赶时间的同学们看这里:提升精确率是为了不错报、提升召回率是为了不漏报
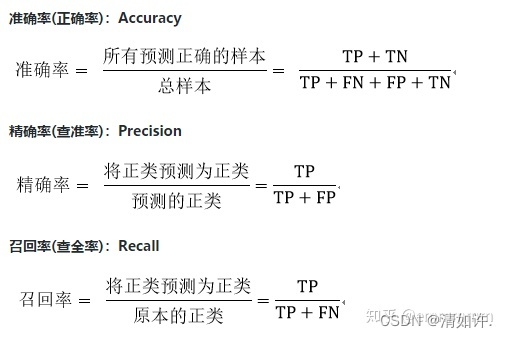
网络上很多地方分不清准确率和精确率,在这里先正确区分一下精确率和准确率,以及他们的别称
切入正题
很多人分不清召回率和精确率的区别,即使记住了公式,过段时间还是会忘掉,这里我会完全讲清楚这几个率的区别
准确率很好理解,被正确预测出来的数量 / 所有的样本,这里不在赘述,主要讲解精确率和召回率
精确率和召回率就是分母不一样,下面以预测地震为例
请听题:你的老板让你做一个地震预测模型(以天为单位记某一天地震为正样本,不地震为负样本),你需要预测接下来100天的地震情况。
假设你是拉普拉斯妖,你知道第50天和51天会地震,其余的1-49和51-100天不会地震。
现在假设你的模型已经做好,但是不能精确率和召回率,二者不可得兼,摆在你面前的是提升其中的一个率,你应该怎么办?
通俗解释一下
咋一看他们只有分母不一样,但是为啥不一样呢?
精确率: 分母是预测到的正类,精确率的提出是让模型的现有预测结果尽可能不出错(宁愿漏检,也不能让现有的预测有错)
以地震模型为例说就是宁愿地震了没报,也不能误报地震,比如说为了不错报,只预测了第50天可能发生地震,此时的
1.精确率:1/1=100%
2.召回率:1/2=50%
虽然有一次地震没预测到,但是我们做出的预测都是对的。
召回率: 分母是原本的正类,召回率的提出是让模型预测到所有想被预测到的样本(就算多预测一些错的,也能接受)
以地震模型为例说这100次地震,比如说为了不漏报,预测了第30天、50天、51天、70天、85天地震,此时的
1.精确率:2/5=40%
2.召回率:2/2=100%
虽然预测错了3次,但是我们把会造成灾难的2次地震全预测到了。
应该如何取舍呢?
假设地震发生没有预测到会造成百亿级别的损失,而地震没发生误报了地震会造成百万级别的损失
显然,这种情况下我们应该接受为了不能漏掉一次地震而多次误报带来的损失,即提升召回率
精确率和召回率有什么用?为什么需要它?通俗讲解(人话)
上面我们已经讲的很清楚了,这里以两种需求为例
- 预测地震 - 不能接受漏报
- 人脸识别支付(银行人脸支付) - 不能接受误检
人脸识别支付:主要提升精确率,更倾向于不能出现错误的预测。
应用场景:你刷脸支付时就算几次没检测到你的脸,最多会让你愤怒,对银行损失不大,但是如果把你的脸检测成别人的脸,就会出现金融风险,让别人替你买单,对银行损失很大。所以宁愿让你付不了钱,也不会让别人帮你付钱。
预测地震:主要提升召回率,更倾向于宁愿多预测一些错的也不能漏检。
应用场景:地震预测时宁愿多预测一些错的,也不想漏掉一次地震,预测错误最多会让大家多跑几趟,造成少量损失。只要预测对一次,就会挽回百亿级别的损失,之前所有的损失都值了。
不同的应用场景,需要的评价标准不一样,所以才会有这些率。
转载:通俗解释机器学习中的召回率、精确率、准确率 - HashCAt的文章 - 知乎
https://zhuanlan.zhihu.com/p/93586831