第一次写爬虫,记录一下
首先import引入

然后找到我们要爬取的网页,复制链接注意有些网站反爬虫,我们要加入请求头

观察网页结构,找出相同点,此网页具有相同的class名v-pw,我们要取他里面img的src和文字

如图:我们就可以取到src和里面的文字了
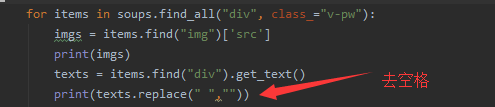
取到以后插入数据库:

完整代码:
import pymysql
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
page = requests.get('https://www.xinshipu.com/s/d0a1b3b4b2cbb2cbc3fbb4f3c8ab/', headers = headers)
db = pymysql.connect('localhost', 'root', 'root', 'blog', charset='utf8')
cursor = db.cursor()
page.encoding = 'utf8'
soup = BeautifulSoup(page.text, "html.parser")
num = -1
pageNum = 1
nameArr = []
imgArr = []
for index in range(10):#有10页数据,循环获取,
pageNum = pageNum+1
print('https://www.xinshipu.com/s/d0a1b3b4b2cbb2cbc3fbb4f3c8ab/?page='+str(pageNum))
pages = requests.get('https://www.xinshipu.com/s/d0a1b3b4b2cbb2cbc3fbb4f3c8ab/?page='+str(pageNum), headers=headers)
db = pymysql.connect('localhost', 'root', 'root', 'blog', charset='utf8')
cursor = db.cursor()
pages.encoding = 'utf8'#网页编码,有些网页是gb2312 等
soups = BeautifulSoup(pages.text, "html.parser")
# vegeAlls = soups.findAll("div", attrs={"class", "new-menu-list"})
for items in soups.find_all("div", class_="v-pw"):
imgs = items.find("img")['src']
print(imgs)
texts = items.find("div").get_text()
print(texts.replace(" ",""))
nameArr.append(texts.replace(" ",""))
imgArr.append(imgs)
num = num + 1
print(num)
cursor.execute(
"insert into food(cid,foodName,foodImg) values(%s, %s,%s)",
(num+1,nameArr[num],imgArr[num]))#插入数据库,food是表名 values(%s, %s,%s)占位符
db.commit()//提交到数据库
cursor.close()//关闭游标
db.close()//关闭数据库
