
成功的途径有两条,一是开始,二是坚持。
论文: Resolution-robust Large Mask Inpainting with Fourier Convolutions
Github:https://github.com/saic-mdal/lama

基于目前主流的图像修复方法效果之所以差主要问题在于缺乏足够的感受野。网络结构和损失函数都是需要比较大的感受野的。基于此,论文提出了使用快速傅立叶卷积 fast Fourier convolutions (FFCs)来增大感受野,最终形成large mask inpainting (LaMa)。
主要贡献:
- 基于FFC提出了新的图像修复网络,FFC使得网络即使在浅层也可以获得整个图片的感受野。FFC不仅提升了模型的修复质量,同时降低了模型的参数量。同时FFC中的偏置使得网络具有更好的泛化性,可以使用低分辩率图片训练就产生高分辨率的修复结果。
- 基于网络具体更大感受野的提前,提出使用感知loss。
- 提出了训练过程中的遮挡区域mask生成策略,产生的又宽又大的mask,彻底的激发网络的潜能。
网络结构:

原始彩色图片(3通道),mask图片(1通道),先将mask取反和彩色图片相乘,得到带有mask的彩色图片。然后将其和mask图片基于通道进行叠加,得到一个4通道的图片。
网络会首先进行下采样操作,然后经过快速傅立叶卷积处理,最后再上采样输出修复后的图像。
其中,在FFC的处理过程中,会将输入tensor基于通道分为2部分分别走2个不同的分支。一个分支负责提取局部信息,称为local分支。另一个分支负责提取全局信息,称为global分支。在global分支中会使用FFC提取全局特征。最后将局部信息和全局信息进行交叉融合,再基于通道进行拼接,得到最终的输出结果。
快速傅立叶卷积:


傅立叶变换后的结果是一个复数。实数和虚数各占一半。FFC只对傅立叶变换的实数部分进行操作,也就是只有一半的光谱会被处理到。也就是经过Real FFT2d处理后,宽度减半。然后将处理后的实数和虚数基于通道进行拼接,使得通道加倍。将拼接后的tensor进行传统conv+BN+relu操作处理,tensor的形状不变。得到的tensor再从实数变换为复数,然后进行FFT2d的逆变换,得到最终的结果。整个处理过程,tensor的大小不改变。
损失函数:
生成模型的感知损失
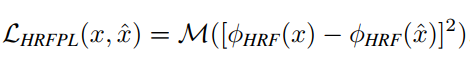
基于局部patch的生成器,判别器的损失

判别器的梯度惩罚
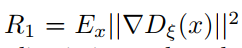
总的损失,包括GAN的损失,生成器感知损失,判别器感知损失,判别器梯度惩罚。

实验结果:

研究人员在CelebA-HQ数据集上的图像修复进行了实验,采用可学习感知图像斑块相似性(LPIP)和FID作为定量评估指标。与LaMa傅立叶模型相比,几乎所有的模型的性能都更弱(红色上箭头)。表中还包括了不同的测试掩码生成的不同策略的度量,即窄掩码(narrow)、宽掩码(wide)和分段掩码(segmentation),LaMa傅里叶的性能仍然更强,表明了实验方法更有效地利用了可训练参数。
