博主简介
博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c++,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,如果有错误之处,大家可以指正。
专栏简介: 本专栏主要研究计算机视觉,涉及算法,案例实践,网络模型等知识。包括一些常用的数据处理算法,也会介绍很多的Python第三方库。如果需要,点击这里订阅专栏 。
给大家分享一个我很喜欢的一句话:“每天多努力一点,不为别的,只为日后,能够多一些选择,选择舒心的日子,选择自己喜欢的人!”

图像的修复
图像修复的意思就是说将缺失的部分补全。那么图像为什么会破损?并不是图像在传输过程中出了问题,而是有两个主要原因:污染和噪声,就比如说,戴眼镜的同学都知道,眼镜戴久了,会出现很多污渍。这时候就会特别模糊。差不多就是这个意思。那我们如何去修复喃,除了现在的软件修复,我们用代码如何取实现喃?
如果说要修复缺失的图像其实是非常不容易的,计算机不知道他原来的样子,颜色,形状,而我们可能知道,但是没办法告诉计算机,我们就只能让计算机根据缺失部分周围的颜色进行合成。然后填充。但是如果需要修复的面积太大,就很难修复了。所以,其实图像修复都是基于原图像进行解析,修复。不能凭空绘制出原图像。
在OpenCV中,我们使用cv2.inpaint()函数进行图像修复。此函数的参数为img(输入图像)、mask(输入掩模,用来标记需要修复的区域,其余区域标为0)、dst(输出图片)、radius(每个像素复杂的半径)、以及修复方式(flag)。常用的修复方式为Navier Stokes和A.Telea's。需要注意的是,这里暂且只支持8位的图像(0~255).当损坏的部分面积很小,能进行修复。如果破损太大,只能进行部分修复。
#对破损图片进行修复
import cv2
import numpy as np
#读取破损图片
damaged=cv2.imread('F:\Image\\test13.jpg')
#读取或设置mask,注意mask必须是一通道
coordinates = []
coordinate1 = [[[40, 13], [16,13], [16,33], [20,32]]]
coordinate2 = [[[30, 30], [60,30], [60,60], [30,60]]]
coordinate1 = np.array(coordinate1)
coordinate2 = np.array(coordinate2)
coordinates.append(coordinate1)
coordinates.append(coordinate2)
mask = np.zeros(damaged.shape[:2], dtype=np.int8)
mask = cv2.fillPoly(mask, coordinates, 255)
repaired=cv2.inpaint(damaged,int(mask),5,cv2.INPAINT_NS)
cv2.imshow('1',damaged)
cv2.imshow('2',repaired)
cv2.waitKey(0)
图像的去噪
当然,图像破损的第二个原因就是噪声,在许多场景中,噪声的主要来源是光线太亮或者太暗。这是由于在低光条件下,成像增益增加,导致噪声被放大。这种噪声的特点是孤立性与随机性,所以我们常常称其为椒盐噪声。顾名思义,就像在菜上面撒的椒盐一样,分布非常随机。
最新的的去噪方法为非局部均值去噪,也称为NL-means,是由Buades和Antoni在2005年首次提出来的,和高斯滤波(高斯去噪)不同,高斯滤波是采用了对周围各个像素去均值的手法,而非局部均值去噪则是在整张图片中寻找相似点,然后再对这些取平均值。
其中,c是通道索引,例如RGB,c=1、2、3对应的就是RGB;表示p在通道c上的色彩强度;B(0,s)表示以像素为中心、半径为s的窗口。用这个公式,我们就能刻画两个像素之间的距离。显然,距离越小,两个像素越接近。
当然,一般来说距离越远的点相关性越小,所以会根据距离给定指数衰减函数,最后通过所有像素的加权平均对当前的像素进行更新。
在OPenCV中,我们尝试用的是快速非局部均值去噪,也称为FNLMD,顾名思义就是在原来的算法基础上,加快了速度,更注重效率。函数为cv2.fastNlMeansDenoising(),如果是彩色图片,则函数为cv2.fastNlMeansDenoisingColored(),此函数的可选参数为输入图像(img)、输出图像(outputArray)、权重衰减因子(h)、色彩权重衰减因子(hColor)、比较窗口大小(teplateWindowsize)、搜索窗口大小(searchWindowSize)。需要注意的是对于彩色图像,要先转换到LAB颜色空间,应用算法去噪后,再转为彩色图片。
#去噪
#对图像进行快速非局部均值去噪
import numpy as np
import cv2
#读取图片
img=cv2.imread('F:\Image\\test12.jpg')
#去噪声,灰度图
denoised=cv2.fastNlMeansDenoising(img,None,10,7,21)
#去噪声,彩色图
lab=cv2.cvtColor(img,cv2.COLOR_BGR2LAB)
denoised=cv2.fastNlMeansDenoisingColored(lab,None,10,10,7,21)
denoised=cv2.cvtColor(denoised,cv2.COLOR_LAB2BGR)
#显示图片
cv2.imshow('图片',denoised)
cv2.waitKey(0) 
 对比两张图片。似乎第二张更加的模糊,这是由于色彩权重因子过大导致的,调整色彩权重因
对比两张图片。似乎第二张更加的模糊,这是由于色彩权重因子过大导致的,调整色彩权重因
子大小即可。这张是不是就好很多了。当然,和原图可能没有很大的出入,这是因为这张图片 本身就是模糊的,我们可以换一张图片进行测试。


这两张是不是就差别比较明显了。总的来说,图像去噪,就是对于光线过于强烈时拍摄的图片进行处理。具体参数,可以自己根据情况来调整。
图像轮廓
图像轮廓,从字面意思上看就是图像的轮廓,比如说,你在抠图的时候,第一步就是找到图片的轮廓,当我们需要将图片和物体分离的时候,就需要找到物体的轮廓。表示轮廓的方法有很多,其中最常见的就是向量法,有一系列的二维顶点来表示,每个值是一个向量,将所有的向量首尾相连,就画出了轮廓线。
其实寻找轮廓很简单,对于图像而言,除了最内和最外的的轮廓,其他的轮廓其实都同时是更小一级物体的外轮廓和大一级物体的内轮廓。将各个轮廓连接起来,就形成了轮廓树。如图 :
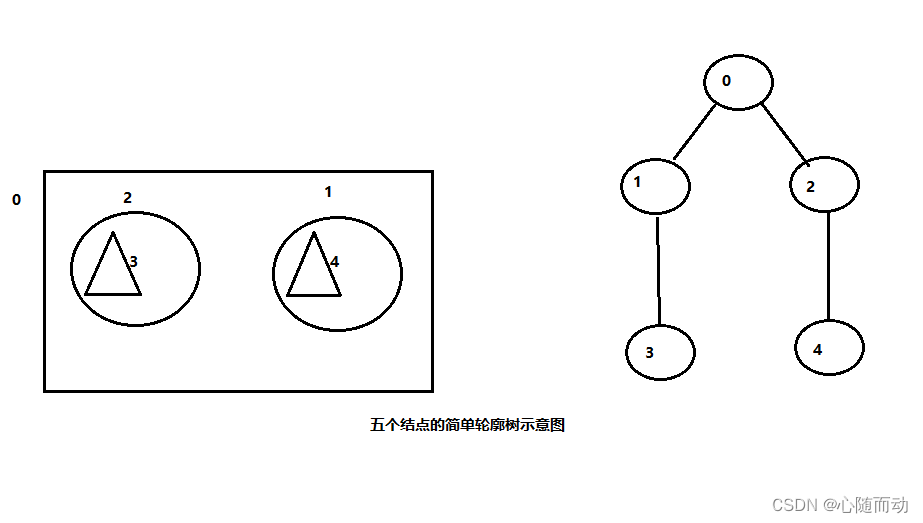
在OPenCV中,我们使用cv2.findContours()函数进行查找轮廓。此函数的可选参数为输入图像(img)、轮廓的检索模式(mode)、检索模式共有四种:只检测外轮廓(cv2.RETR_EXTERNAL)、检测的轮廓比建立等级关系(cv2.RETR_LIST)、建立两个等级的轮廓(cv2.RETR_CCOMMP)、建立一个等级树结构的轮廓(cv2.RETR_TREE)。路阔的近似办法(method)。需要注意的是,该函数的返回值有两个,一个是轮廓,另一个是每条轮廓对应的属性。
#对图片查找轮廓
import cv2
import numpy as np
img=cv2.imread('F:\Image\\test14.jpg')
#转为二值图
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret,binary=cv2.threshold(gray,127,255,cv2.THRESH_BINARY)
#查找轮廓
contours,hierarchy=cv2.findContours(binary,cv2.RETR_LIST,cv2.CHAIN_APPROX_SIMPLE)
#画出轮廓
cv2.drawContours(img,contours,-1,(0,0,0),3)
#显示图片
cv2.imshow('1',img)
cv2.waitKey(0)

当然我们可以对找到的轮廓 进行优化。OPenCV中有很多的优化方式,多边形逼近(基于DP逼近算法),使用多边形 逼近轮廓,使得顶点变少,函数为cv2.approxPolyDP();获得最小矩形框cv2.minAreaRect();获得最小包围圈cv2.minEnclosingcircle();拟合最佳轮廓线cv2.fitLine().
图像金字塔
图像金字塔,顾名思义就是有图像堆叠而成的金字塔。其实就是降采样。当我们需要对某个图像进行特征提取的时候,就会把脸部特征全部提取出来,当降低采样后,分辨率降低,这时候可能只能提取人脸的轮廓特征,就可以进行人脸轮廓对比。而当需要对比是那个人的时候,就需要更精细的图片了。
在OPenCV中,常使用cv2.pyrUp()和cv2.pyrDown()对图像进行向上和向下采样,使用cv2.buildPyramid()进行图像金字塔的搭建。
#搭建图像金字塔
import numpy as np
import cv2
img=cv2.imread('F:\Image\\test14.jpg')
#进行连续降采样
for i in range(5):
img=cv2.pyrDown(img)
cv2.imshow('{a}'.format(a=i),img)
cv2.waitKey(0) 



![]()
图像金子 塔的作用是不是显得毫无用处?不,它的用处还有其他作用,比如说两个图像的无缝衔接。所以本节的项目实战就是,图像融合。
代码实战:图像融合
采用高斯金字塔法,当降采样 到一定程度后,将两张图片进行融合,就可以消除边缘不匹配的现象。从而达到图像融合。来吧,展示!
#利用图像金字塔进行图像无缝拼接
import numpy as np
import cv2
img=cv2.imread('F:\Image\\test16.jpg')
img1=cv2.imread('F:\Image\\test17.jpg')
#resize到2的幂次方,方便处理
img=cv2.resize(img,(192,192))
img1=cv2.resize(img1,(192,192))
#降采样次数
step=3
#第一张图进行高斯金字塔计算
girl1=img.copy()
gp1=[girl1]
for i in range(step):
girl1=cv2.pyrDown(girl1)
gp1.append(girl1)
#第二张图进行高斯金字塔计算
girl2=img1.copy()
gp2=[girl2]
for i in range(step):
girl2=cv2.pyrDown(girl2)
gp2.append(girl2)
#第一张图进行拉普拉斯金字塔计算
lp1=[gp1[step]]
for i in range(step):
GE=cv2.pyrUp(gp1[step-i])
L=cv2.subtract(gp1[step-i-1],GE)
lp1.append(L)
#第二张图片进行拉普拉斯金字塔计算
lp2=[gp2[step]]
for i in range(step):
GE=cv2.pyrUp(gp2[step-i])
L=cv2.subtract(gp2[step-i-1],GE)
lp2.append(L)
#将金字塔中不同尺度层中的两种图像进行合并
mergs=[]
for i in range(step+1):
w,h,d=lp1[i].shape
merge=np.hstack((lp1[i][:,0:int(w/2-10/2**i)],lp2[i][:,int(w/2-10/2**i):]))
mergs.append(merge)
#将合并的图像进行拉普拉斯金字塔法拼接
merge=mergs[0]
for i in range(step):
merge=cv2.pyrUp(merge)
merge=cv2.add(merge,mergs[i+1])
#显示最终图像
cv2.imshow('2',merge)
cv2.waitKey(0)


前张是原图,第三张则是拼接过后的是不是违和感降低很多,但是吧,图像依旧非常的模糊,这个时候就可以使用均衡直方图来对两张照片先进行处理,效果就会好很多。前面也学习了很多图像处理的方法,都可以去尝试尝试。主要就是掌握核心的知识。好了,本节内容到此结束了。拜拜了你嘞!
