vision grounding任务:给你一句话,你去把这句话里的物体在当前图片中定位出来。就类似一个目标检测任务。
CLIP是一个图像文本配对任务。
将两个任务结合起来,再加入伪标签(self training),这样模型就可以在没有标注过的图像文本对上生成bbox标签。从而扩张整个训练数据集的数量。

图像先经过图像编码器得到目标/区域特征O,然后经过一个分类头,也就是乘权重矩阵W得到输出类别的logits Scls,然后计算Scls与真实类别的交叉熵损失。
grounding模型中,作者计算了匹配分数,看图像中的区域怎么与句子中的单词匹配上(点乘相似度)。

图像和句子分别经过各自的编码器得到各自的特征image embedding和text embedd,然后计算匹配度,其实就是ViLD中的ViLD-text分支。
经过理论验证,vision grounding与检测这两个任务是可以统一起来的,然后又经过实验,在COCO上的分数也是完全匹配的。GLIP是完全可以迁移到任何一个目标检测的数据集上得。接下来就是看如何扩大数据集,如何将预训练模型训练的更好。
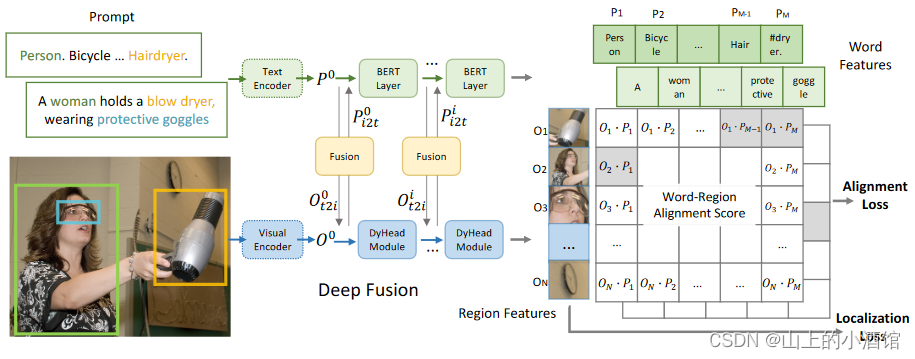
图像过图像编码器得到image embedding,文本过文本编码器得到text embedding。
Deep Fusion:当文本特征和图像特征被抽取之后,理论上可以直接计算相似度矩阵。但是直接算的话,图像文本的joint embedding space(结合后的特征空间)还没有学的很好(Lseg通过conv继续学习)。多加一些层数融合一下,相似的概念拉近一些,关联性更强,最后算相似度也更有针对性。具体就是用cross attention交互了一下。
目标函数,有监督的方式,时时刻刻都有bbox,抽取出的目标/区域特征模型是知道和哪个单词对应的。算完点乘后可以去算Alignment loss(匹配损失)。这样就完成了文本和图像特征的融合,接下来就可以做zero-shot。对于定位location-loss来说,算一个最基本的L1-loss就可以了。
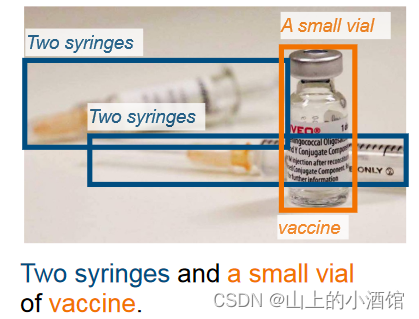

作者展示了两个非常难的任务,一是检测两个针管和一瓶疫苗。现有的数据集中似乎没有针管和疫苗这种类别。但是GLIP自己做出来对文本的理解,给出了疫苗和针管的检测结果。下边这个例子是一张图片的描述,都是一些比较抽象的概念,但是GLIP也能做得很好。

最新的很多工作DyHead和SoftTeacher没有zero-shot能力,但是经过微调后在COCO数据集上能够达到60左右的AP。GLIP-L具有zero-shot 的能力,能够达到将近50的AP,而且微调后也能达到60多一点的AP。整体来看效果还是不错的。
python的学习还是要多以练习为主,想要练习python的同学,推荐可以去看,他们现在的IT题库内容很丰富,属于国内做的很好的了,而且是课程+刷题+面经+求职+讨论区分享,一站式求职学习网站,最最最重要的里面的资源全部免费。
他们这个python的练习题,知识点编排详细,题目安排合理,题目表述以指导的形式进行。整个题单覆盖了Python入门的全部知识点以及全部语法,通过知识点分类逐层递进,从Hello World开始到最后的实践任务,都会非常详细地指导你应该使用什么函数,应该怎么输入输出。
牛客网(牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网)还提供题解专区和讨论区会有大神提供题解思路,对新手玩家及其友好,有不清楚的语法,不理解的地方,看看别人的思路,别人的代码,也许就能豁然开朗。
快点击下方链接学起来吧!
牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网
参考: