python爬取多页商品评论
目的:练手爬虫爬取商品评论,一是因为示例代码有问题正好重写功能,二是回顾一下发现这是python爬虫学习中很经典的一个场景,顺便把全流程记录下来供大家参考学习
目标界面
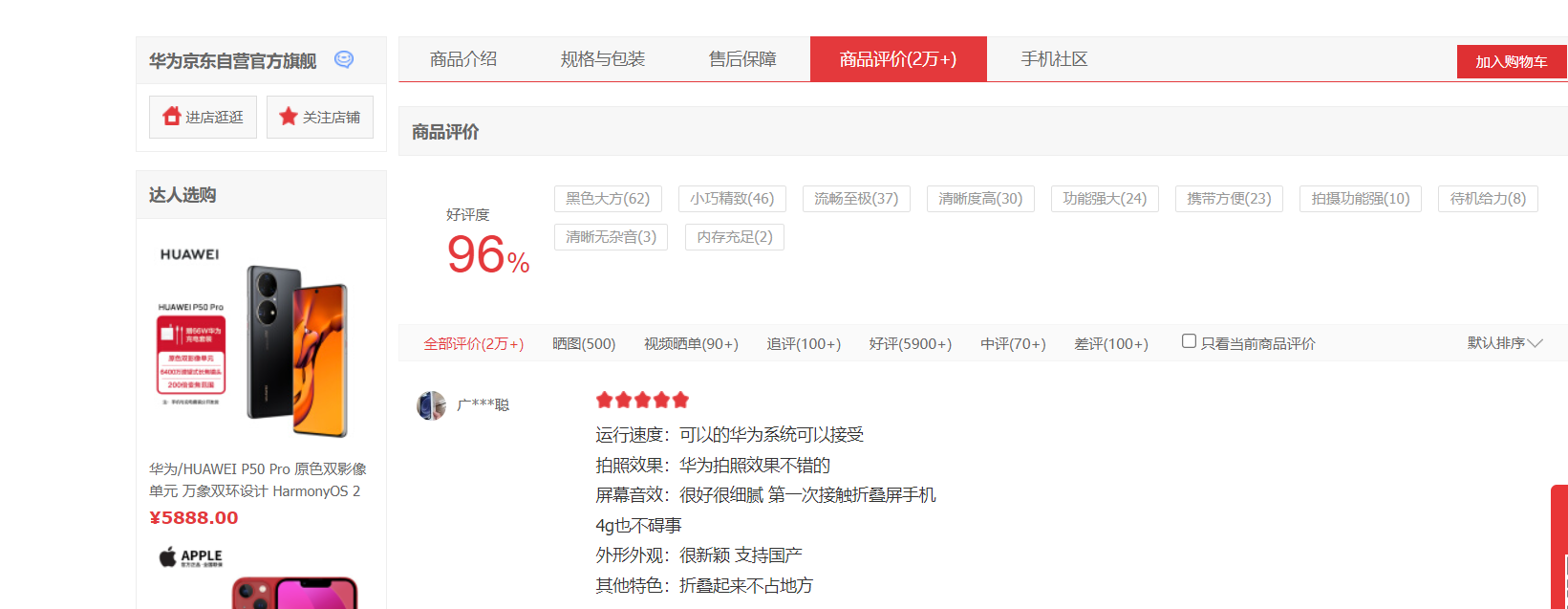
开发者工具找到评论所在界面代码中位置
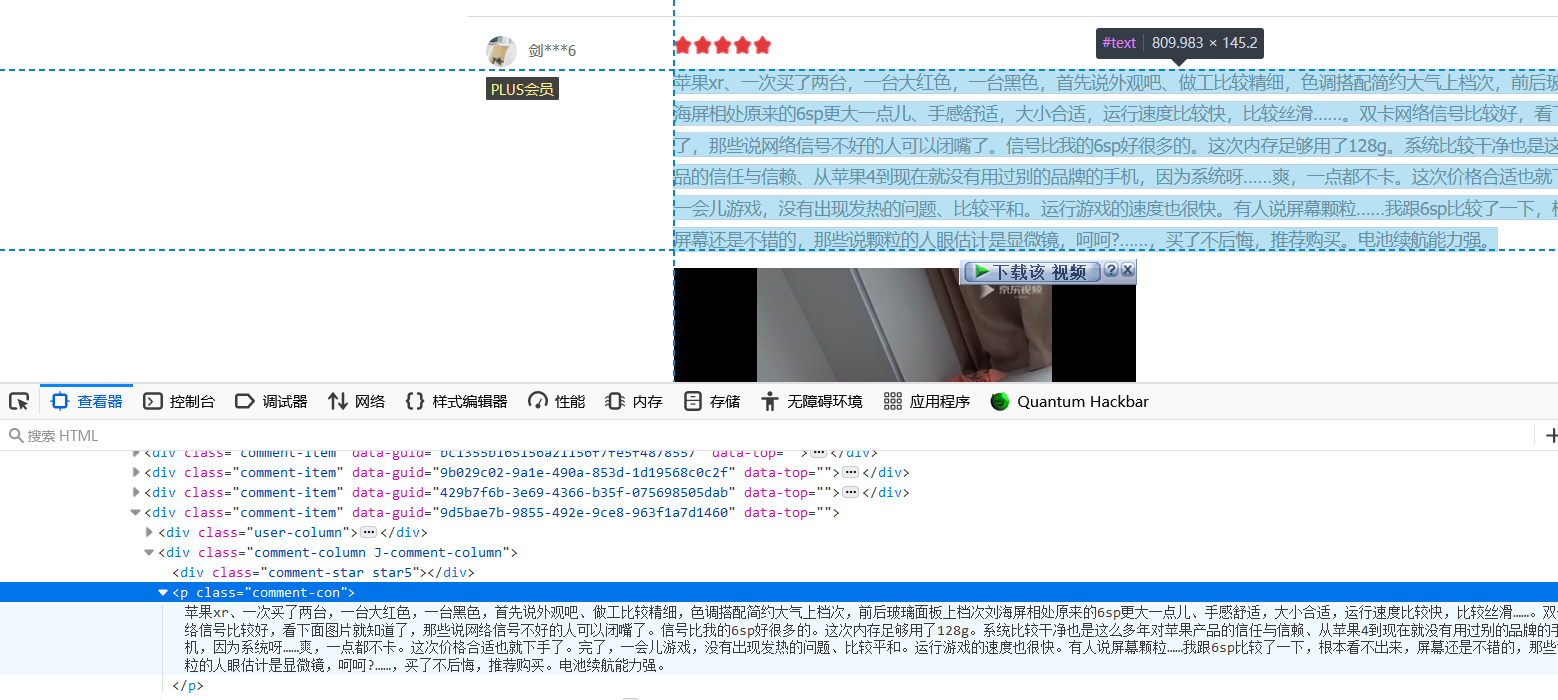
但是查询发现经网页渲染后代码中不存在评论(顺便省的selenium再爬一遍)
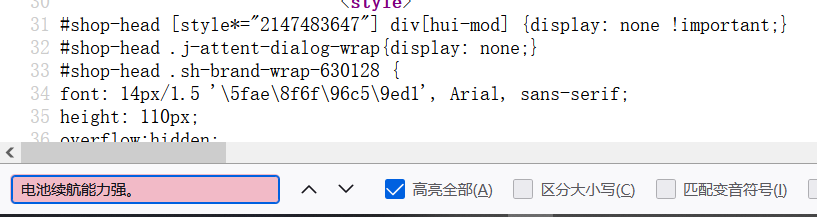
那就得找找网页藏哪去了
继续在网络传输中找请求资源内容
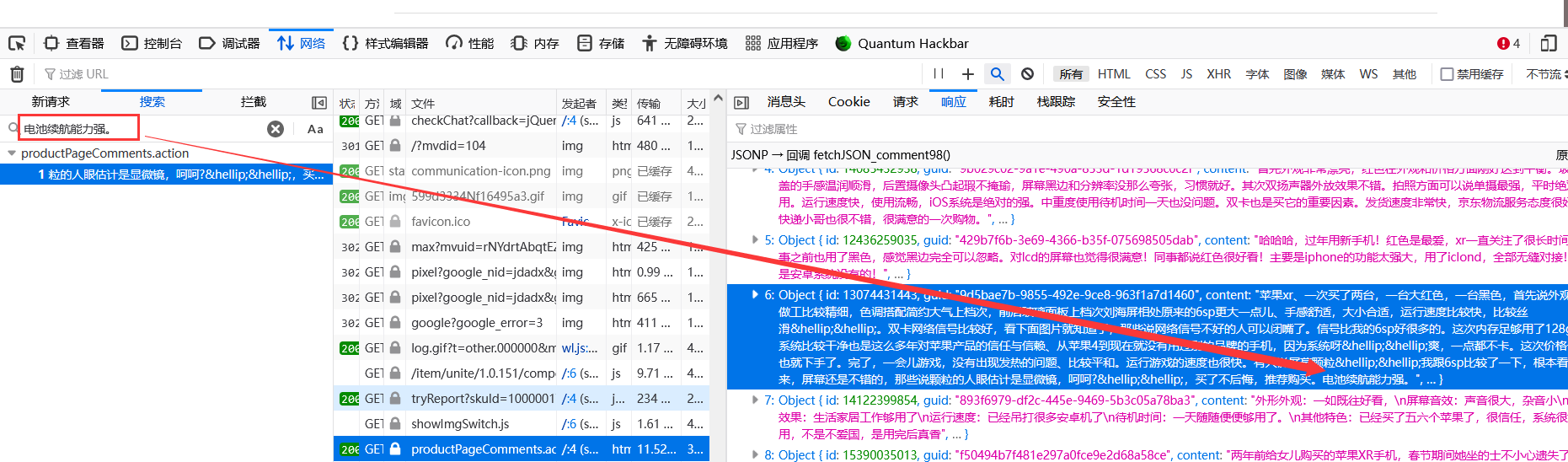
小黑子,终于露出鸡脚了!
这里的反爬措施是用.action文件传输json对象数据报文从而避免源码中包含数据
找到其.action网址

剩下就是数据清洗筛选和一些逻辑处理了
本身.action传输的都是明文数据,效率起见,这里直接是拿requests来爬取,结果数据都没拿到
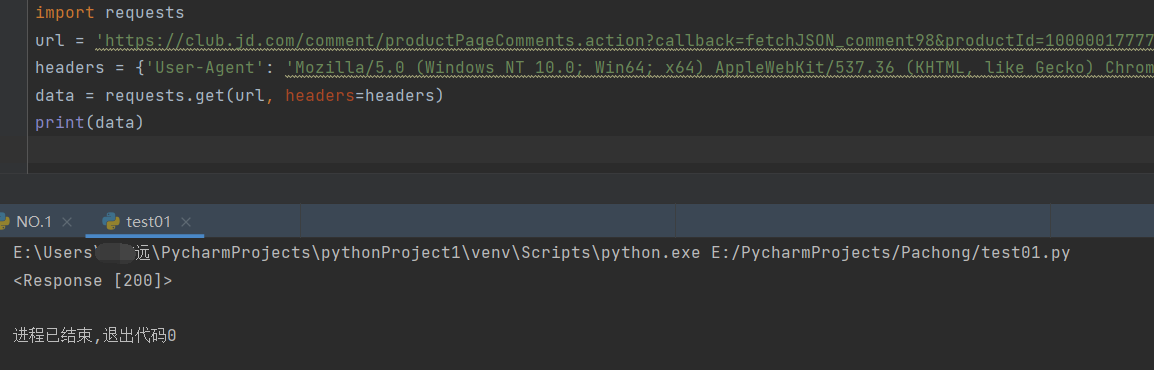
可能是某种接口反爬
换selenium试试
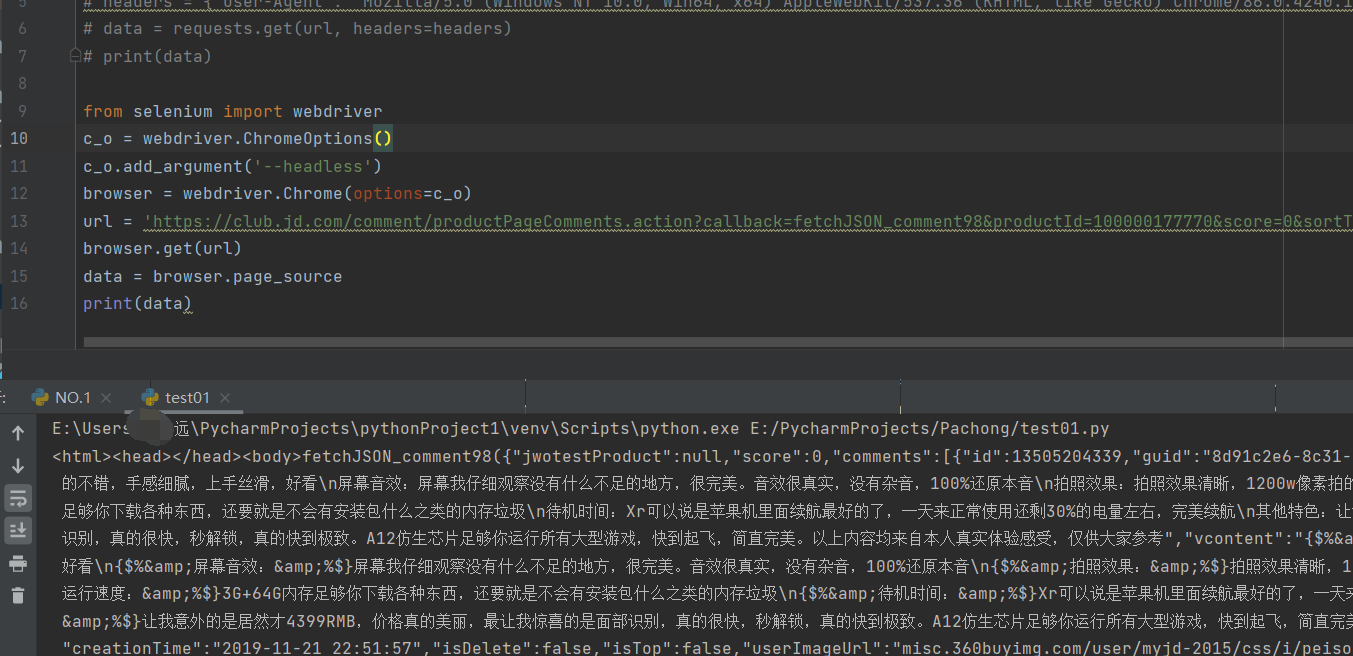
运行正常
稍微实验一下显然可得是靠最后的fold参数决定接口文件界面

完整爬取n页代码如下
from selenium import webdriver
import re
url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100000177770&score=0&sortType=5&pageSize=10&isShadowSku=0&fold=1&page='
rs_all = '' #所有爬取界面源码整合
for i in range(8):
print("正在无界面循环爬取第 %d 页,请等待"%i)
c_o = webdriver.ChromeOptions()
c_o.add_argument('--headless')
browser = webdriver.Chrome(options=c_o) #无界面爬取ChromeOptions选项设置
browser.get(url+str(i))
data = browser.page_source #获取每页源码并赋值
rs_all += data #n页叠加
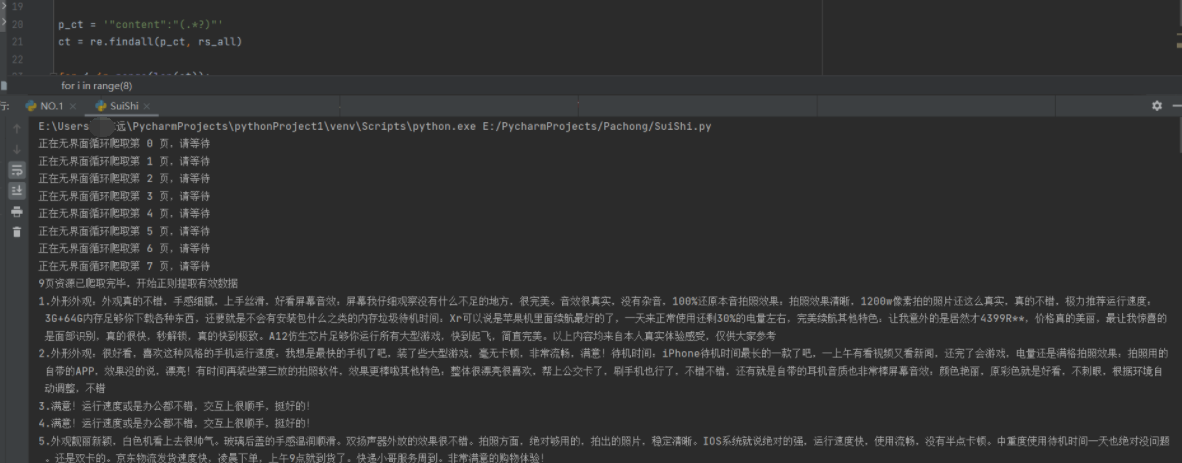
print("9页资源已爬取完毕,开始正则提取有效数据")
import time
time.sleep(4)
p_ct = '"content":"(.*?)"' #非贪婪匹配的正则表达提取评论
ct = re.findall(p_ct, rs_all)
for i in range(len(ct)): #提取后以分点形式输出
ct[i] = ct[i].replace(r'\n', '')
print(str(i+1)+ '.'+ ct[i])
运行正常