问题背景
半监督学习的主要任务是如何通过模型在未标签的数据上的预测情况,来得到可靠的伪标签,从而将大量无标签数据引入训练。
在以往的半监督学习的工作中,「置信度阈值」(confidence thresholding)是一种比较主流的利用伪标签的方式。比如在FixMatch中,置信度高于阈值(0.9)的数据的伪标签会直接引入到训练中。通过设定较高的阈值, 伪标签的质量(即正确性)可以得到保证。但是,一系列动态阈值的工作如FlexMatch(NeurIPS'21)和FreeMatch(ICLR'23)指出,过高的阈值丢弃了很多不确定的伪标签,导致类别之间学习「不平衡」,并且伪标签「利用率低」。动态阈值通过前期降低(不同类别/不同数据)的阈值,来引入更多的伪标签在前期参与训练,但是前期的低阈值会不可避免的引入质量低的伪标签。
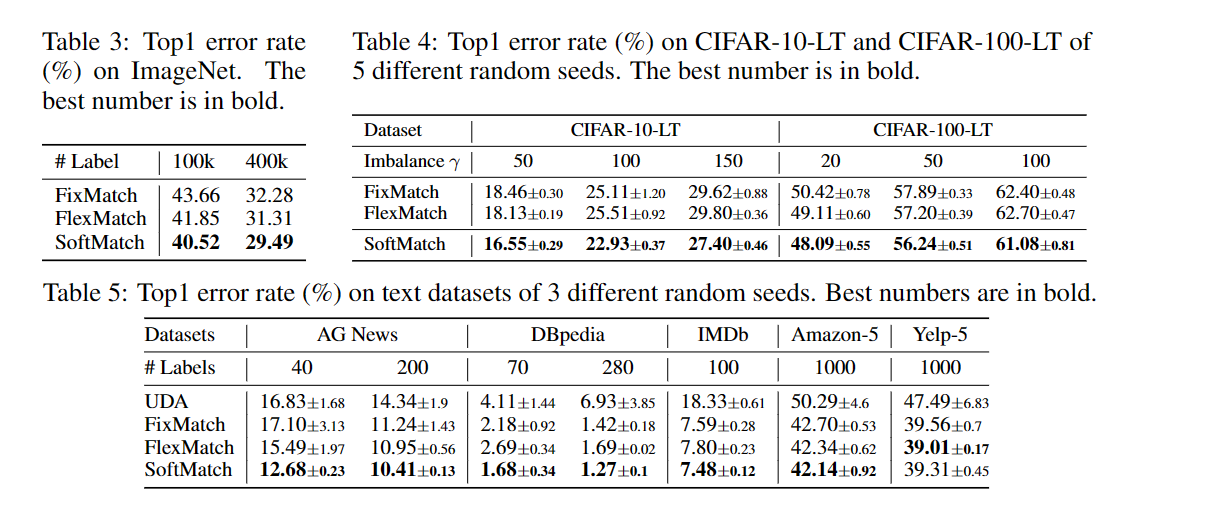
本文介绍的SoftMatch则着重解决伪标签「数量-质量」间的trade-off。该工作已被ICLR 2023录用(分数8666),在图像、文本、长尾分类上均取得了最好的效果。文章共同第一作者为卡耐基梅隆大学的陈皓和陶然。二人也是半监督算法库USB(NeurIPS'22)的核心成员。合作者来自马克斯-普朗克研究所、微软亚洲研究院,以及MBZUAI。
贡献
•通过正式定义伪标签的数量和质量,以及它们之间的权衡,证明了统一加权函数的重要性。发现,以前的方法中固有的权衡主要源于对伪标签分布缺乏仔细的设计,这是由加权函数直接施加的。
•提出SoftMatch来有效地利用不自信但正确的伪标签,拟合截断高斯函数的置信度分布,克服了权衡。进一步提出统一对齐来解决假标签的不平衡问题,同时保持其高数量和高质量。
•演示了SoftMatch在各种图像和文本评估设置上优于以前的方法。还通过经验验证了在SSL中追求更好的无标签数据利用率的同时保持伪标签的高精度的重要性。
重温SSL的数量-质量权衡
在本节中,作者从统一的样本权重的角度,通过演示样本权重函数与伪标签数量/质量之间的关系,来制定伪标签的数量和质量。SoftMatch的灵感自然来自于重新审视现有方法在数量-质量权衡方面的固有限制。
在本文中,作者更进一步,从样本加权的角度提出了一个统一的置信度阈值方案(以及其他方案)。具体而言,将无监督损失Lu表述为模型对强增强数据Ω(xu)的预测与弱增强数据Ω(xu)的伪标签之间的加权交叉熵:
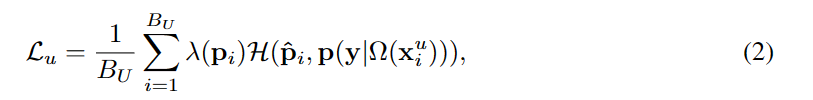
式中p为p(y|ω(xu))的缩写,p为单热伪标签argmax(p);λ(p)为范围为[0,λmax]的样本加权函数;BU为未标记数据的批大小。
从样本加权的角度看数量-质量权衡
通过展示其在先前方法中的不同实例化及其与模型预测的本质联系,证明了统一加权函数λ(p)的重要性。我们首先制定伪标签的数量和质量。
定义2.1(伪标签数量)。训练中登记的伪标签的数量f (p)定义为样本权重λ(p)对未标记数据的期望:
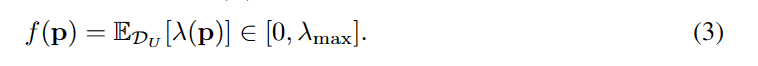
定义2.2(伪标签的质量)。质量g(p)是伪标签加权0/1误差的期望,假设标签yu仅为理论分析目的:
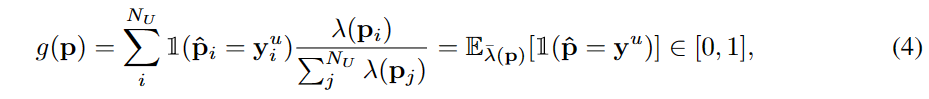
其中,λ(p) = λ(p)/∑λ(p)是p接近于yu的概率质量函数(PMF)。基于质量和数量的定义,提出了SSL的数量-质量权衡问题。
定义2.3(数量-质量权衡)。由于PMF λ(p)在模型预测的边际分布上隐含的假设,对它缺乏复杂的设计通常会导致数量和质量的权衡——当其中一个增加时,另一个必须减少。理想情况下,定义良好的λ(p)应该反映真实的分布,并导致高数量和高质量。
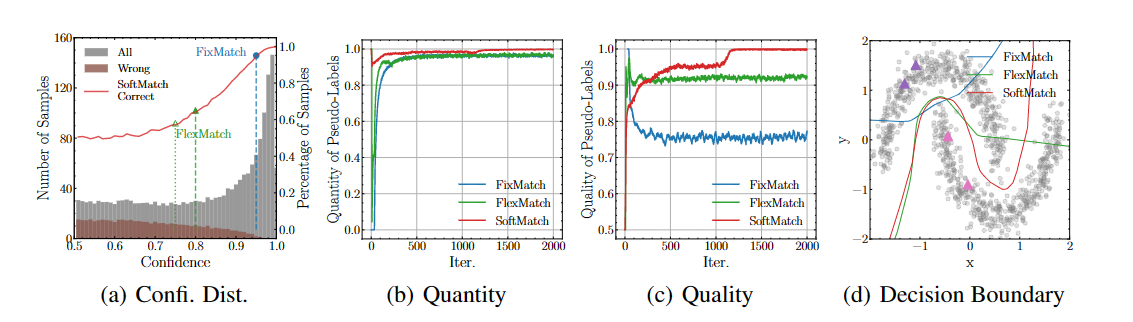
其中(a)可以理解为在训练某个时刻所有无标签数据的置信度分布(灰色直方图)和其中伪标签是错误的数据的置信度分布(褐色直方图)。红色的线为softmatch提出的weighting function对这些数据的利用率,其中我们用蓝色的点及以上的部分表示FixMatch的利用率, 绿色的点及以上的部分来表示FlexMatch的利用率。
可以看出,正如前面的分析,过高的阈值(FixMatch)会导致伪标签整理利用率低(低数量,71%的无标签数据没有利用到),即使所利用的伪标签大部分是正确的(高质量),仍然无法学习到好的分类器。对于FlexMatch来说,即使训练初期使用了较低的阈值以提高利用率(相比于FixMatch为高数量),但是伪标签中引入了过多的错误标签(约16%所使用的标签是错误的).(我们认为这也是FlexMatch在svhn上不work的主要原因). 相比于之前的方法,SoftMatch在保证高利用率的同时,通过对可能错误的标签分配较低的权重,以同时实现高质量。
方法SOFTMATCH
样本加权的高斯函数
与以前的方法本质上不同,作者通常假设边际分布的潜在PMF λ(p)在第t次训练迭代中遵循均值μt和方差σt的动态截断高斯分布。基于高斯函数的最大熵性质,我们选择了高斯函数,并通过实证验证了其较好的泛化性。请注意,这相当于将置信度max(p)与高斯分布均值μt的偏差作为模型预测正确性的代理度量,其中置信度较高的样本比置信度较低的样本更不容易出错,与图1(a)所示的观察结果一致。为此,我们可以推导λ(p)为:
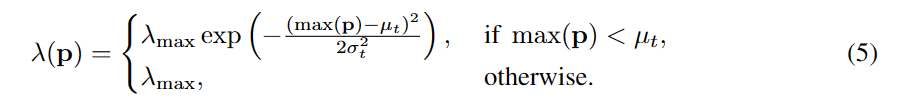
这也是一个在[0,λmax]范围内的截断高斯函数,其置信度为max(p)。
然而,真正的高斯参数μt和σt仍然未知。尽管我们可以像FixMatch (Sohn等人,2020)那样将参数设置为固定值,或者像Ramp-up (Tarvainen & Valpola, 2017)那样在一些预定义的范围内线性插值它们,但这可能会再次过度简化前面讨论的PMF假设。回想一下,PMF = λ(p)是在max(p)上定义的,我们可以将截断的高斯函数直接拟合到置信度分布上,以便更好地泛化。具体地说,我们可以从模型的历史预测中估计μ和σ2。在第t次迭代中,我们计算经验均值和方差如下:
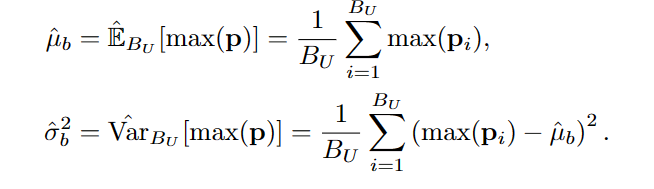
然后,我们聚合批次统计数据以获得更稳定的估计,使用动量为m的指数移动平均(EMA):
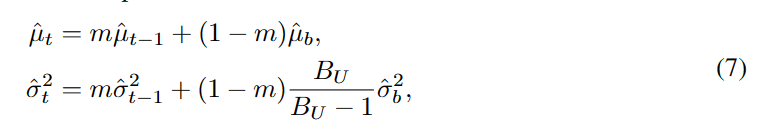
训练过程中根据置信度分布自适应估计高斯参数,不仅提高了泛化能力,而且较好地解决了数量-质量的权衡问题。我们可以通过计算伪标签的数量和质量来验证这一点,如表1所示。得到的量f (p)以[λmax2 (1 + exp(−(1C−μt)22 σt2)), λmax]为界,说明SoftMatch在训练过程中保证了至少λmax/2的量。随着模型学习能力的提高和信心的增强,即:μt增加,σt减少,量的下尾变得更紧。在数量保持较高的同时,伪标签的质量也有所提高。在训练过程中,随着高斯函数尾部呈指数级增长,模型高度不自信的错误伪标签被赋予较低的权重,而置信度在μt左右的伪标签被更有效地利用。截断高斯加权函数通常表现为一种软且自适应的置信度阈值,因此我们将所提出的方法称为SoftMatch。
均匀对齐公平的数量
由于不同的类表现出不同的学习困难,生成的伪标签可能具有潜在的不平衡分布,这可能会限制PMF假设的泛化(Oliver et al., 2018;Zhang et al., 2021)。为了克服这个问题,我们提出了统一对齐(UA),鼓励不同类的伪标签更加统一。具体来说,我们将伪标签中的分布定义为模型预测在无标签数据上的期望:EDU [p(y|xu)]。在训练过程中,利用未标记数据的批预测EMA估计为EBU [p(y|xu)]。我们使用均匀分布u(C)∈RC和EBU [p(y|xu)]之间的比值来归一化未标记数据上的每个预测p,并使用归一化概率来计算每个样本的损失权重。我们将UA操作表述为:
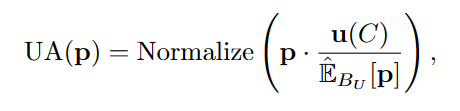
其中归一化(·)=(·)/∑(·),确保归一化概率和为1.0。插入UA后,SoftMatch中最终的样本权重函数变成:
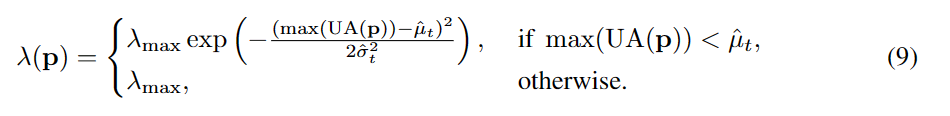
UA与之前提出的分布对齐(DA) (Berthelot et al., 2019a)之间的本质区别在于无监督损失的计算。归一化操作使预测概率偏向于较少预测的类别。在DA中,这可能不是一个问题,因为在交叉熵损失中,标准化预测被用作软目标。但是,使用伪标签可能在规范化后产生更多错误的伪标签,从而损害了质量。UA通过利用原始预测来计算伪标签和标准化预测来计算样本权重,从而避免了这个问题,在SoftMatch中保持了伪标签的数量和质量。