图像修复技术的研究是计算机视觉以及计算机图形学的一个具有重大意义的研究课题。对于带有损失区域的图像,由于我们并不知道原本图像的具体形式,我们只能类似于“凭空捏造”一些像素去填补这种缺失。正因如此,图像修复实际是根据人类自己的视觉规则对图像进行分析,然后去修补。简言之,修复技术的改进主要依赖于对图像模型的研究和人类视觉认知规则。
传统的图像修复技术通常划分为两大类:一类是基于变分PDF模型的图像修复技术,主要是通过求解偏微分方程来进行修复;另一类则是基于纹理的图像修补技术,通过图像的纹理结构特征匹配进行修复。
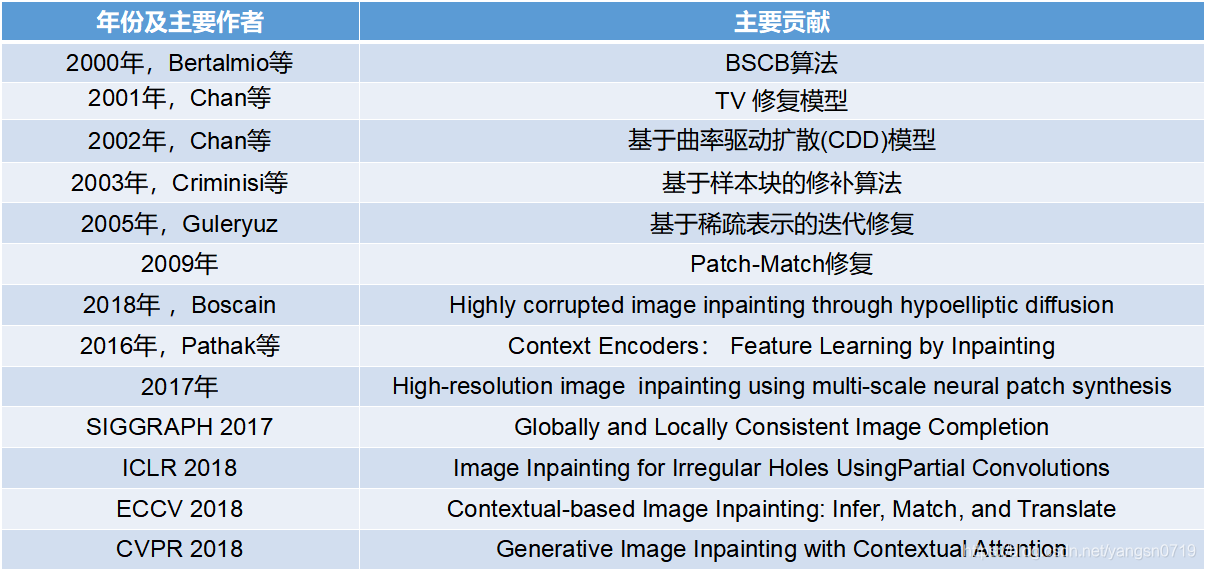
2000年,Bertalmio等的首先提出一种基于偏微分方程的图像修复方法,即 BSCB算法,主要思想是将待修补区域周围的信息沿着等照度线方向迭代传输到破损的待修复区域内,然后再进行若干次各向异性扩散多次从而得到修复后的图像。本质上它是一种基于偏微分方程(PDE)的修复方法。此类方法利用了物理学中热扩散方程。

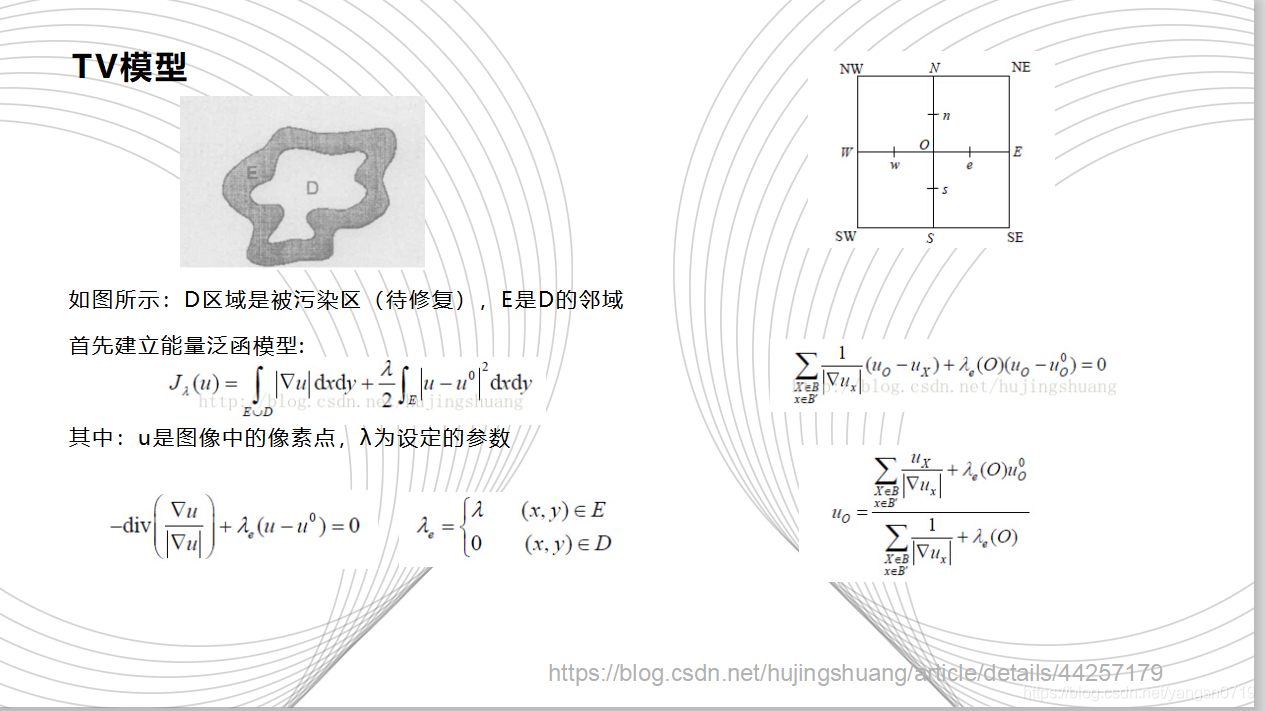
2001年,Chan等在Rudin等提出的总变分(TV)去噪模型的启发下,提出了一种用于图像修复的TV修复模型,这种方法搜先要确定图像的能量函数,通过对能量函数的最小化使得图像达到平滑状态。它最早就是用来对受到噪声污染的图像进行降噪。其优点是边去噪边修复,同时可以锐化图像的边缘。修复过的图像视觉连通性差,并且需要大量的迭代次数,修复时间较长。
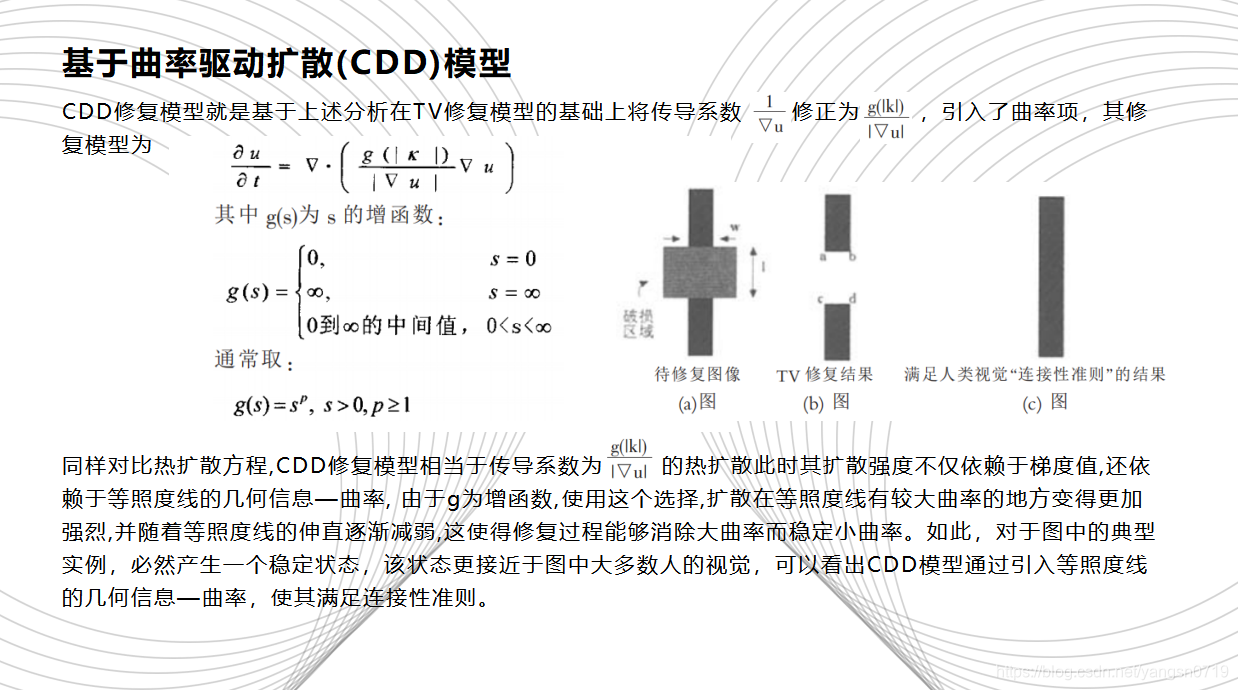
2002年,Chan等在 TV 模型的基础上提出了基于曲率驱动扩散(CDD)模型,通过梯度和曲率信息共同调节扩散的速度,优点是视觉连通性较好,缺点是引入了曲率信息,导致计算量和计算时间增加,并且修复后的图像边界比较模糊。
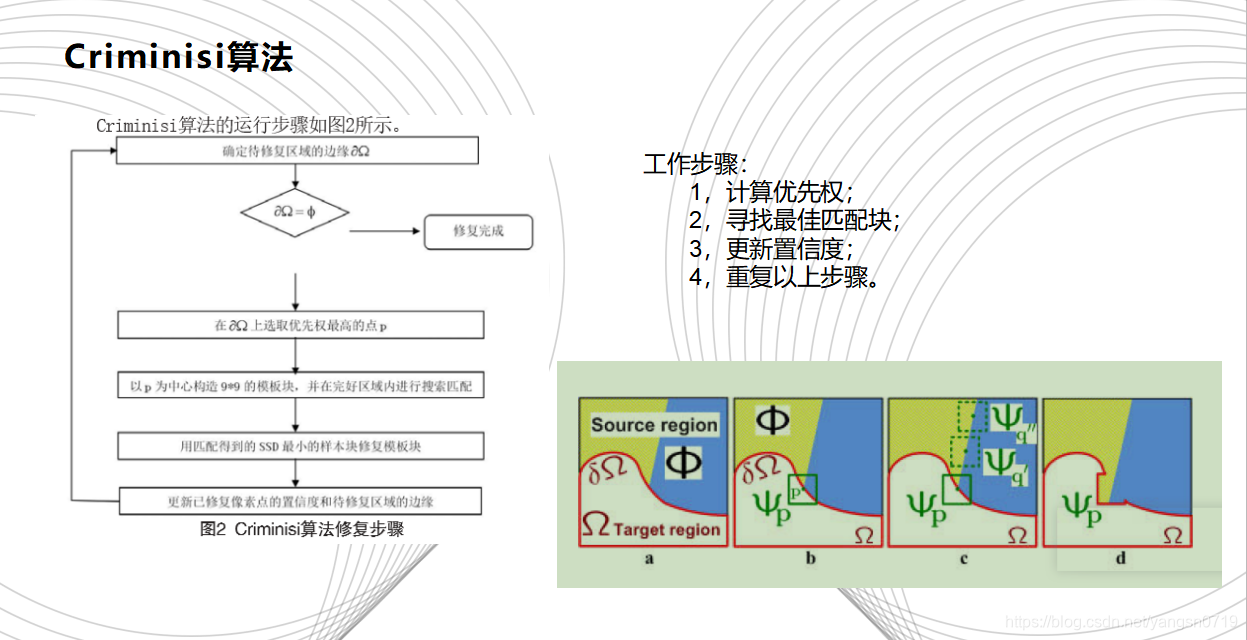
2003年,Criminisi等人提出了一种基于样本块的修补算法,Criminisi算法通过在待修复区域边缘上选取优先权最高的像素点p,以p为中心构造一个n×n大小的像素块,然后在完好区域寻找与该模板块最相似的样本块,用找到的样本块更新模板块中的待修复信息,最后更新已修复块中像素点的置信度,并开始下一次迭代修复,直至修复完成。Criminisi算法采用纹理合成的方法去除图像中的大物体,得到了很好的效果。该算法中,待修复区域的标记,优先权计算,最佳匹配模块的搜索及填充,置信度项的更新是影响该算法效果的几个主要因素。
2005年,Guleryuz提出了一个基于分析字典(小波基、DCT 基、复数小波 基、小波包基)的迭代修复算法,该算法仅利用了局部光滑性(Local Smoothness) 稀疏先验,所以,修复纹理和边缘的修复能力较弱。这种基于稀疏表示的修复,其主要是通过图像信号的稀疏性对图像进行表示,然后通过信号重构对图像进行恢复。通常将其分为两个步骤:第一步是进行稀疏编码,主要提高编码速率;第二部是构建完备字典。经过上述两步,可以保证稀疏表示系数尽可能的非负,进而提高图像修复的效果。目前字典学习算法主要包括MOD、K-SVD、Online等。

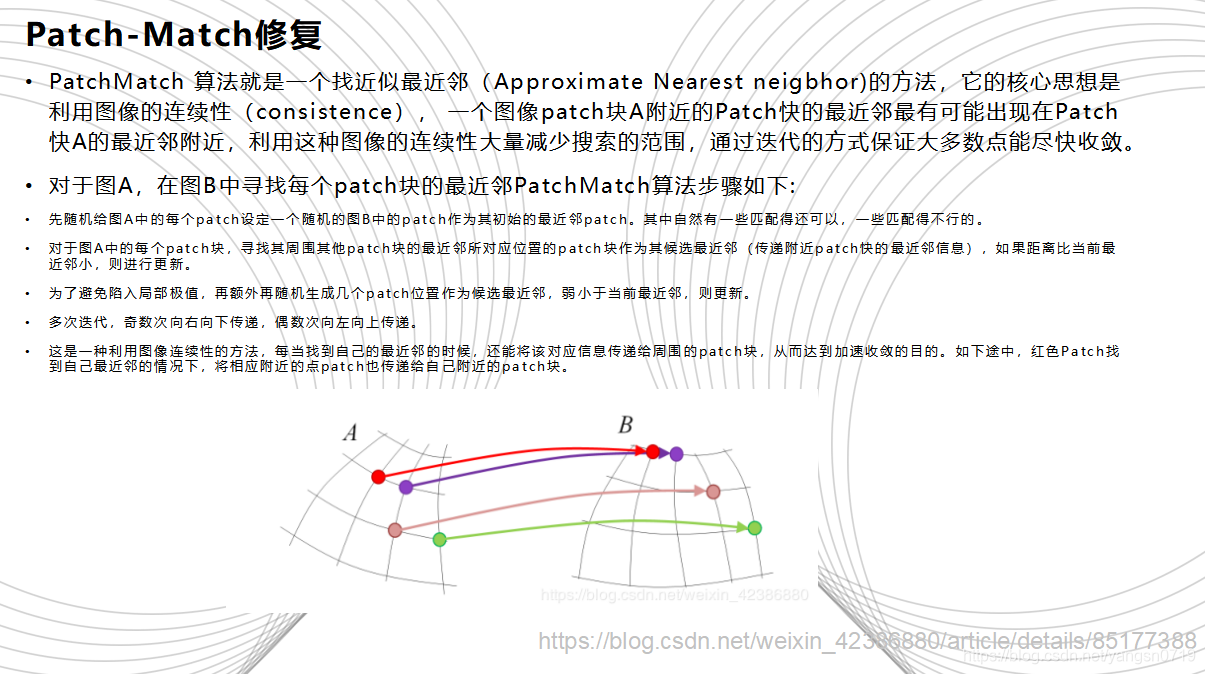
2009年《A Randomized Correspondence Algorithm for Structural Image Editing》一文提出了PatchMatch 算法。其核心思想是利用图像的连续性(consistence),一个图像patch块A附近的patch块的最近邻最有可能出现在A的最近邻附近,利用这种图像的连续性大量减少搜索范围,通过迭代的方式保证大多数点能尽快收敛。之后,《基于空间相关性的图像补全》一文,王向阳等人利用这种空间相关性与经典的Criminisi算法结合, 将原来寻找最佳匹配块的全局搜索改为局域搜索,减少了搜索时间。其基本原理是图像的空间分布不是毫无关系的,而是呈现局域相关的特点,即具有相同性质(亮度、颜色等)的像素相邻分布,就图像修补来说,根据这一特性,将经典的Criminisi算法中寻找最佳匹配块的全局搜索改为局域搜索,便能减少搜索时间。
2012年的《基于样本和线性结构信息的大范围图像修复算法》,吴晓军等人提出平均值补偿办法减少匹配误差,通过增加惩罚项来避免一个像素块在图像修复过程中多 次被使用。
2013年,郭勇等人将块匹配法与边缘驱动填充顺序、全局搜索与局部搜索相结合,充分发挥修补过程中填充优先权的作用,有效地修补了图像受损区域的纹理和结构信息。
2018年的《Highly corrupted image inpainting through hypoelliptic diffusion》一文显示了对于大面积破损图像修复的良好效果。该文提出了一个新的仿生图像修复算法,平均和次椭圆化(AHE)算法,它基于次黎曼次椭圆扩散算法和特殊局部平均技术的适当组合。算法分为四个步骤,分为以下4个步骤:预处理阶段(简单平均),主扩散(强平滑);高级平均值;弱平滑。该算法对高度损坏的图像(即超过80%的图像丢失)获得了高质量的修复效果。但破损图像的破损点被要求分布良好,因此该算法实际应用比较有限制。
以上这些都是之前的一些经典的使用传统数学和物理方法进行修复的例子。当下深度学习的方法越来越受到学者专家的推崇,深度学习是机器学习的一个分支,而在很多情况下,机器学习几乎成了人工智能的替代概念。简单地说,就是通过机器学习算法,使计算机有能力从大量已有数据中学习出潜在的规律和特征,以用来对新的样本进行智能识别或者预期未来某件事物的可能性。
近年来,深度学习的方法越来越多的应用在计算机视觉领域,其效果也远超传统的基于数学和物理的方法。在这样的形势之下,越来越多的图形学研究者也开始将目光投向深度学习。在图形学和视觉交叉的领域,一系列问题的研究正在围绕深度学习火热展开,特别是在图像生成(image generation),图像补全(image inpainting)等方面,已经颇有成效。
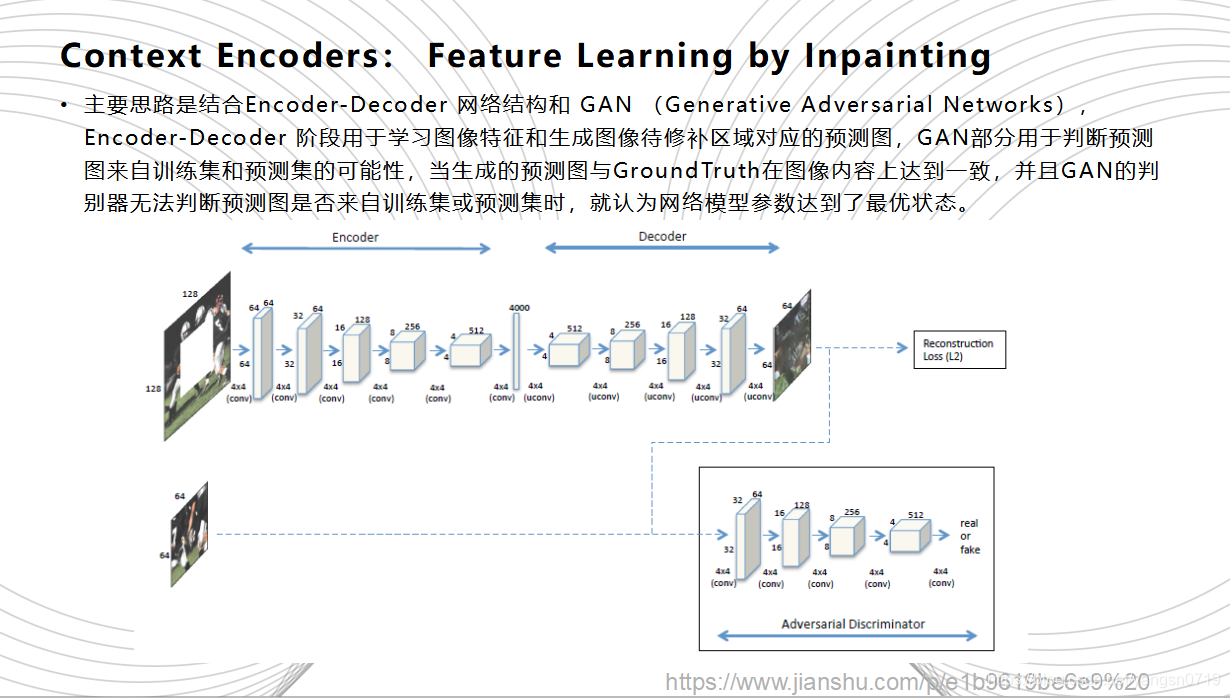
2016年,Pathak等人的Context-Encoders可以说是鼻祖级别的神经网络修复方法,它构建出一种图像修复的深层生成网络模型。CE的主要思路是结合Encoder-Decoder 网络结构和GAN(Generative Adversarial Networks),Encoder-Decoder 阶段用于学习图像特征和生成图像待修补区域对应的预测图,GAN部分用于判断预测图来自训练集和预测集的可能性,当生成的预测图与Ground Truth在图像内容上达到一致,并且GAN的判别器无法判断预测图是否来自训练集或预测集时,就认为网络模型参数达到了最优状态。网络训练的过程中损失函数都由两部分组成:Encoder-decoder 部分的图像内容约束(Reconstruction Loss)GAN部分的对抗损失(Adversarial Loss)。Context Encoders 采用的是最简单的整体内容约束,也就是预测图与原图的l2 距离。
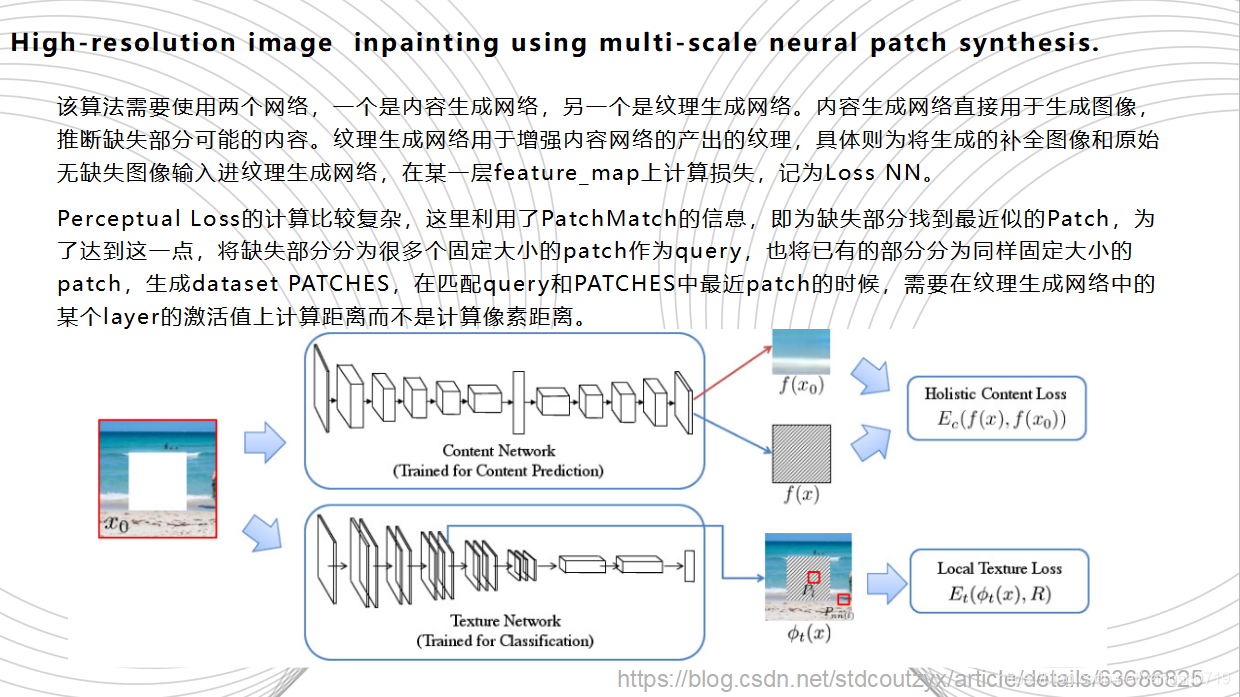
在CE问世之后,出现了许多在以其为基础而衍生出的改进版CE,图像修复的效果也越来越好。如,2017年的High Resolution Inpainting将生成网络划分为内容生成网络和纹理生成网络两部分,使用上下文编码器的输出初始化孔,然后使用样式传递技术改进纹理,将高频纹理从边界传播到孔洞。内容生成网络直接用于生成图像,推断缺失部分可能的内容。纹理生成网络用于增强内容网络的产出的纹理,具体则为将生成的补全图像和原始无缺失图像输入进纹理生成网络,在某一层feature_map上计算损失,记为Loss NN。内容生成网络需要使用自己的数据进行训练,而纹理生成网络则使用已经训练好的VGG Net。此算法最主要的技术是结合了Context-Encoders和CNNMRF。Perceptual Loss的计算比较复杂,这里利用了PatchMatch的信息,即为缺失部分找到最近似的Patch,为了达到这一点,将缺失部分分为很多个固定大小的patch作为query,也将已有的部分分为同样固定大小的patch,生成dataset PATCHES,在匹配query和PATCHES中最近patch的时候,需要在纹理生成网络中的某个layer的激活值上计算距离而不是计算像素距离。
另外还有SIGGRAPH 2017 年的一篇文章Globally and Locally Consistent Image Completion 是在CE中加入Global+Local两个判别器的改进。GL这篇文章完全以卷积网络作为基础,遵循GAN的思路,设计两部分网络,一部分用于生成图像,一部分用于鉴别生成图像是否与原图片一致。生成图片部分,GL采用12层卷积网络对原始图片(去除需要进行填充的部分)进行encoding,得到一张原图16分之一大小的网格。然后再对该网格采用4层卷积网络进行decoding,从而得到复原图像。鉴别器也被分为两个部分,一个全局鉴别器(Global Discriminator)以及一个局部鉴别器(Local Discriminator)。全局鉴别器将完整图像作为输入,识别场景的全局一致性,而局部鉴别器仅在以填充区域为中心的原图像4分之一大小区域上观测,识别局部一致性。通过采用两个不同的鉴别器,使得最终网络不但可以使全局观测一致,并且能够优化其细节,最终产生更好的图片填充效果。

 ICLR 2018的《Image Inpainting for Irregular Holes UsingPartial Convolutions》号称秒杀PS的AI图像修复神器,来自于Nvidia 研究团队,它引入了局部卷积,能够修复任意非中心、不规则区域。该模型使用堆叠的部分卷积运算和掩膜更新步骤来执行图像修复,网络设计类似于UNet架构,用部分卷积层替换所有卷积层,并在解码阶段使用最近邻居上采样。当在图像边界附近时,不使用任何现有的填充方案来卷积。相反,部分卷积层直接通过适当的掩膜处理。这将进一步确保图像边界上的修复内容不会受到图像外部无效值的影响。
ICLR 2018的《Image Inpainting for Irregular Holes UsingPartial Convolutions》号称秒杀PS的AI图像修复神器,来自于Nvidia 研究团队,它引入了局部卷积,能够修复任意非中心、不规则区域。该模型使用堆叠的部分卷积运算和掩膜更新步骤来执行图像修复,网络设计类似于UNet架构,用部分卷积层替换所有卷积层,并在解码阶段使用最近邻居上采样。当在图像边界附近时,不使用任何现有的填充方案来卷积。相反,部分卷积层直接通过适当的掩膜处理。这将进一步确保图像边界上的修复内容不会受到图像外部无效值的影响。

ECCV 2018年的Yu hang Song等人的一篇《Contextual-based Image Inpainting: Infer,Match, and Translate》将修复过程分解为两个阶段:推理和翻译。在推理阶段,我们训练了一个 Image2Feature 网络,该网络用粗预测初始化孔并提取孔的特征。预测是模糊的但包含着孔洞中的高层次结构信息。在翻译阶段,我们训练了一个能将特征转换回完整的图像的Feature2Image网络。它细化了孔中的内容,输出了具有清晰逼真纹理的完整图像。为了减轻 Feature2Image 网络训练的困难,我们设计了一个“patch-swap”层,将高频纹理细节从边界传播到孔。patch-swap层以feature map作为输入,用边界上最相似的块替换洞里的每个神经贴片。然后,我们使用新的feature map作为 Feature2Image 网络的输入。通过重新利用边界上的神经斑块,feature map包含了足够的细节,使得高分辨率的图像重建成为可能。

CVPR 2018的《Generative Image Inpainting with Contextual Attention》同样采用了高阶语义识别与低阶像素识别结合的卷积编码器-译码器结构,与对抗网络结合训练,以保证生成像素与已有像素间的一致性。这篇文章提出了一个统一的前馈生成网络和一个新的上下文注意层的图像inpaint。该网络包括两个阶段:第一阶段是对简单的扩张型卷积网络进行重构损失训练,提取缺失内容。第二阶段整合语境注意。上下文关注的核心思想是使用已知的卷积滤波器的特性来处理生成的补丁,它还具有空间传播层,以促进注意的空间一致性。在语境注意通路的同时,还有另一条卷积通路。将这两条通路聚合起来,送入一个译码器以获得最终的输出。整个网络被训练得从头到尾都是重建损失和两个Wasserstein GAN losses,一个critic关注总体图像,另一个关注局部缺失区域。
从这些典型的作品来看,基于深度学习的图像修复算法最基础的模型就是CE深层生成模型,之后的各种层出不穷的“改进”,都是在深层生成网络模型上加入各种优化,如生成对抗网络,感知损失,全局和局部注意力机制,或是改进网络结构等等,根本目的都是想加快训练速度,优化训练效果。深度学习的方法相比传统基于数学和物理的方法,效果有了很大改善。研究学者们渐渐发现,当传统的基于物理的模型发展遇到瓶颈的时候,机器学习的方法也许能够帮助我们解释这些复杂的数理模型。
但深度学习的方法也有很多缺点,训练一个模型往往需要大量的采集数据,各种输入输出数据有时并不能满足网络所需要的条件,因此,数据集的预处理或后处理代价就十分巨大。同时,训练过程也是一个较长时间的过程。传统的数理模型有些情况下就相比来说过程就不如深度学习那样繁琐。
总的来说,各种方法都有其利弊,都各有优势。实际处理问题时,我们应该视情况来决定用哪些方法来进行修复工作。
参考:
https://blog.csdn.net/yujiang5/article/details/46765691?utm_source=blogxgwz4
https://blog.csdn.net/hujingshuang/article/details/44257179
http://www.doc88.com/p-8466339157286.html
https://blog.csdn.net/weixin_42386880/article/details/85177388
https://www.jianshu.com/p/e1b9619be6e9
https://blog.csdn.net/stdcoutzyx/article/details/63686825https://www.sohu.com/a/163252003_775742
https://blog.csdn.net/Gavinmiaoc/article/details/80801587
 参考文献列表
参考文献列表