前言:
{
Deeplab目前最新的版本是V3+,这个系列一直都有不错的语义分割表现,所以这一次我还是选择了它来了解一下。
论文地址:https://arxiv.org/pdf/1706.05587v1.pdf(Deeplab V3);和https://arxiv.org/pdf/1802.02611.pdf(Deeplab V3+)
}
正文:
{
Deeplab V3:
{
在第一节,作者介绍了4种解决目标多尺度问题的结构,如图2。

第三节介绍了主要的改动。
串行的空洞卷积模型变得更深了,如图3。

并行的空洞卷积模型如图5。

其中block是ResNet里的block,模型也是根据ResNet修改的,并且加入的两个1*1的卷积操作都具有256个过滤器和batch normalization。
可以看到,条件随机场(CRF)被去除了,并且模型比较简洁易懂。
第四节介绍了相关实验。
这次 learning rate的更新方式是上次提到的新方式“poly”:learning rate*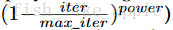
batch normalization的batch size为16,其参数学习的初始learning rate为0.007、decay为0.9997。
在trainaug数据集上迭代训练了30000次后,冻结batch normalization参数,并且在PASCAL VOC 2012 trainval数据集上,以基础learning rate 0.001继续训练30000次迭代。
stride的设置我没搞明白,只是了解到了它表示输入图片与feature map的大小比值(https://blog.csdn.net/baidu_32173921/article/details/79172408中的问答),但是不知道其他的stride怎么改。
这一次不再缩小标签图了,而是放大了输出图,并且进行了数据扩增。
不同结构的结果如表2,表3和表4。
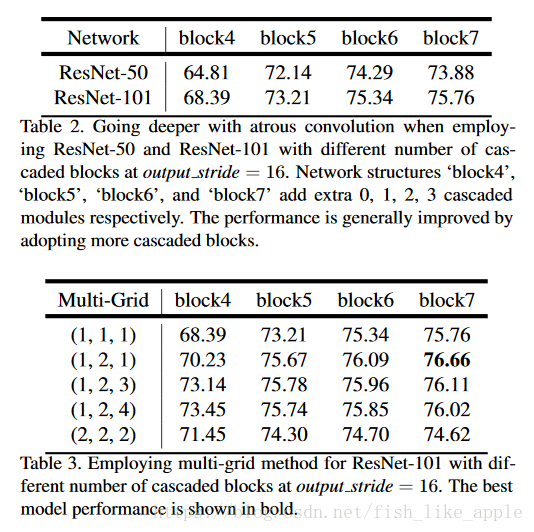

可以看到,基本上网络越复杂,数据处理的越多,效果越好。Multi-grid其实是rate的基数。
并行模型的效果如表

并行模型比串行的效果稍好。
作者做了先串行后并行的模型的实验,但效果没什么明显提升。
各种方法对比结果如表7。
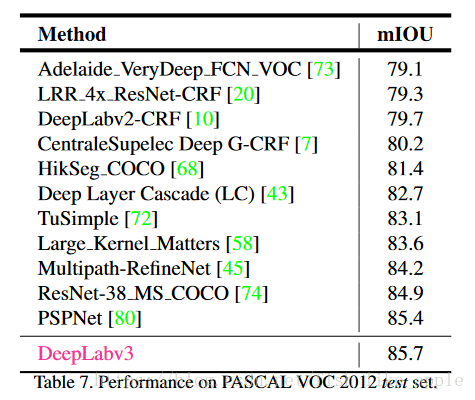
}
Deeplab V3+:
{
第一节首先介绍Deeplab当前的缺陷,即输出图放大的效果不好,信息太少,因此提到了编码-解码结构。见图1。
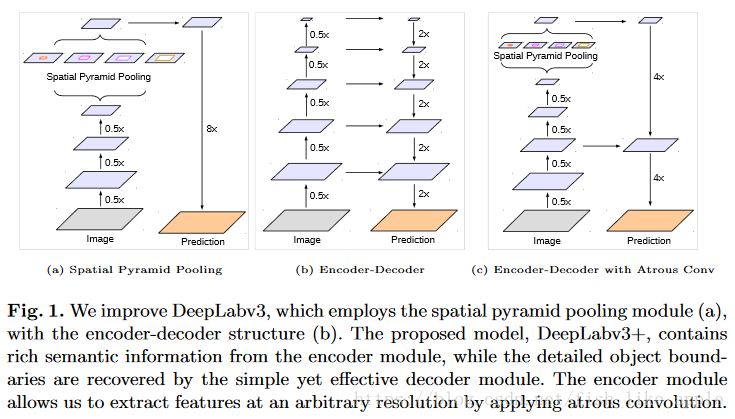
新结构简洁明了,就是把中间一层的特征图用于输出图放大。
选择编码-解码结构是因为这是一种比较快的输出图信息扩充方法,如果只是增加各个层的维度,则会大幅降低运行速度。
更具体的网络结构如图2。
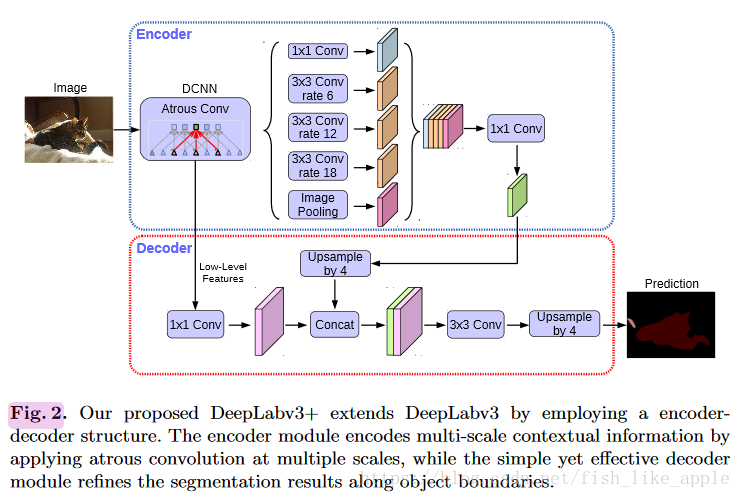
第三节做了具体介绍。
这里提到之前Deeplab V3的输出图放大使用的是双线性插值,这次Deeplab V3变成了Deeplab V3+的编码器,并且加了一个解码器,见图2,其中上采样为双线性插值。
DCNN部分出现了新的选择:修改后的Xception,其结构如图4。

其中的Sep Conv是深度可分离卷积(Depthwise separable convolution)(详见:https://zhuanlan.zhihu.com/p/28186857)。
第四节是实验评估。
表1和表2介绍了不同解码器配置对应的结果。

值得注意的是,更复杂的解码器不一定代表更好的效果。
不同编码器配置的效果如表3(使用ResNet-101)。

当使用改进的Xception作为编码器时,训练的相关参数也不一样了:使用Nesterov momentum优化器,momentum = 0.9,初始 learning rate = 0.05,decay = 0.94 (每 2 个epoc decay 一次),weight decay = 4e−5,batch size = 32,image size = 299×299。结果如表5。

其SC,COCO和JFT分别为不同数据集。可以看到,这种方案效果更好,并且数据越多效果越好。
各种方法的横向比较见表6。
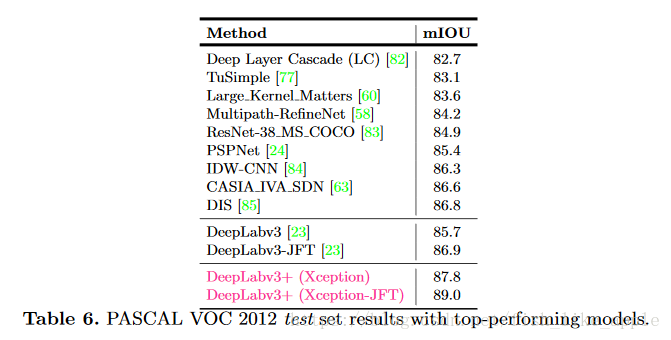
名副其实的the state of the art。
}
}
结语:
{
关于图5的测试,我没有搞明白其中的Trimap Width,Trimap的相关信息可以参考:https://blog.csdn.net/blueswhen/article/details/22617631?locationNum=10。我认为Trimap Width就是标签图的形态学扩展的幅度。

看样子DCNN部分还可以进行相关的改动,之后我会去对于的github上下载代码来调试一下。
都是自己的理解,也跳过了不少部分,有问题可以在评论里问我(如果有人看的话)。如有不当的地方,欢迎指点。
}