BN算法在很大程度上加速了训练过程,放宽了网络初始化的条件,论文中还提出有了BN可以在不使用Dropout,同时也可以在一定程度上提升网络的识别效果,在之后的ResNet等等新网络中有广泛的应用。
1、Feature scaling:
目的:Make different features have the same scaling
例如:
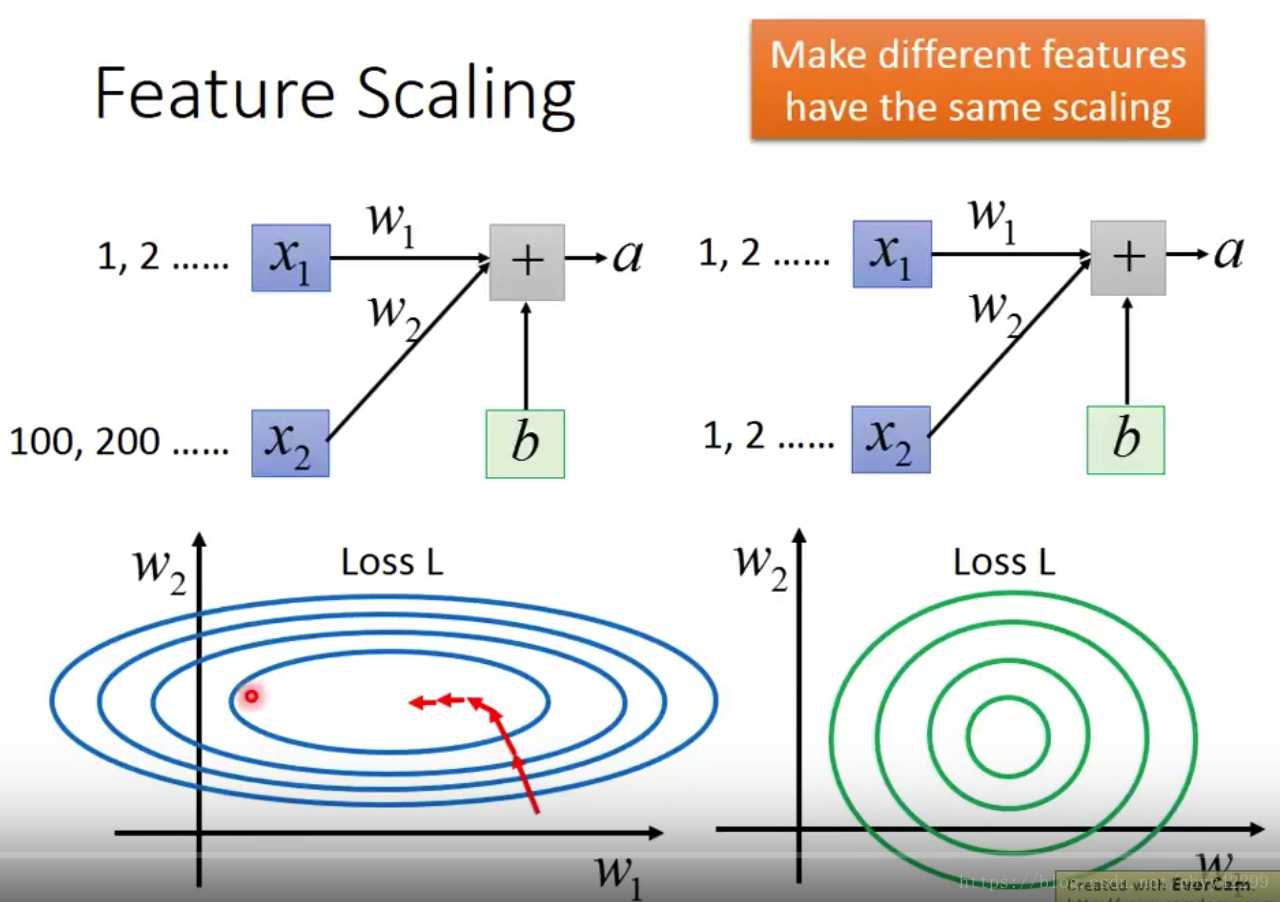
在左上图中,假设X1和X2的缩放差距比较大,假设X1和X2对结果的重要性是一样的,我们将W1和W2对应的损失关系拿出来做图可以看到:
a、在w1方向上,它的斜率比较小,w2方向上比较大;所以会导致loss在这两个方向上的优化速度不同,也就会导致在w1方向需要比较大的学习率,在w2方向需要比较小的学习率
b、我们将x1和x2做缩放后,使得误差面比较接近正圆;
2,怎么做feature scaling:
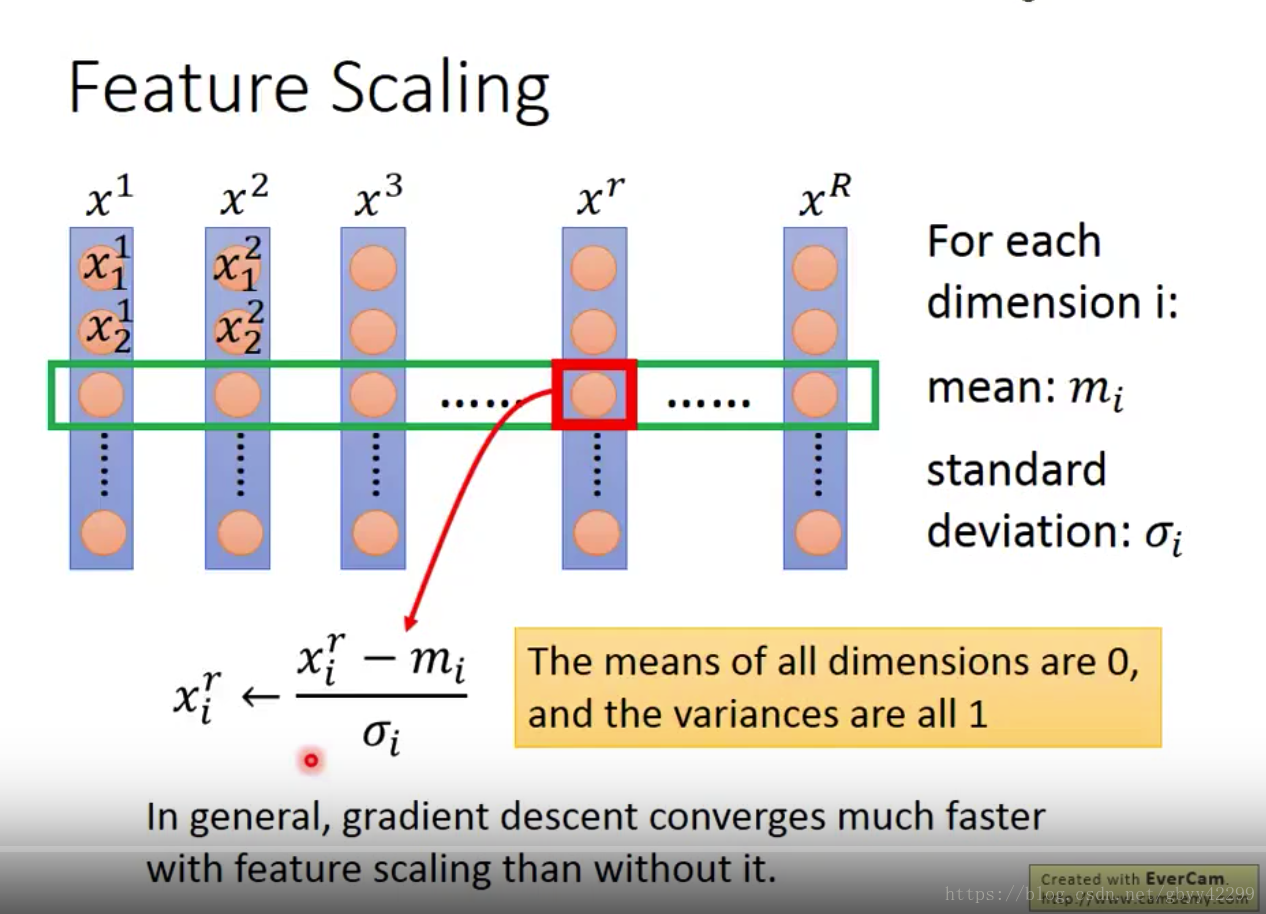
假设每个x都是39维,那么我们就可以算出来39个意思和39个std。做了feature scaling之后会让训练收敛速度加快。
3,深度学习中怎么做feature scaling(batch normalization):
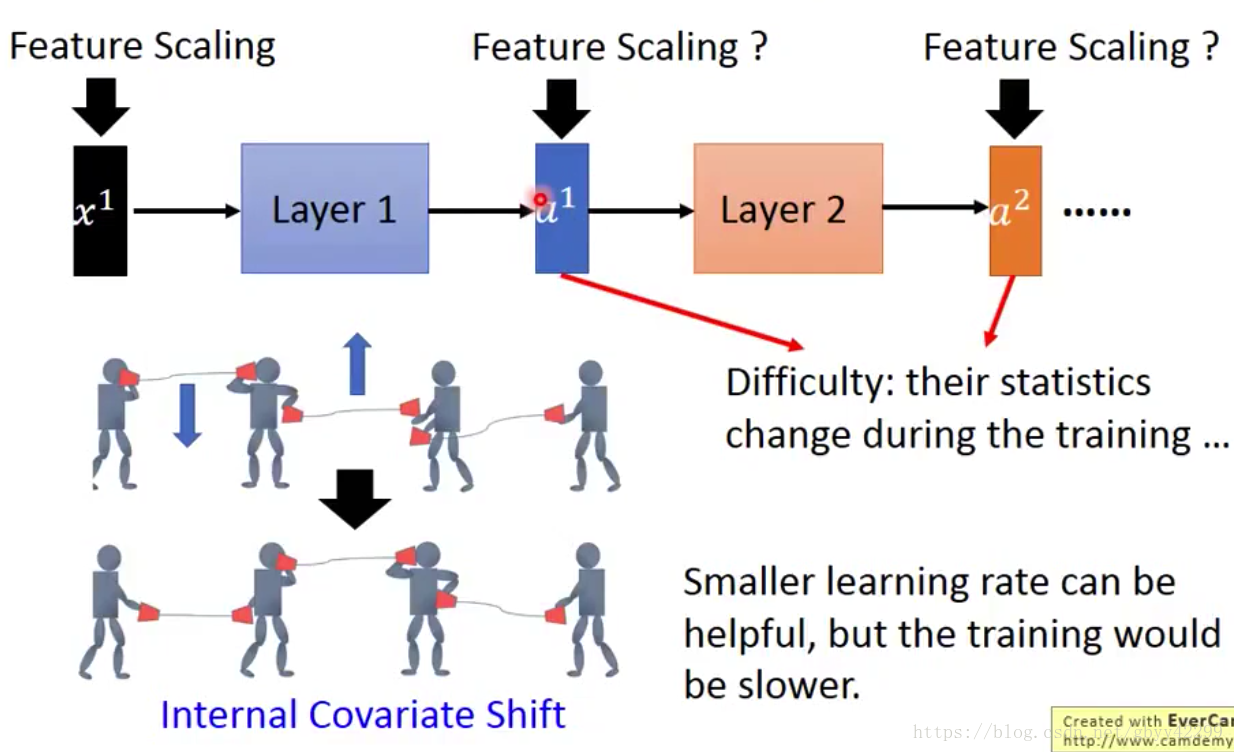
对于每一个层做缩放是非常有用的,它可以解决Internal convariate shift的问题,什么是internal convariate shift呢?
内部协变:在深度网络的训练中,每一层网络的输入都会因为前一层网络参数的变化导致其分布发生改变,这就要求我们必须使用一个很小的学习率和对参数很好的初始化,但是这么做会让训练过程变得慢而且复杂,这种现象成为ICS比如下图所示:我们使用BN可以确保每一层的统计数据都根据自身的一批变化。
4,深度学习中怎么做BN:
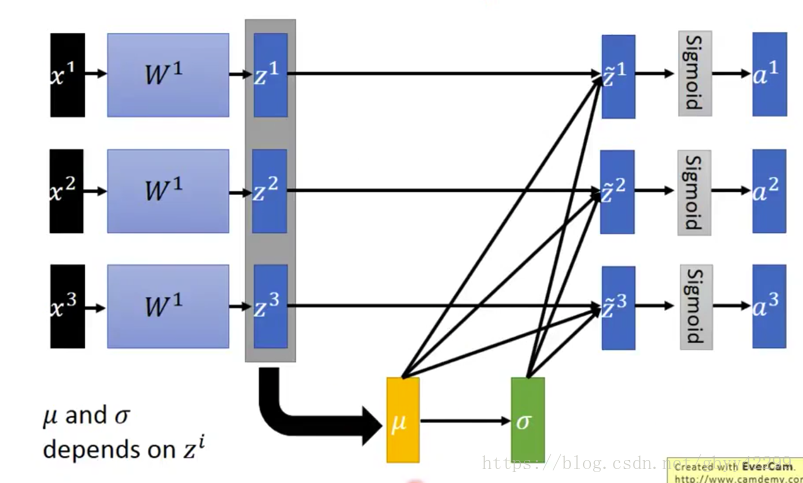
先做bn再做激活,为什么这么做呢?因为先做bn,能够确保在进入激活功能之前能够保证落在0的附近。
比如我们有一个批次里面包括3个样本X1,X2,X3,如下图位:Z为活化之前的输入,一个为激活的输出。
note:bn不能够用在比较小的batch数据下,因为如果你的batch很小的话,它没有办法从一个batch里面很好的估计出整个training set的mean和std。比如batch size=1。
首先我们计算整个batch的mean和std。
问题:有bn层的时候怎么做backpropogation?
如上图所示,bn在做backpropogation的时候会经过mean和std这两个参数,bp会改变w参数,从而会改变z,进一步会导致mean和std的改变,所以在training的过程中mean和std并不能简单的当作是constant来考虑,z对mean和std的影响是会在training的过程中被考虑进去的。
如下图所示:beta和gama都是超参数,当gama=std,beta=mean的时候相当于没有做事,但是不一样的在于:mean和std收到input date的影响,但是beta和gama是independence的,他们是network在training的过程中学到的,和input data无关。

5、bn在training的时候的完整过程:
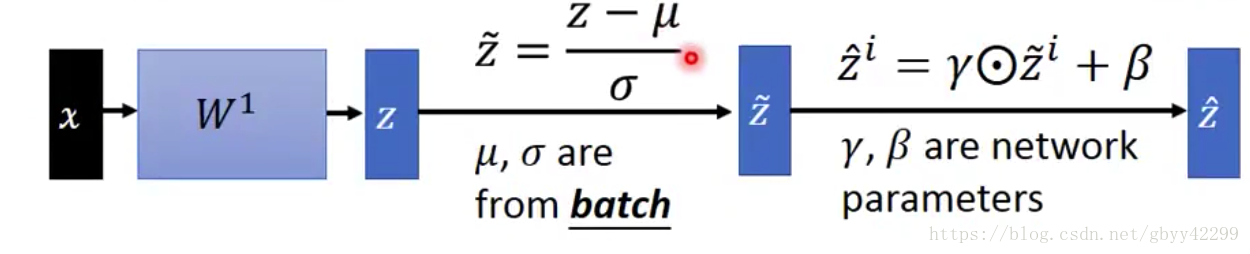
6、bn在testing的时候的完整过程:
testing的时候我们没办法算mean和std,因为training的时候我们可以算出一整个batch的mean和std,但是testing的时候只有一笔data进来,我们没办法估算出mean和std。解决方法:
training的过程中,我们把每个batch的mean和std都算出来,如下:

随着acc的上升,mean300 和mean 1这两个参数差异比较大,mean300和实际的mean差距不大,但是mean1差距较大,所以我们会给training结束的时候的weight比较大,开始的时候的weight比较小。采用滑动平均的方法。
7、bn的能解决的问题/bn的好处(优点):
a,bn可以解决internal convraiate shift,所以我们可以适当的使用较大的学习率,减少训练时间;
b,能够解决梯度消失和爆炸的问题。例如:我们采用sigmoid作为activation function我们很容易遇到梯度消失的情况,因为如果输入的值落在很大或者很小的地方的话,很容易导致梯度消失,但是如果加了BN,我们就能保证输入的值落在0附近,梯度都比较大的地方。
C,能够降低对参数的初始化影响例如:我们把瓦特乘以ķ倍的话:

d,能够对抗overfitting。因为加入bn相当于做了regularization,我们把所有的特征normalizer到固定的意思,在测试的时候如果有一个噪声进来的话让mean有一个shift,但是做了bn后可以把normolize回来。
总结:

看粉红色的线:sigmoid如果没加bn的话可能是train不起来的。