文章目录
Prometheus原理介绍
目前Prometheus支持OpenTsdb、InfluxDB、Elasticsearch等后端存储,通过适配器实现Prometheus存储的remote write和remote read接口,便可以接入Prometheus作为远程存储使用
介绍
Prometheus由Go语言编写而成,采用Pull方式获取监控信息,并提供了多维度的数据模型和灵活的查询接口。Prometheus不仅可以通过静态文件配置监控对象,还支持自动发现机制,能通过Kubernetes、Consl、DNS等多种方式动态获取监控对象。在数据采集方面,借助Go语音的高并发特性,单机Prometheus可以采取数百个节点的监控数据;在数据存储方面,随着本地时序数据库的不断优化,单机Prometheus每秒可以采集一千万个指标,如果需要存储大量的历史监控数据,则还支持远程存储。
Prometheus简介
Prometheus是由SoundCloud开发的开源监控系统的开源版本。2016年,由Google发起的Linux基金会(Cloud Native Computing Foundation,CNCF)将Prometheus纳入其第二大开源项目。Prometheus在开源社区也十分活跃
Prometheus优缺点
- 提供多维度数据模型和灵活的查询方式,通过将监控指标关联多个tag,来将监控数据进行任意维度的组合,并且提供简单的PromQL查询方式,还提供HTTP查询接口,可以很方便地结合Grafana等GUI组件展示数据
- 在不依赖外部存储的情况下,支持服务器节点的本地存储,通过Prometheus自带的时序数据库,可以完成每秒千万级的数据存储;不仅如此,在保存大量历史数据的场景中,Prometheus可以对接第三方时序数据库和OpenTSDB等。
- 定义了开放指标数据标准,以基于HTTP的Pull方式采集时序数据,只有实现了Prometheus监控数据才可以被Prometheus采集、汇总、并支持Push方式向中间网关推送时序列数据,能更加灵活地应对多种监控场景
- 支持通过静态文件配置和动态发现机制发现监控对象,自动完成数据采集。Prometheus目前已经支持Kubernetes、etcd、Consul等多种服务发现机制
- 易于维护,可以通过二进制文件直接启动,并且提供了容器化部署镜像。
- 支持数据的分区采样和联邦部署,支持大规模集群监控
Prometheus特性
- ① 多维的数据模型(基于时间序列的Key、value键值对)
- ② 灵活的查询和聚合语言PromQL
- ③ 提供本地存储和分布式存储
- ④ 通过基于HTTP和HTTPS的Pull模型采集时间序列数据(pull数据的推送,时间序列:每段
时间点的数据值指标,持续性的产生。横轴标识时间,纵轴为数据值,一段时间内数值的动态变化,所有的点连线形成大盘式的折线图) - ⑤ 可利用Pushgateway (Prometheus的可选中间件)实现Push模式
- ⑥ 可通过动态服务发现或静态配置发现目标机器(通过consul自动发现和收缩)
- ⑦ 支持多种图表和数据大盘
4、Prometheus架构
Prometheus的基本原理是通过HTTP周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口并符合Prometheus定义的数据格式,就可以介入Prometheus监控
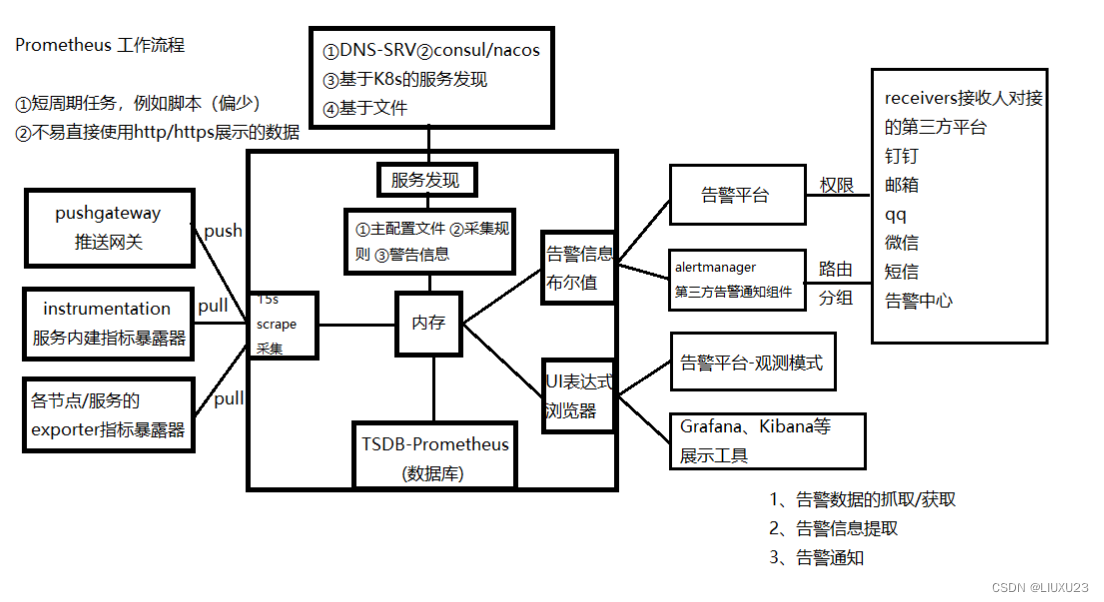
Prometheus Server负载定时在目标上抓取metrics(指标)数据,每个抓取目标都需要暴露一个HTTP服务接口用于Prometheus定时抓取。这种调用被监控对象获取监控数据的方式被称为Pull(拉)。Pull方式体现了Prometheus独特的设计哲学与大多数采用Push(推)方式的监控不同
Pull方式的优势是能够自动进行上游监控和水平监控,配置更少,更容易扩展,更灵活,更容易实现高可用。简单来说就是Pull方式可以降低耦合。由于在推送系统中很容易出现因为向监控系统推送数据失败而导致被监控系统瘫痪的问题。所以通过Pull方式,被采集端无需感知监控系统的存在,完全独立于监控系统之外,这样数据的采集完全由监控系统控制
prometheus监控体系
(一)监控体系:
① 系统层监控(需要监控的数据)
1.CPU、Load、Memory、swap、disk i/o、process等
2.网络监控:网络设备、工作负载、网络延迟、丢包率等
② 中间件及基础设施类监控
1.消息中间件:kafka、RocketMQ、等消息代理
2.WEB服务器容器:tomcat
3.数据库/缓存数据库:MySQL、PostgreSQL、MogoDB、es、redis
redis监控内容:
redis所在服务器的系统层监控
redis 服务状态
RDB AOF日志监控
日志——>如果是哨兵模式——>哨兵共享集群信息,产生的日志——>直接包含的其他节点哨兵信息及mysql信息
③ 应用层监控
用于衡量应用程序代码状态和性能
监控的分类:黑盒监控,白盒监控
PS:
白盒监控,自省指标,等待被下载
黑盒指标:基于探针的监控方式,不会主动干预、影响数据
④ 业务层监控
用于衡量应用程序的价值,如电商业务的销售量,ops、dau日活、转化率等,业务接口:登入数量,注册数、订单量、搜索量和支付量
Prometheus特点
- 自定义多维数据模型(时序列数据由metric名和一组key/value标签组成)
- 非常高效的储存平均一个采样数据占大约3.5bytes左右,320万的时间序列,每30秒采样,保持60天,消耗磁盘大概228G
- 在多维上灵活且强大的查询语句(PromQL)
- 不依赖分布式储存,支持单主节点工作
- 通过基于HTTP的pull方式采集时序数据
- 可以通过push gateway进行时序列数据库推送(pushing)
- 可以通过服务发现或静态配置去获取要采集的目标服务器
- 多种可视化图表及仪表盘支持
使用场景
Prometheus可以很好地记录任何纯数字时间序列。它既适用于以机器为中心的监视,也适用于高度动态的面向服务的体系结构的监视。在微服务世界中,它对多维数据收集和查询的支持是一种特别的优势。(k8s)
Prometheus是为可靠性而设计的,它是您在中断期间要使用的系统,可让您快速诊断问题。每个Prometheus服务器都是独立的,而不依赖于网络存储或其他远程服务。当基础结构的其他部分损坏时,您可以依靠它,并且无需设置广泛的基础结构即可使用它
不适合的场景
Prometheus重视可靠性。即使在故障情况下,您始终可以查看有关系统的可用统计信息。如果您需要100%的准确性(例如按请求计费),则Prometheus并不是一个不错的选择,因为所收集的数据可能不会足够详细和完整。在这种情况下,最好使用其他系统来收集和分析数据以进行计费,并使用Prometheus进行其余的监视。
prometheus时序数据
时序数据,是在一段时间内通过重复测量(measurement)而获得的观测值的集合将这些观测值绘制于图形之上,它会有一个数据轴和一个时间轴,服务器指标数据、应用程序性能监控数据、网络数据等也都是时序数据;
1.数据来源:
prometheus基于HTTP call (http/https请求),从配置文件中指定的网络端点(endpoint/IP:端口)上周期性获取指标数据。
很多环境、被监控对象,本身是没有直接响应/处理http请求的功能,prometheus-exporter则可以在被监控端收集所需的数据,收集过来之后,还会做标准化,把这些数据转化为prometheus可识别,可使用的数据(兼容格式)
2.收集数据:
监控概念:白盒监控、黑盒监控
白盒监控:自省方式,被监控端内部,可以自己生成指标,只要等待监控系统来采集时提供出去即可
黑盒监控:对于被监控系统没有侵入性,对其没有直接"影响",这种类似于基于探针机制进行监控(snmp协议)
Prometheus支持通过三种类型的途径从目标上"抓取(Scrape)"指标数据(基于白盒监控);
Exporters ——>工作在被监控端,周期性的抓取数据并转换为pro兼容格式等待prometheus来收集,自己并不推送
Instrumentation ——>指被监控对象内部自身有数据收集、监控的功能,只需要prometheus直接去获取
Pushgateway ——>短周期5s—10s的数据收集
3.prometheus(获取方式)
Prometheus同其它TSDB相比有一个非常典型的特性:它主动从各Target上拉取(pull)数据,而非等待被监控端的推送(push)
两个获取方式各有优劣,其中,Pull模型的优势在于:
集中控制:有利于将配置集在Prometheus server上完成,包括指标及采取速率等;
Prometheus的根本目标在于收集在rarget上预先完成聚合的聚合型数据,而非一款由事件驱动的存储系统
通过targets(标识的是具体的被监控端)
比如配置文件中的 targets:[‘localhost:9090’]
prometheus生态组件
prometheus生态圈中包含了多个组件,其中部分组件可选
- Prometheus Server:收集和储存时间序列数据
通过scraping以刮擦的方式去获取数据放入storge(TSDB时序数据库),制定Rules/Alerts:告警规则,service discovery是自动发现需要监控的节点 - Client Library:客户端库目的在于为那些期望原生提供Instrumentation功能的应用程序提供便捷的开发途径;
- Push Gateway:接收那些通常由短期作业生成的指标数据的网关,并支持由Prometheus Server进行指标拉取操作;
- Exporters:用于暴露现有应用程序或服务(不支持Instrumentation)的指标给Prometheus Server而pro内建了数据样本采集器,可以通过配置文件定义,告诉prometheus到那个监控对象中采集指标数据,prometheus 采集过后,会存储在自己内建的TSDB数据库中,提供了promQL 支持查询和过滤操作,同时支持自定义规则来作为告警规则,持续分析一场指标,一旦发生,通知给alerter来发送告警信息,还支持对接外置的UI工具(grafana)来展示数据
采集、抓取数据是其自身的功能,但一般被抓去的数据一般来自于:export/instrumentation (指标数据暴露器) 来完成的,或者是应用程序自身内建的测量系统(汽车仪表盘之类的,测量、展示)来完成 - Alertmanager:由告警规则对接,从Prometheus Server接收到"告警通知"后,通过去重、分
组、路由等预处理功能后以高效向用户完成告警信息发送 - Data Visualization(Dashboards): 与TSDB对接并且展示数据库中的数据,Prometheus web UI (Prometheus Server内建),及Grafana等;
- Service Discovery:动态发现待监控的Target,从而完成监控配置的重要组件,在容器化环境中尤为有用;该组件目前由PropetheusServer内建支持
Exporters介绍
node-exporter组件,因为prometheus抓取数据是通过http的方式调用的,假如抓取的数据是操作系统的资源负载情况,而linux操作系统内核是没有内置任何http协议的,并不支持直接通过http方式进行,所以需要在每个被监控端安装node-exporter,由其向内核中拿取各种状态信息,然后再通过prometheus兼容的指标格式暴露给prometheus
对于那些未内建Instrumentation,且也不便于自行添加该类组件以暴露指标数据的应用程序来说,常用的办法是于待监控的目标应用程序外部运行一个独立指标暴露程序,该类型的程序即统称为Exporter。
PS:Prometheus站点上提供了大量的Exporter,如果是docker技术跑多个服务就要使用docker-exportes监控系统环境,而docker容器内部服务的监控需要使用cAdvisor容器
alerts(告警)介绍
抓取异常值,异常值并不是说服务器的报警只是根据用户自定义的规则标准,prometheus通过告警机制发现和发送警示。
alter负责:告警只是prometheus基于用户提供的"告警规则"周期计算生成,好的监控可以事先预告报警、并提前处理的功能alter接受服务端发送来的告警指示,基于用户定义的告警路由(route)向告警接收人(receivers)发送告警信息(可由用户定义)
ps:在数据查询,告警规则里面会使用到promQL语句
prometheus server
内建了数据样本采集器,可以通过配置文件定义,告诉Prometheus到哪个监控对象中采集指标数据,prometheus采集过后,会存储在自己内建的TSDB数据库中,提供了promQL,支持查询和过滤操作,同时支持自定义规则来作为告警规则,持续分析一场指标,一旦发生,通知给alter来发送报警信息,还支持对接外置的ui工具(grafana)来展示数据,prometheus自带的web展示图像信息比较简单。
采集、抓取数据是其自身的功能。但一般来自于export/instrumentation(指标数据的暴露)来完成,或者是服务自身的内建的测量系统来完成
Prometheus部署
服务器分配
主机名 地址 安装包
prometheus 192.168.32.10 prometheus-2.27.1.linux-amd64.tar.gz
server1 192.168.32.20 node_exporter-1.1.2.linux-amd64.tar.gz
server2 192.168.32.30
server3 192.168.32.40
所有主机
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
vim /etc/selinux/config
SELINUX=disabled
vim /etc/reslove.conf
nameserver 114.114.114.114
ntpdate ntp1.aliyun.com #时间同步

上传安装包到/opt
tar zxvf prometheus-2.37.1.linux-amd64.tar.gz -C /usr/local

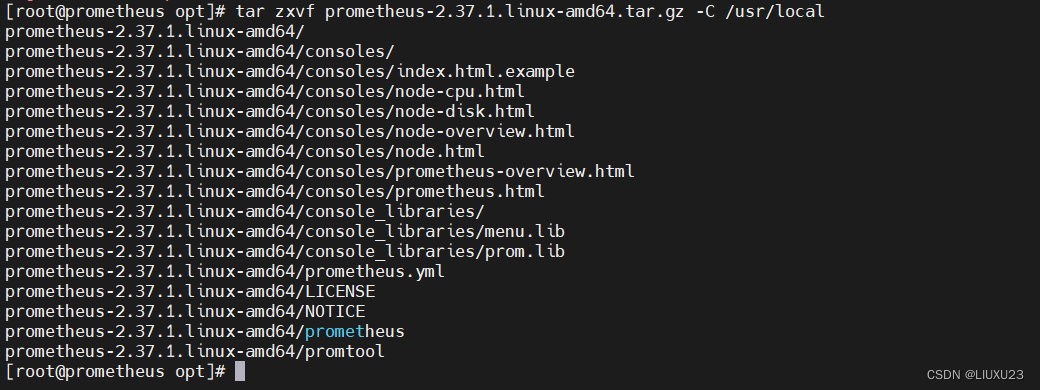
cd /usr/local/prometheus-2.37.1.linux-amd64
cat prometheus.yml
# my global config
global: //全局组件
//每隔多久抓取一次指标,不设置默认1分钟
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
//内置告警规则的评估周期
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
//对接的altermanager(第三方告警模块)
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files: //告警规则
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus' //对于指标需要打上的标签,对于PrometheusSQL(查询语句)的标签:比如prometheus{target='values'}
# metrics_path defaults to '/metrics' //收集数据的路径
# scheme defaults to 'http'.
static_configs: //对于Prometheus的静态配置监听端口具体数据收集的位置 默认的端口9090
- targets: ['localhost:9090']
2.运行服务查看端口是否开启
直接开启Prometheus
./prometheus
另开一个终端查看9090端口
ss -natp | grep 9090

访问web页面(表达式浏览器)
1、查看表达式浏览器
访问192.168.32.10:9090
通过http://192.168.32.10:9090/metrics可以查看到监控的数据:
(五)部署监控其他节点
prometheus想要监控其他节点,则需要借助node_exporter,下载地址http://prometheus.io/download/
1.解压安装包,命令优化路径,设置服务控制,开启服务
tar zxvf node_exporter-1.4.0.linux-amd64.tar.gz


cd node_exporter-1.4.0.linux-amd64
cp node_exporter /usr/local/bin #f复制命令让系统可以识别

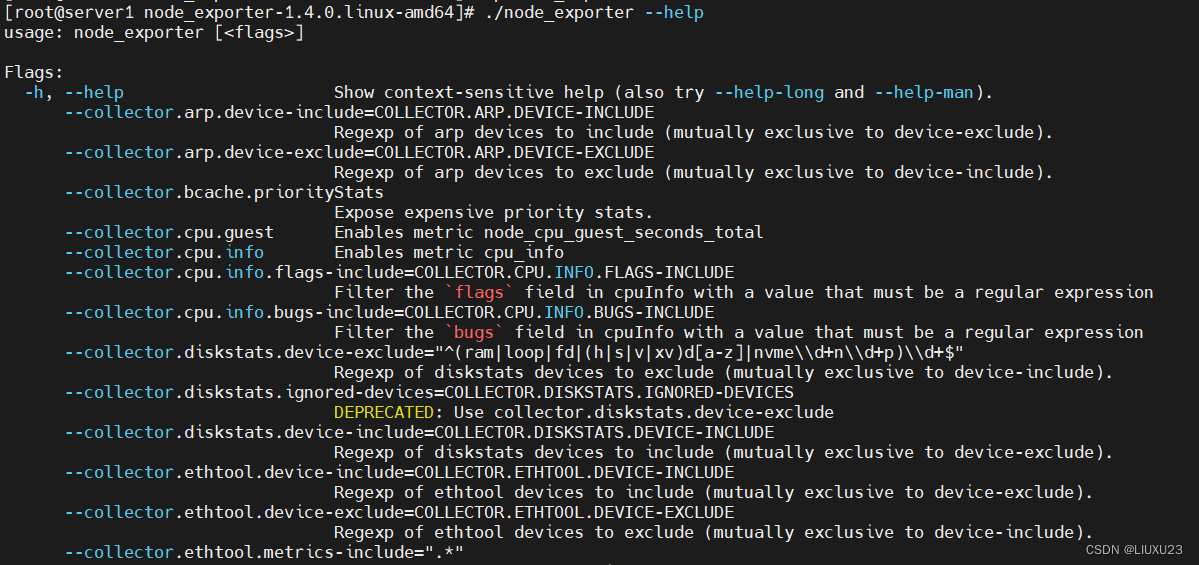
./node_exporter --help #查看命令可选项
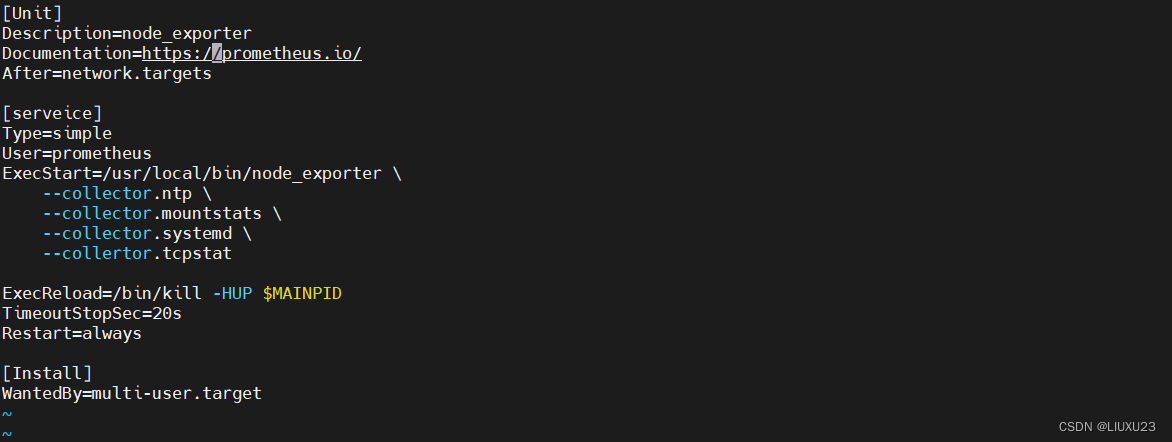
服务开启方式一,使用systemctl控制
vim /usr/lib/systemd/system/node_exporter.service
[Unit]
Description=mysqld_exporter
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/bin/node_exporter \
--collector.ntp \
--collector.mountstats \
--collector.systemd \
--collector.tcpstat
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target

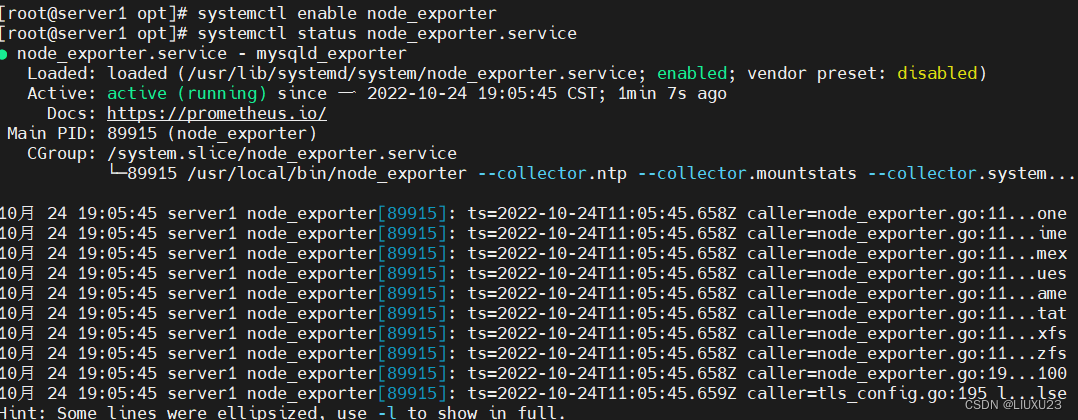
2.访问192.168.32.20:9100/metrics 查看抓取内容在这里插入代码片在这里插入代码片
若需要加入其他节点监控端,则需要在192.168.32.10 prometheus服务端停止prometheus修改配置文件添加静态targets才能使得server1节点加入
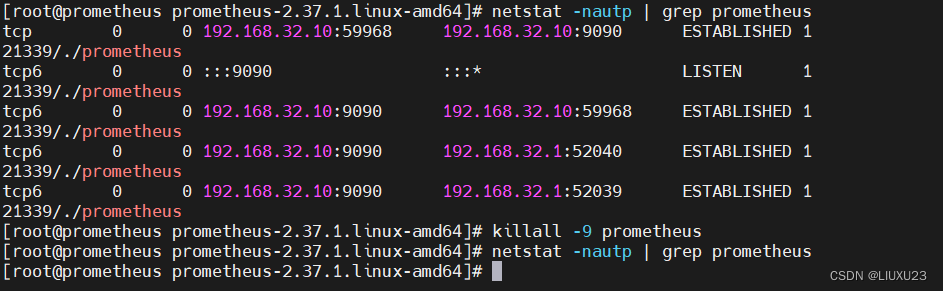
netstat -nautp | grep prometheus
killall -9 prometheus
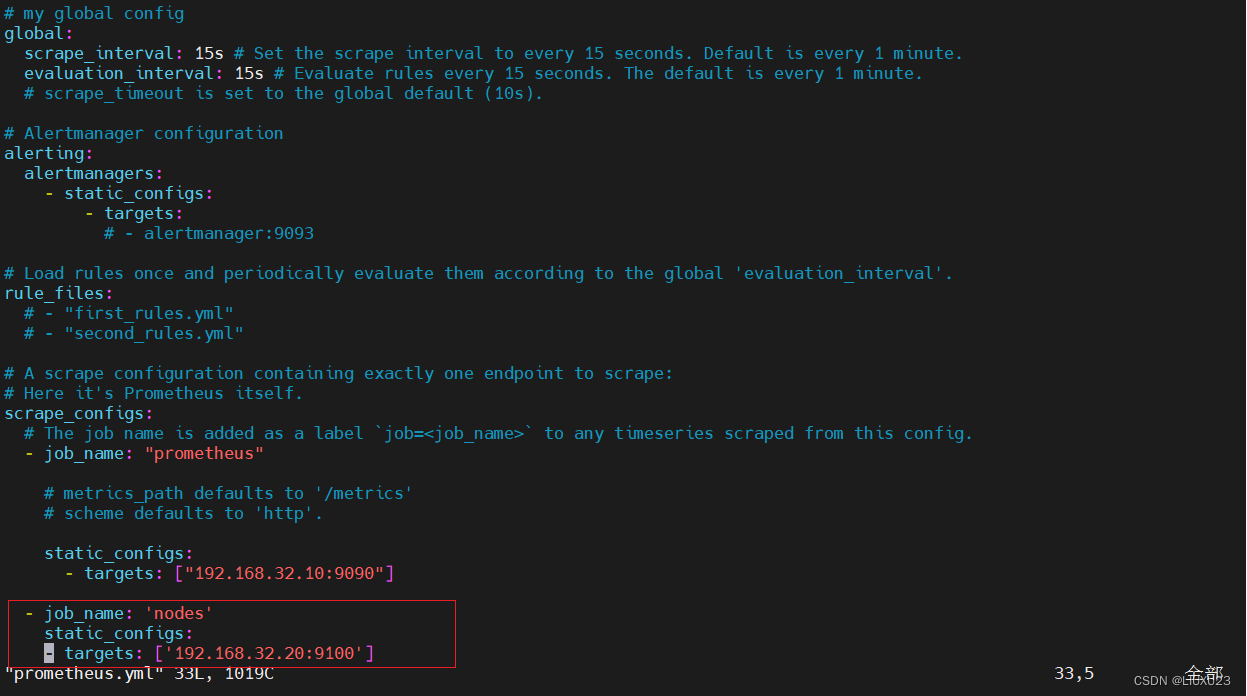
vim /usr/local/prometheus-2.37.1.linux-amd64/prometheus.yml
改完配置文件后,重启服务
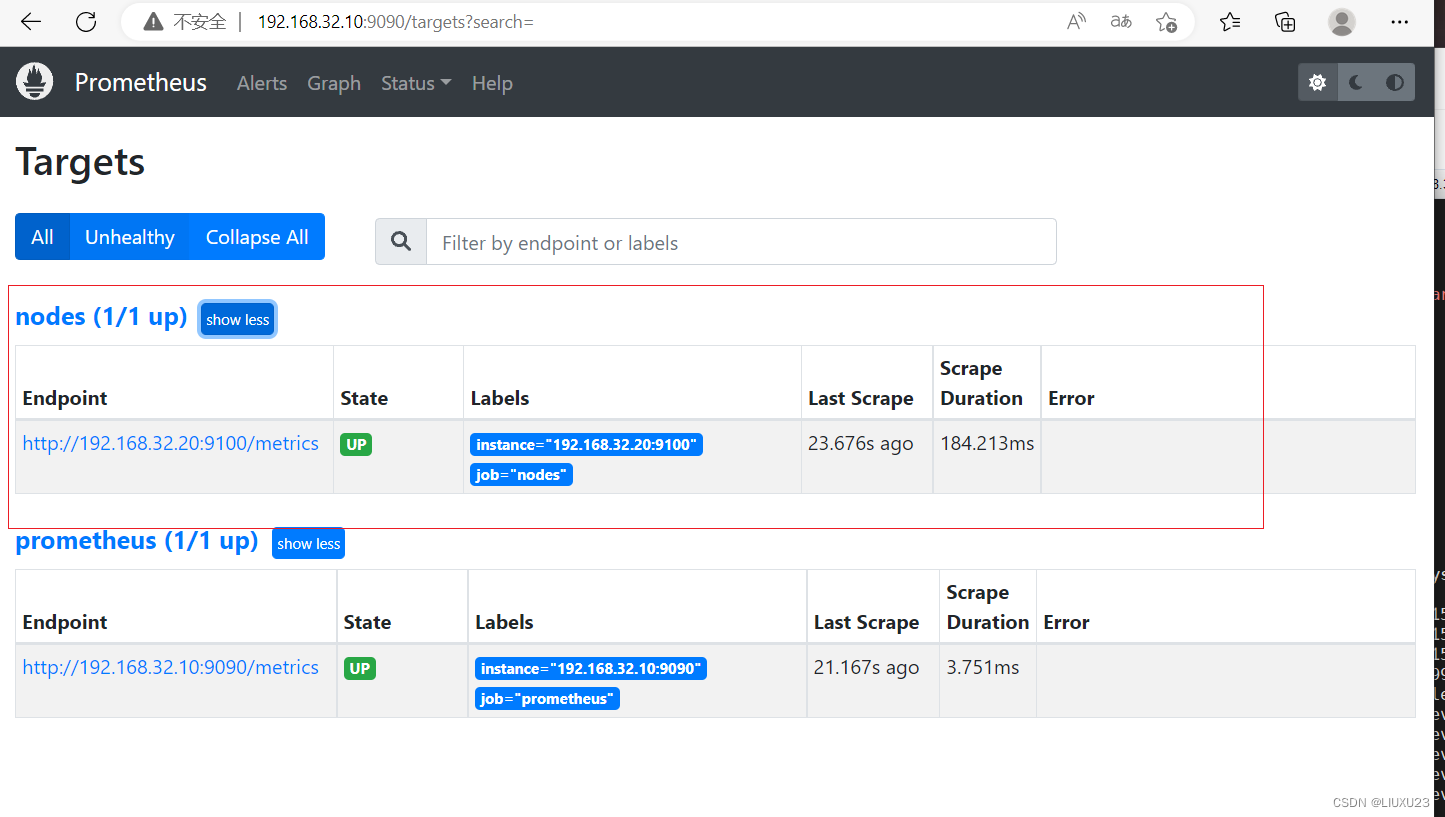
访问prometheus服务器
回到 web 管理界面→点 Status→点 Targets→可以看到多了一台监控目标
同样方式部署server2、3节点
tar zxvf node_exporter-1.4.0.linux-amd64.tar.gz

cd node_exporter-1.4.0.linux-amd64
cp node_exporter /usr/local/bin
./node_exporter
停止服务,修改重启
在192.168.32.10中修改vim /usr/local/prometheus-2.37.1.linux-amd64/prometheus.yml
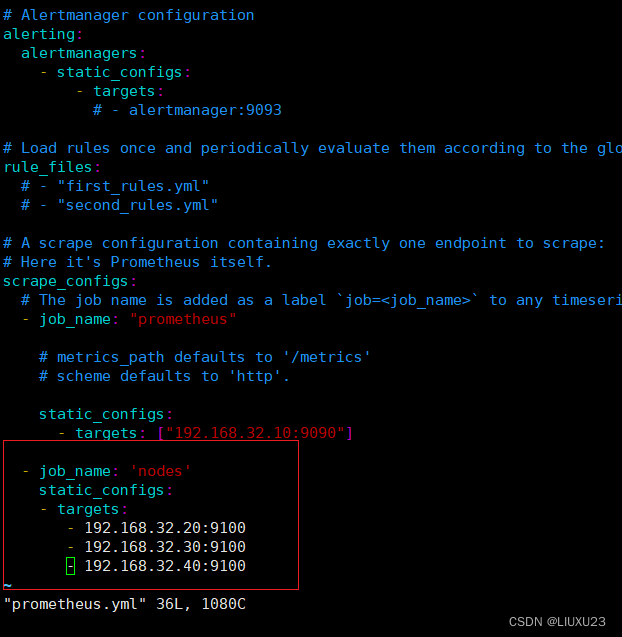
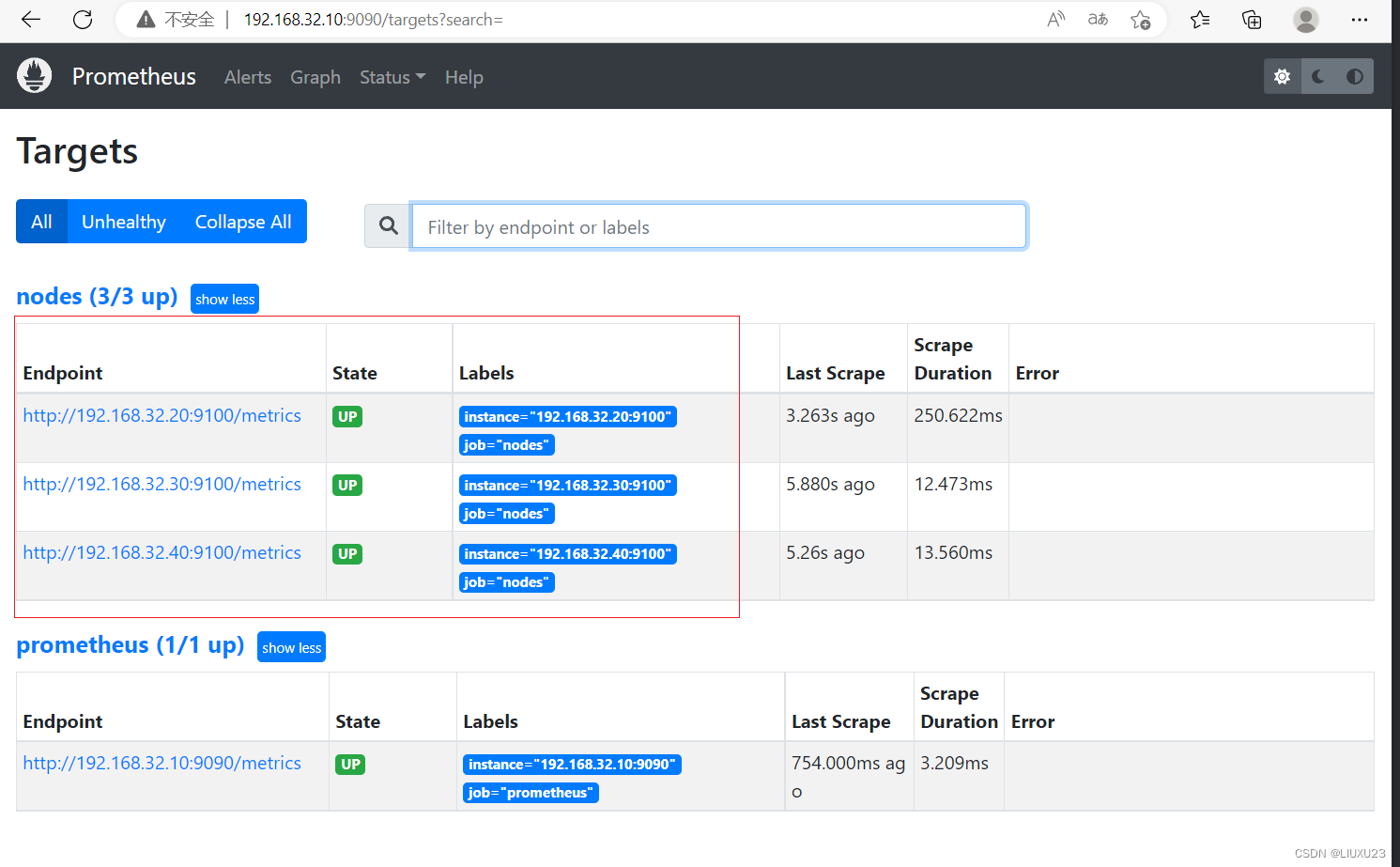
表达式浏览器
2、表达式浏览器常规使用
在prometheusUI控制台上可以进行数据过滤
简单的用法:
CPU使用总量
node_cpu_seconds_total
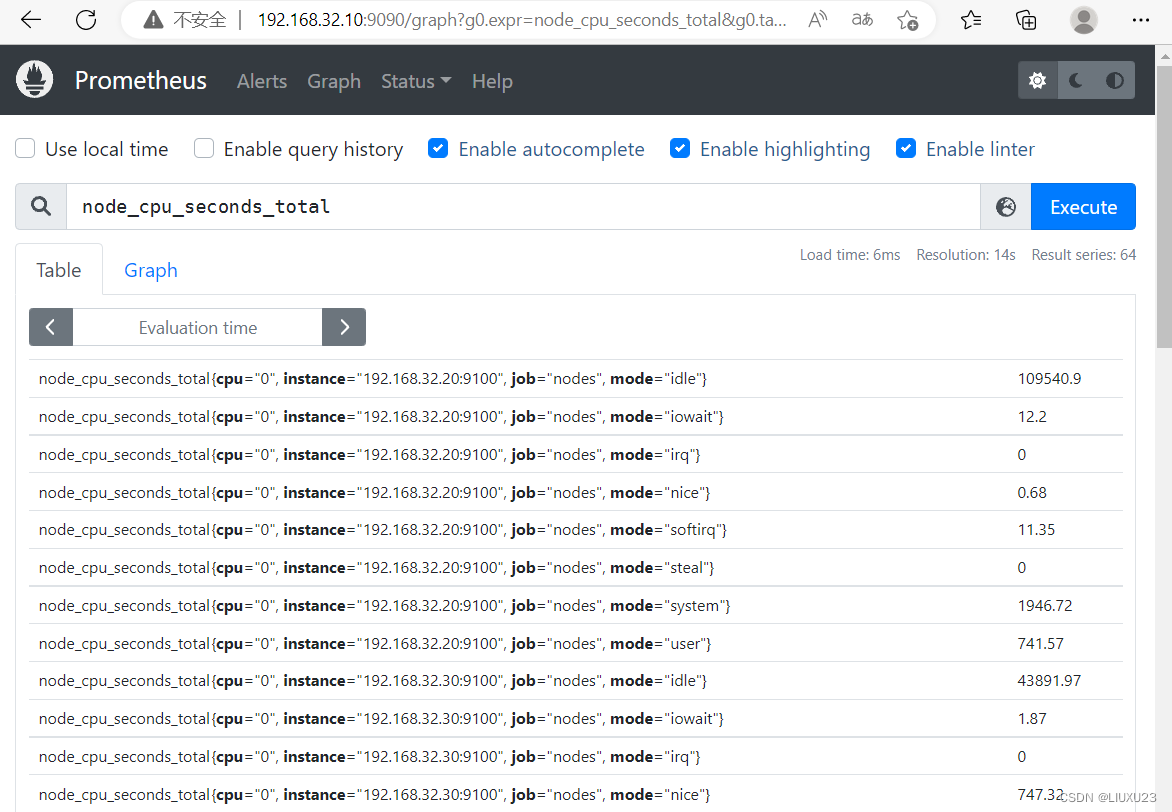
#进阶1:
计算过去5分钟内的CPU使用速率
PromQL: irate(node_cpu_seconds_total{mode="idle"}[5m])
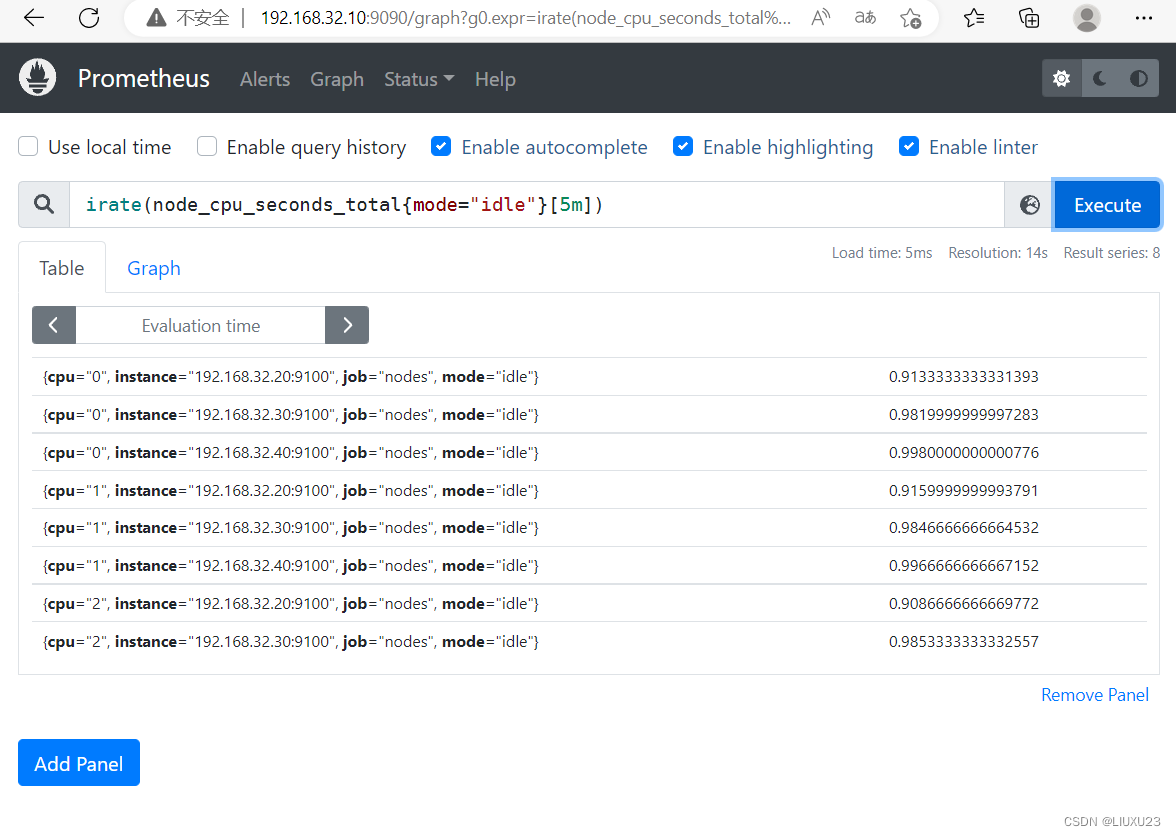
解析:
irate:速率计算函数(灵敏度非常高的)
node_cpu_seconds_total:node节点CPU使用总量
mode=“idle” 空闲指标
5m:过去的5分钟内,所有CPU空闲数的样本值,每个数值做速率运算
#进阶2:
每台主机CPU 在5分组内的平均使用率
PromQL:(1- avg (irate(node_cpu_seconds_total{mode='idle'}[5m]))by (instance))* 100
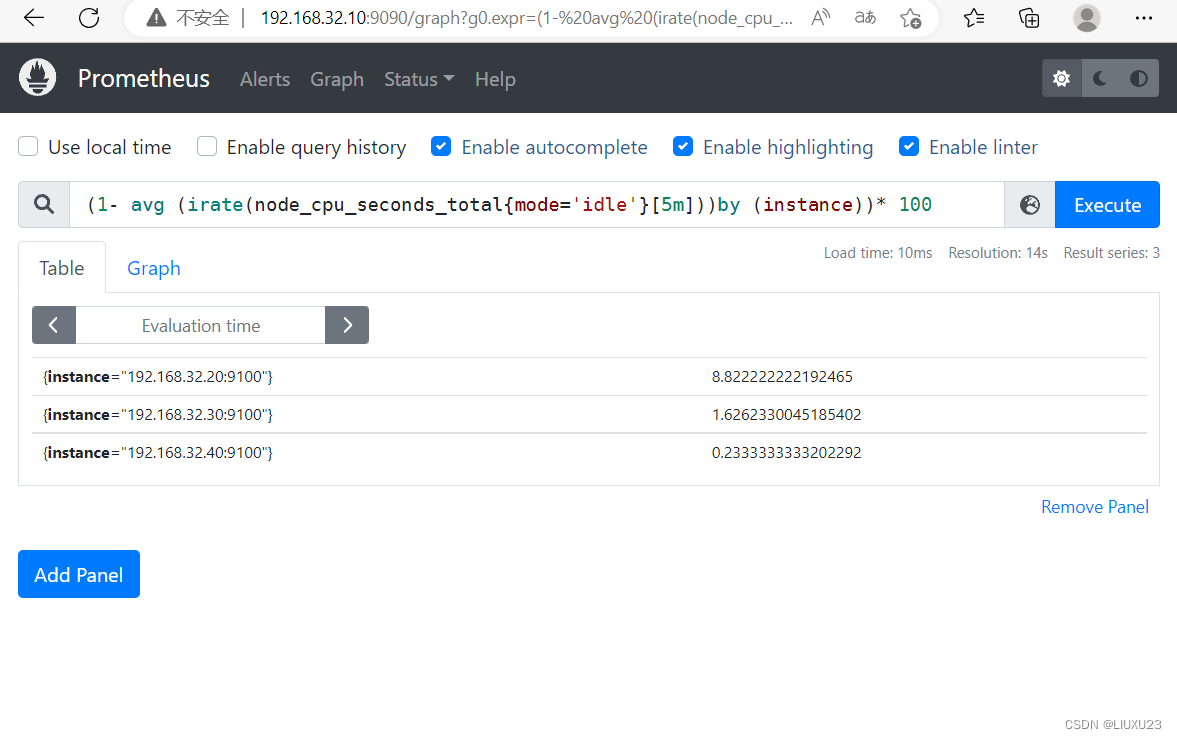
解析
avg:平均值
avg (irate(node_cpu_seconds_total{mode=‘idle’}[5m]):可以理解为CPU空闲量的百分比
by (instance):表示的是所有节点
(1- avg (irate(node_cpu_seconds_total{mode=‘idle’}[5m]))by (instance))* 100:CPU 5分钟内的平均使用率
其他常用的指标:
1、查询1分钟平均负载超过主机CPU数量两倍的时间序列
node_load1 > on (instance) 2 * count (node_cpu_seconds_total{mode=‘idle’}) by(instance)
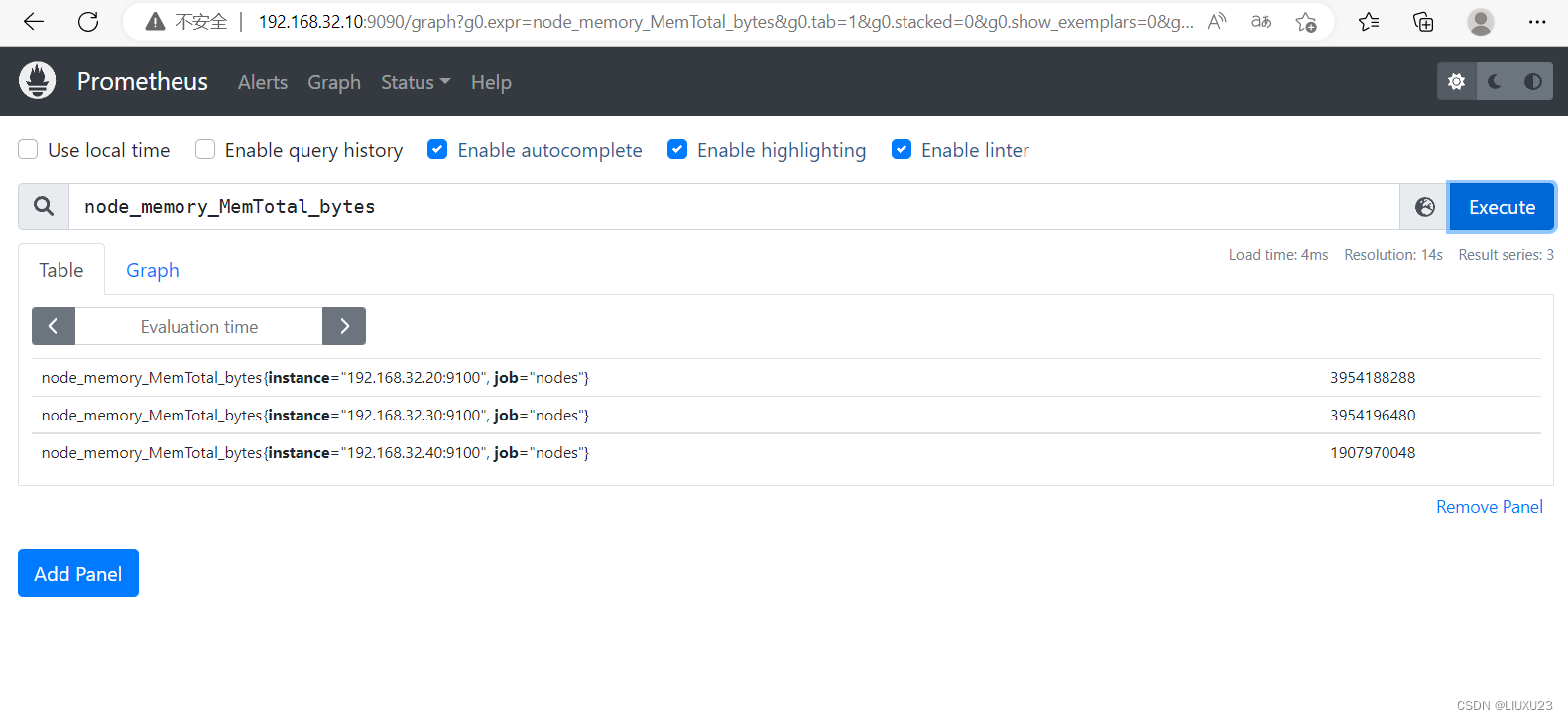
2、内存使用率
node_memory_MemTotal_bytes
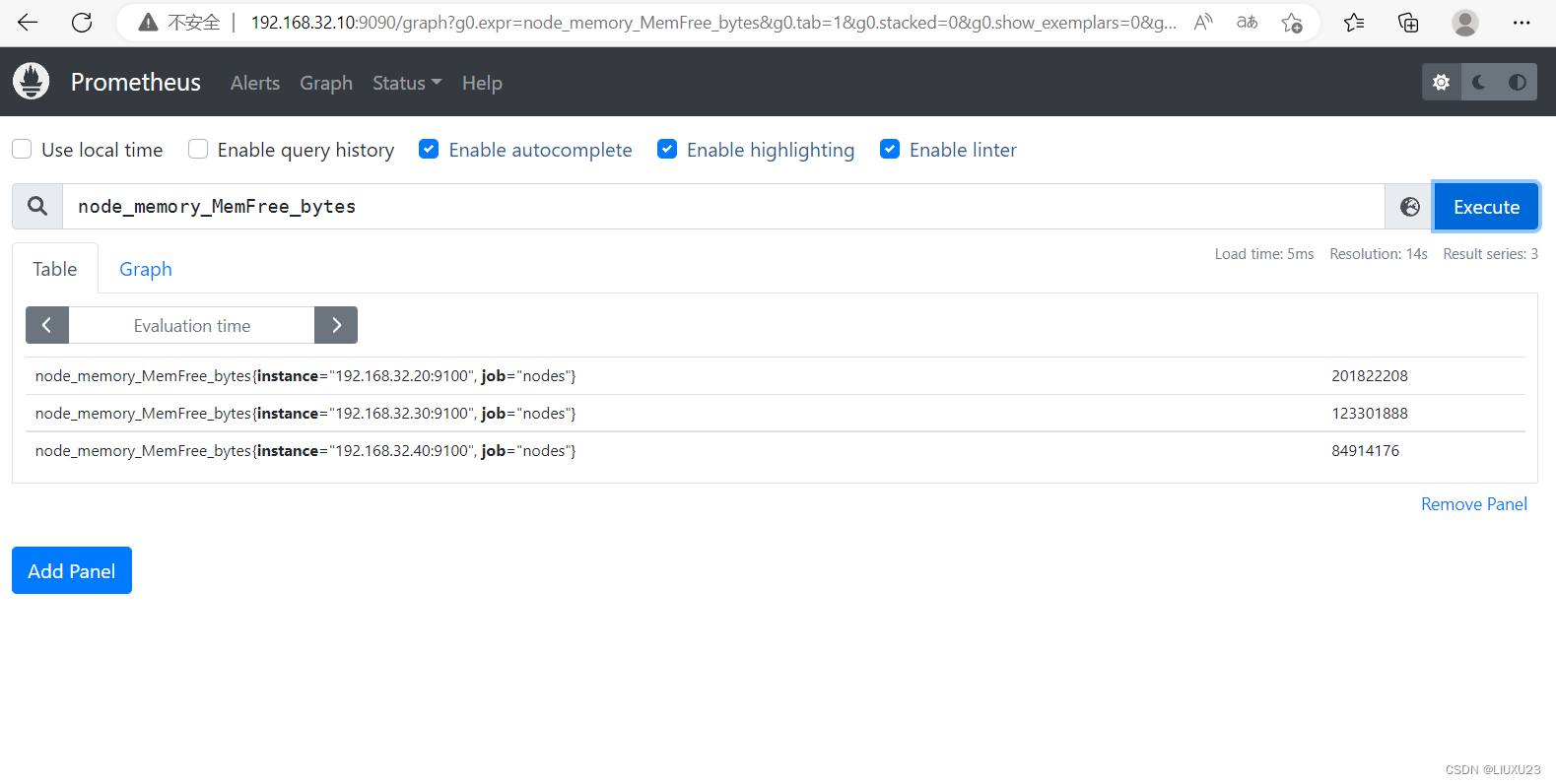
node_memory_MemFree_bytes
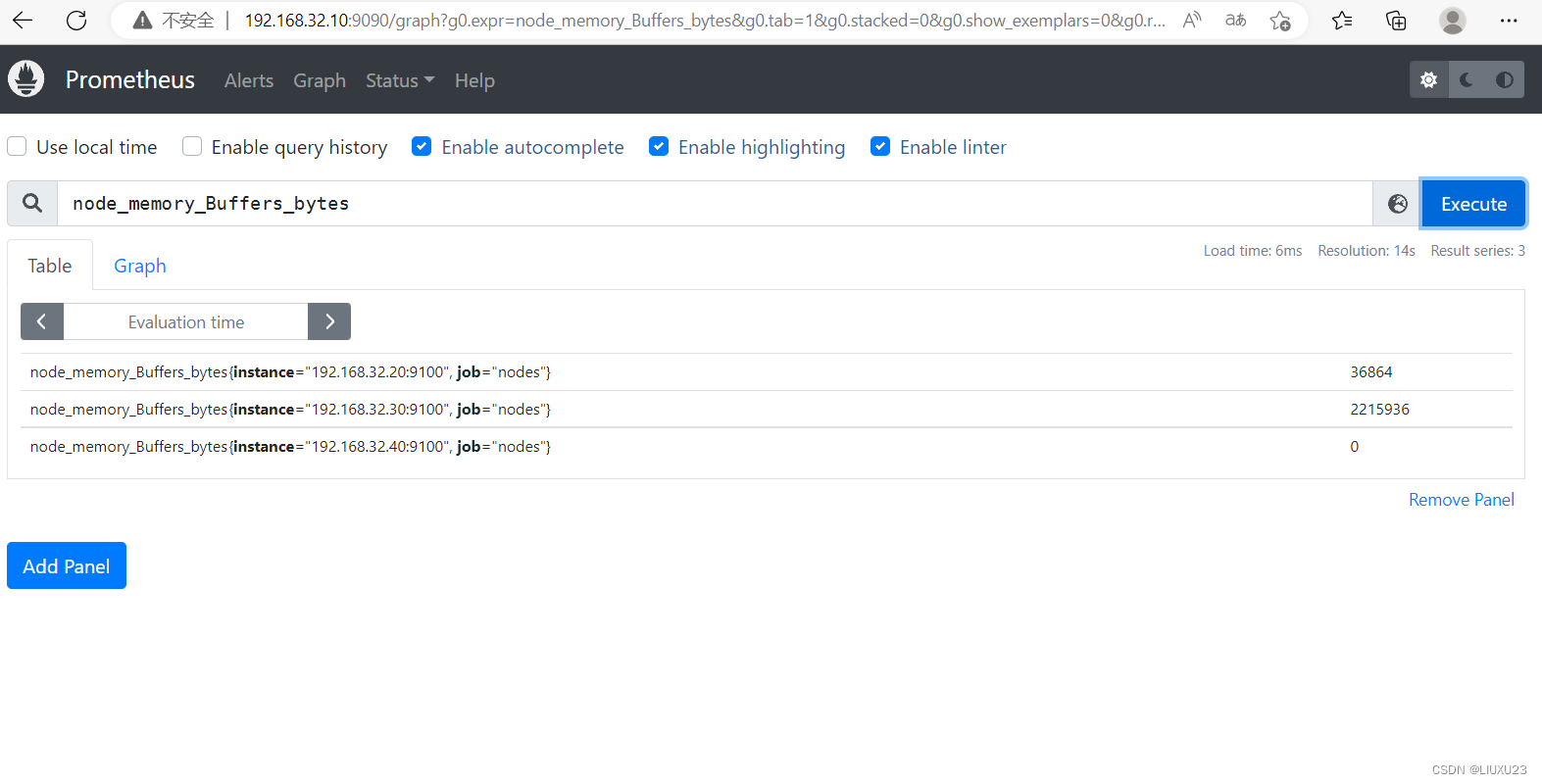
node_memory_Buffers_bytes
node_memory_Cached_bytes
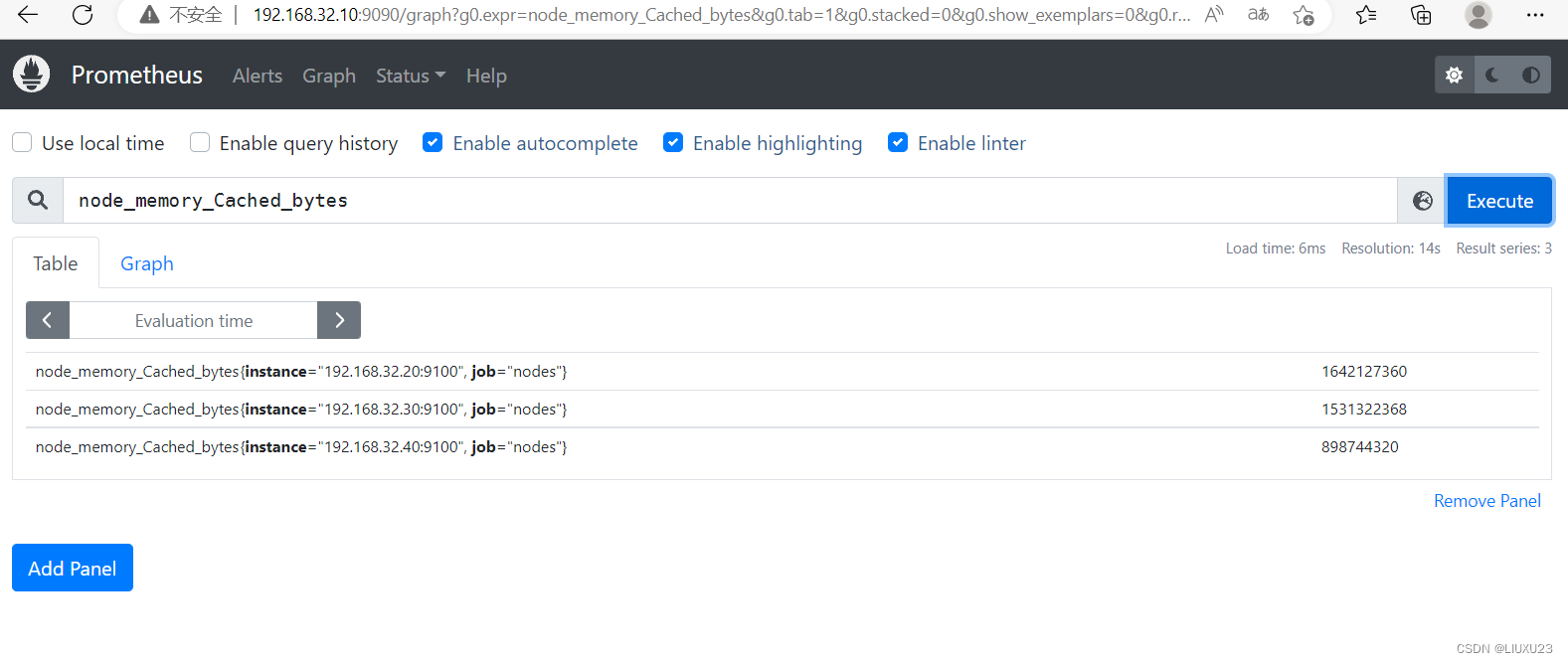
计算使用率:
可用空间:以上后三个指标之和
已用空间:总空间减去可用空间
使用率:已用空间除以总空间