1.介绍
BLIP-2通过轻量级的查询转换器弥补了模态缺口,该转换器分两个阶段进行预训练。第一阶段从冻结图像编码器中引导视觉语言表示学习。第二阶段从冻结的语言模型中引导视觉到语言生成性学习。
1.1 动机
是想要在现成的语言和视觉的单模态模型中获得视觉语言模型
1.2 难点
LLM在其单模态预训练过程中没有看到图像,因此冻结它们使视觉语言对齐特别具有挑战性。
1.3 提出的解决办法 :QFormer
Q-Former是一个轻量级的Transformer,使用一组可学习的查询向量来从冻结图像编码器中提取视觉特征。

在第一个预训练阶段,我们进行视觉语言表征学习,这强制Q-Former学习与文本最相关的视觉表征。
在第二个预训练阶段,我们通过将Q-Former的输出连接到冻结的LLM来执行视觉到语言生成学习,并训练Q-Former,使其输出的视觉表示可以被LLM解释。
2.方法
2.1 模型架构
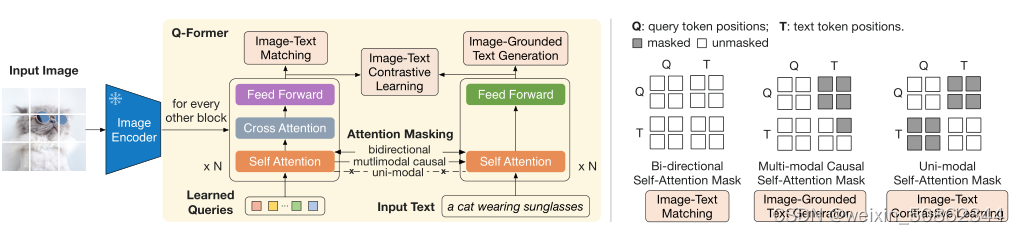
- Q-Former由两个转换器子模块组成,它们共享相同的自注意层:(1)与冻结图像编码器交互进行视觉特征提取的图像转换器,(2)既可以用作文本编码器又可以用作文本解码器的文本转换器。
- 创建了一组可学习的查询嵌入作为图像转换器的输入。查询通过自关注层相互交互,并通过交叉关注层(每隔一个transformer块插入)与冻结的图像特征交互
- 通过相同的自关注层与文本进行交互。
2.2 冻结图像编码器学习视觉语言表示
- 图像-文本对比学习(ITC) :通过对比正对与负对的图像文本相似性
首先计算每个查询输出与t之间的成对相似性,然后选择最高的一个作为图像-文本相似性。
为了避免查询和文本信息相互泄露泄露,我们使用了一个单峰自注意掩码
- 基于图像的文本生成(ITG):不允许冻结图像编码器和文本令牌之间的直接交互,因此生成文本所需的信息必须首先由查询提取,然后通过自关注层传递给文本tokens
使用多模态因果自注意掩码来控制查询-文本交互
将[CLS]tokens替换为新的[DEC]tokens,作为通知解码任务的第一个文本tokens
- 图像-文本匹配(ITM):预测图像-文本对是否匹配
使用双向自我关注掩码
将每个输出查询的嵌入输入到两类线性分类器中获得logit,并将所有查询的logit平均作为输出匹配分数。
2.3 冻结的LLM学习视觉到语言表示

使用全连接(FC)层将输出查询嵌入Z线性投影到与LLM的文本嵌入相同的维度中,然后将投影的查询嵌入预处理为输入文本嵌入。
三.代码
因为是ALBEF和BLIP原班人马的工作,同样是使用到之前工作的很多技巧。
BLIP-2分为三个阶段:①冻结视觉模型: 训练视觉模型到Q-former的映射关系(此时不引入LLM) ②冻结视觉模型和LLM模型训练 :视觉模型到Q-former到LLM的映射关系 ③解冻:微调
3.1 第一阶段:Blip2Qformer
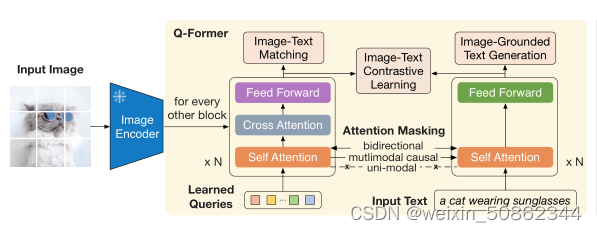
第一个阶段不引入LLM,整体架构如下图所示

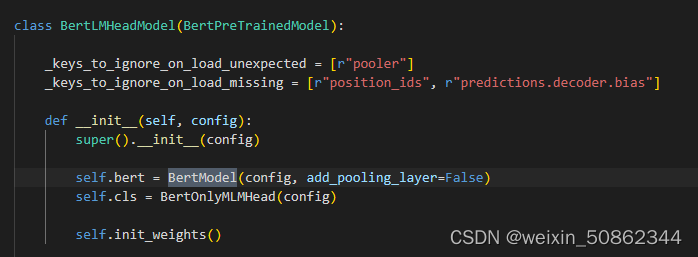
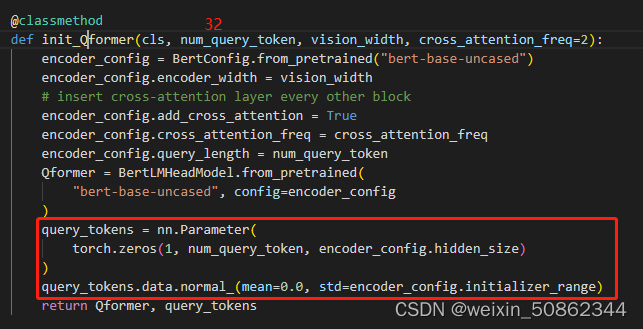
初始化了BertLMHeadModel(bert + cls【其实就是ffn】)模型作为Qformer并使用了一个query_tokens作为Learned Queries
- 使用 Image-text Contrastive(ITC), Image-text Matching(ITM) 和Image Captioning。前两个也是老生常谈了,在 ALBEF和BLIP中都有类似的损失函数并类似地用上了hard-tough样本选取等技巧。最后一个任务使用了Image Captioning(但其实感觉本质还是lm任务)。
- 其中Qformer中的bert被反复使用从而共享SA层其中参数
3.1.1 Image Captioning

其实Qformer就是一个bert模型+一个ffn最后使用因果关系作为输出
3.2 第二阶段:Blip2OPT
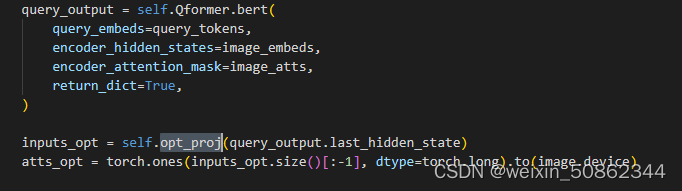
第二个阶段引入LLM,冻结视觉和LLM,LLM部分同时输入query_output和text。
整体架构如下图所示:
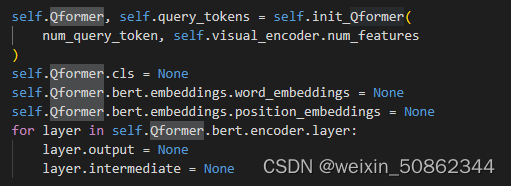
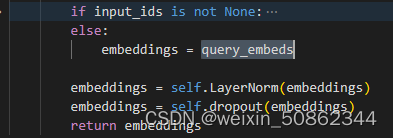
此时Qformer中就剩个bert模型,在BertEmbeddings也中不做位置和单词的嵌入,只对输入的query_embeds做一次LN和dropout
线性映射到LLM模型
3.2 第三阶段:微调
使用的模型依旧是Blip2OPT,解冻了视觉部分但是仍然不解冻LLM部分