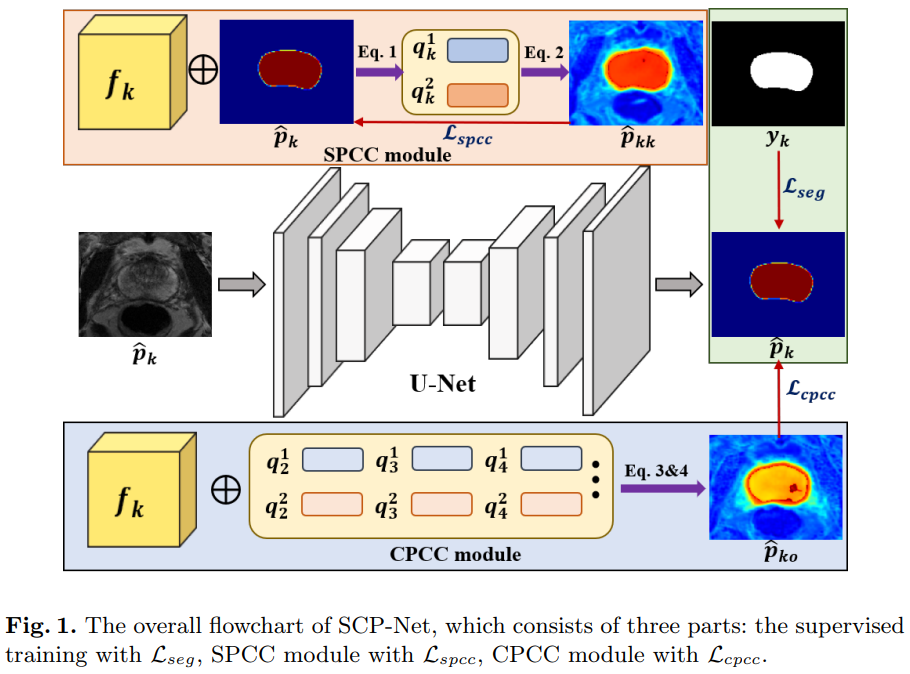
SCP-Net主要部分在于SPCC模块和CPCC模块。
Self-Cross Prototypical Prediction
分割中的原型是指对特定对象或类的一些像素特征的共同特征进行聚合表示。类原型定义为:

训练过程中,一个小批次包括原型和其他样本。然后,根据自感知原型或交叉样本原型计算特征相似度,形成多个分割概率矩阵。具体为,计算特征图f和原型向量q间的余弦相似度,通过对齐,可确保预测的类内一致性。
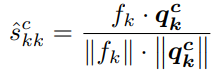
同理,可获得交叉样本原型的相似性图。
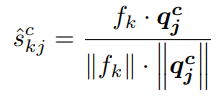
确保特征被关联且信息以交叉图像的方式被交换。为提高预测的可靠性,考虑多个相似性估计,并进行积分,得到交叉样本概率预测。
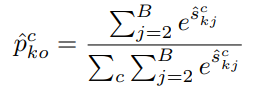
Protypical Prediction Uncertainty
为了有效地评估半监督环境中的预测一致性和训练稳定性,论文提出一种基于相似矩阵和
的原型预测不确定性估计方法。
- 首先,通过argmax运算和one-hot编码生成B个二进制表示的掩码
,其中n=1,2,···,B。
- 然后,对所有掩码求和,并将其除以B,得到归一化概率
。

- 再计算归一化熵
,其根据
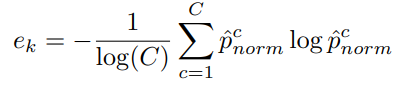
其中ek是多个原型预测的总体置信度,熵越大,预测的不确定性就越大。再使用ek来调整标记和未标记样本的逐像素权重。
Unsupervised Prototypical Consistency Constraint
为了增强一致性学习中的预测多样性和训练有效性,并减轻和
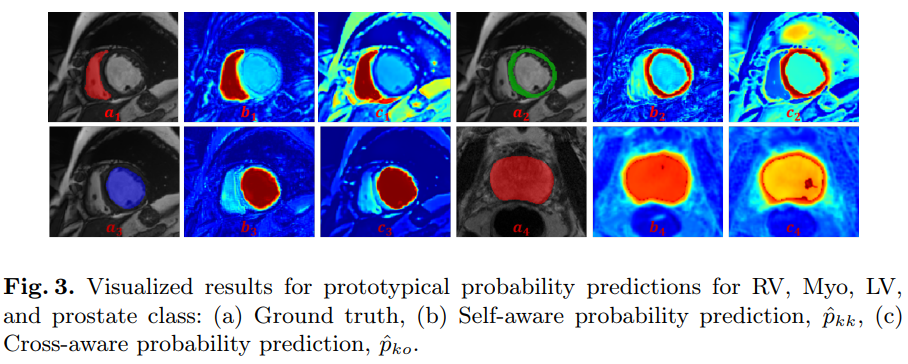
中有噪声预测的负面影响,SPC-Net提出两个无监督的原型一致性约束(PCC),这两个约束得益于自感知原型预测
、交叉样本支持原型预测
和相应的不确定性估计
。
Self-aware Prototypical Consistency Constraint (SPCC)
自感知原型一致性约束(SPCC)旨在增强分割预测的类内紧密性。它利用自感知原型预测作为伪标签进行监督。通过使用自感知原型,该方法能够在样本上对特征进行更准确的对齐,从而确保预测的类内一致性。引入这个约束,模型能更好地学习到类别内部的共性特征,提高分割性能。SPCC损失为:
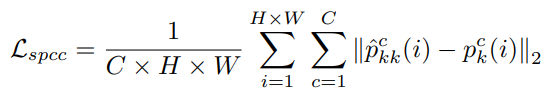
Cross-aware Prototypical Consistency Constraint (CPCC)
跨样本感知原型一致性约束(CPCC)旨在从其他训练样本中获得可靠的知识。它采用双重加权方法,通过考虑不确定性估计和自感知概率预测来调整约束的权重。
首先,使用不确定性估计来降低可疑伪标签的影响,减少这些具有较大不确定性的区域在训练中的权重。其次,引入自感知概率预测,计算在特定类别上的最大值作为权重,进一步增强CPCC的可靠性。通过这种双重加权方法,CPCC能够更好地利用跨样本的原型预测来提升分割模型的性能和稳定性。
CPCC的优化函数是在两个交叉感知原型预测中进行计算:
![]()
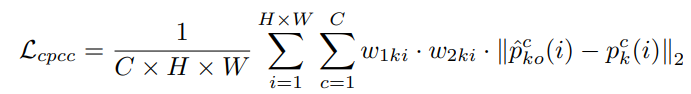
Loss Function of SCP-Net
有标签数据的分割损失由ce和Dice组成:
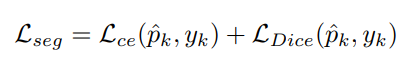
对于标记数据和未标记数据,利用Lspcc和Lcpcc为网络训练提供无监督一致性约束,并探索有价值的未标记知识。SCPNet的总体损失函数是有监督损失和无监督一致性损失的组合:

实验