Group ViT(Semantic Segmentation Emerges from Text Supervision)CVPR2022
来自文本的监督信号,并不依赖于Segmentation mask的手工标注。而是像CLIP一样利用图像文本对使用对比学习的方式进行无监督的训练。
视觉方面做分割,grouping是一种常用的方法。如果有一些聚类的中心点,从这些中心点开始发散,把周围相似的点逐渐扩散成一个group,那这个group即相当于一个Segmentation mask。
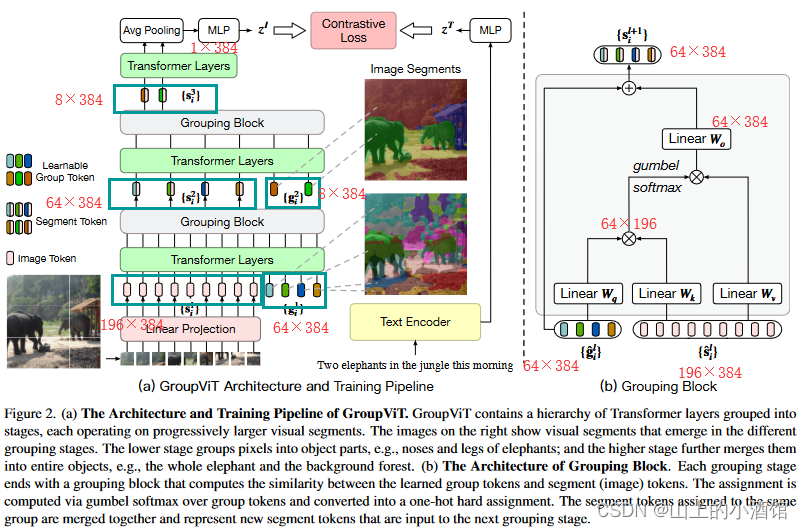
让模型在最初的时候能将周围相邻相似的像素点group起来,变成Segmentation mask。Group ViT的贡献就是在也有的ViT模型中加入Grouping Block,同时加入了可学习的Group Tokens。
图像编码器就是一个ViT,12层Transformer Layers。输入有两个部分,一个是来自原始图像的Patch Embedding,另外一个是可学习的Group Tokens。假设输入图像为224*224@3,每个patch的大小为16×16,得到14×14个196个长为384(196×384)的序列。(384对应ViT-small,特征维度384)。另外一个输入Group Tokens初始设为64×384,64可以理解为64个聚类中心,代表每张图片有64个类别。6层Transformer Layers交汇之后认为Group Tokens学的已经差不多了,聚类中心也学的不错了,加入一个Grouping Block聚类一下,合并称为更大的Group,学到一些更有语义的信息。利用Grouping Block将图像(Patch Embedding)上的直接assign到64个Group Tokens上。相当于做了一次聚类的分配。

Grouping Block先用类似自注意力的方式算了一下相似度矩阵,然后利用相似度矩阵帮助聚类中心的分配,并将196×684降维到64×384。聚类中心分配过程不可导,利用gumbel softmax将该过程变成可导的。第二阶段使用8个Group Tokens将相似的类别进一步合并,将64个Group合并为8个Group。目前图像被分成了8大块,每个块代表一个类别的特征。然后与CLIP一致,通过图像文本对算一个对比学习的loss,然后训练。CLIP中,一个文本对应一张图像的特征,很容易算一个对比学习的loss。但是现在文本端为一个特征,图像端则为8×384的8个特征,无法与文本特征匹配。作者使用了Avg Pooling的方式。得到一个1×384的特征,这样文本特征和图像特征就可以匹配起来了。
python的学习还是要多以练习为主,想要练习python的同学,推荐可以去看,他们现在的IT题库内容很丰富,属于国内做的很好的了,而且是课程+刷题+面经+求职+讨论区分享,一站式求职学习网站,最最最重要的里面的资源全部免费。

他们这个python的练习题,知识点编排详细,题目安排合理,题目表述以指导的形式进行。整个题单覆盖了Python入门的全部知识点以及全部语法,通过知识点分类逐层递进,从Hello World开始到最后的实践任务,都会非常详细地指导你应该使用什么函数,应该怎么输入输出。
牛客网(牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网)还提供题解专区和讨论区会有大神提供题解思路,对新手玩家及其友好,有不清楚的语法,不理解的地方,看看别人的思路,别人的代码,也许就能豁然开朗。
快点击下方链接学起来吧!
牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网
参考:

接下来看模型如果做zero-shot的推理过程。文本和图像分别经过各自的编码器得到文本特征和图像特征,然后计算相似度,得到最匹配的图像文本对。局限性在于最后的聚类中心(Group Tokens)只有8类,从一张图像中最多分割出八个目标。
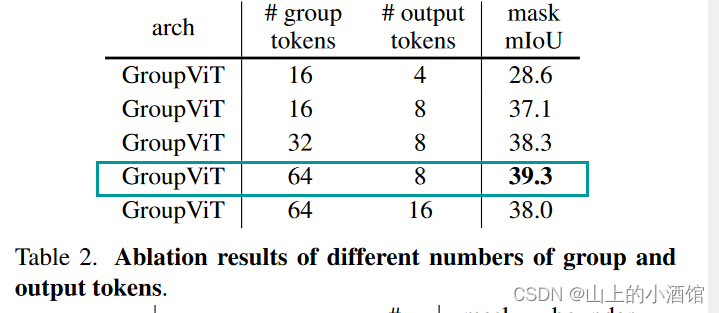
作者也做了消融实验,发现64-8的组合效果最好。

每个阶段可视化如图所示,第一阶段中Group5的类别为眼睛,图中确实可以将不同生物眼睛很好的分割出来。第二阶段对应大的目标区域,第三行第二阶段Group6对应类别草地,草地也被较好的分割出来。Grouping Token起到了聚类中心的作用,用Grouping这种思想完成无监督的分割。
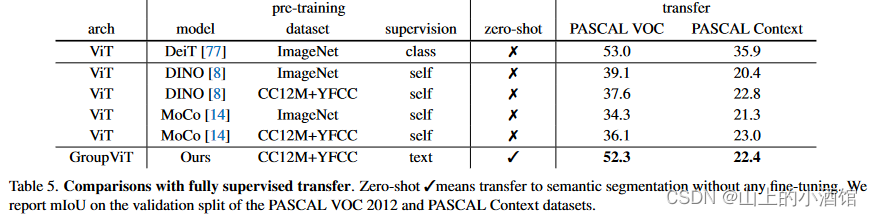
与baselin方法比起来确实有提升,第一个用文本做监督信号的工作。还可以做zero-shot 的推理。但是对于有监督的模型如DeepLabV3plus已经达到了87左右的mlou,高了30多个点。
未来工作,一是没有使用dense prediction的特性,如空洞卷积、金字塔池化以及U-Net的结构,从而获取更多的上下文信息和多尺度信息。另一方面是推理过程中,作者设定了相似度阈值0.9,对于相似度小于0.9的阈值,则认为是背景类。