DataFrame的增删改操作
DataFrame的增加操作
为DataFrame增加一列相同的内容
df[‘新列名’]=‘数据’
代码实现
import pandas as pd
index1 = ["stu1", "stu2", "stu3", "stu4"]
columns1 = ["姓名", "年龄", "性别", "职业"]
data1 = [['李A', 18, '男', '数据分析'],
['王B', 19, '男', '机器学习'],
['赵C', 20, '女', "深度学习"],
['刘D', 19, '男', "搬砖"],
]
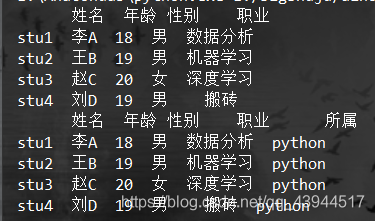
df = pd.DataFrame(index=index1, columns=columns1, data=data1)
print(df)
#为df增加一列;内容全部一致
df['所属']='python'
print(df)
结果展示
为DataFrame增加一列不同的内容
df[‘新列名’]=[‘数据’,‘数据’,…]
代码展示
import pandas as pd
index1 = ["stu1", "stu2", "stu3", "stu4"]
columns1 = ["姓名", "年龄", "性别", "职业"]
data1 = [['李A', 18, '男', '数据分析'],
['王B', 19, '男', '机器学习'],
['赵C', 20, '女', "深度学习"],
['刘D', 19, '男', "搬砖"],
]
df = pd.DataFrame(index=index1, columns=columns1, data=data1)
print(df)
#为df增加一列;内容全部一致
df['所属']='python'
print(df)
# 增加一列,内容不一致, 【需要和行的长度一致】
df["平时成绩"] = [90, 89, 88, 92]
df["考试成绩"] = [60, 40, 20, 0]
# 增加一列 根据已有内容进行增加
df["名字"] = df["姓名"].str[1:]
# 总成绩 根据已有内容进行增加
df["总成绩"] = df["平时成绩"]*0.3 + df["考试成绩"]*0.7
print(df)
结果展示

DataFrame的修改操作
先筛选出来 在进行修改
代码实现
import pandas as pd
index1 = ["stu1", "stu2", "stu3", "stu4"]
columns1 = ["姓名", "年龄", "性别", "职业"]
data1 = [['李A', 18, '男', '数据分析'],
['王B', 19, '男', '机器学习'],
['赵C', 20, '女', "深度学习"],
['刘D', 19, '男', "搬砖"],
]
df = pd.DataFrame(index=index1, columns=columns1, data=data1)
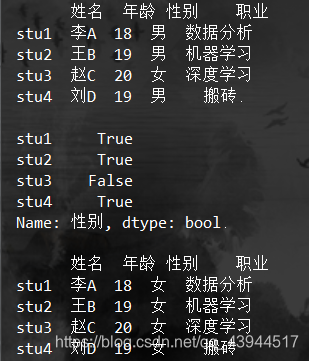
print(df,'\n')
#选出所有性别为男的同学 并将性别改为女
mask=df['性别']=='男'
print(mask,'\n')
df.loc[mask,'性别']='女'
print(df)
结果展示
DataFrame的删除操作
删除需要借助drop进行
df.drop()
删除一列
代码实现
import pandas as pd
index1 = ["stu1", "stu2", "stu3", "stu4"]
columns1 = ["姓名", "年龄", "性别", "职业"]
data1 = [['李A', 18, '男', '数据分析'],
['王B', 19, '男', '机器学习'],
['赵C', 20, '女', "深度学习"],
['刘D', 19, '男', "搬砖"],
]
df = pd.DataFrame(index=index1, columns=columns1, data=data1)
print(df,'\n')
df1=df.drop(columns='职业')
#df.drop(columns='职业',inplace=True)# inplace支持在原df上操作
print(df1)
结果展示

删除多列
代码实现
import pandas as pd
index1 = ["stu1", "stu2", "stu3", "stu4"]
columns1 = ["姓名", "年龄", "性别", "职业"]
data1 = [['李A', 18, '男', '数据分析'],
['王B', 19, '男', '机器学习'],
['赵C', 20, '女', "深度学习"],
['刘D', 19, '男', "搬砖"],
]
df = pd.DataFrame(index=index1, columns=columns1, data=data1)
print(df,'\n')
df.drop(columns=['职业','年龄'],inplace=True)
print(df)
结果展示

删除一行
代码实现
import pandas as pd
index1 = ["stu1", "stu2", "stu3", "stu4"]
columns1 = ["姓名", "年龄", "性别", "职业"]
data1 = [['李A', 18, '男', '数据分析'],
['王B', 19, '男', '机器学习'],
['赵C', 20, '女', "深度学习"],
['刘D', 19, '男', "搬砖"],
]
df = pd.DataFrame(index=index1, columns=columns1, data=data1)
print(df,'\n')
df.drop(index='stu3',inplace=True)
print(df)
结果展示

删除多行
代码实现
import pandas as pd
index1 = ["stu1", "stu2", "stu3", "stu4"]
columns1 = ["姓名", "年龄", "性别", "职业"]
data1 = [['李A', 18, '男', '数据分析'],
['王B', 19, '男', '机器学习'],
['赵C', 20, '女', "深度学习"],
['刘D', 19, '男', "搬砖"],
]
df = pd.DataFrame(index=index1, columns=columns1, data=data1)
print(df,'\n')
df.drop(index=['stu3','stu1'],inplace=True)
print(df)
结果展示

DataFrame的查看操作
查看操作
代码实现
import pandas as pd
index1 = ["stu1", "stu2", "stu3", "stu4"]
columns1 = ["姓名", "年龄", "性别", "职业"]
data1 = [['李A', 18, '男', '数据分析'],
['王B', 19, '男', '机器学习'],
['赵C', 20, '女', "深度学习"],
['刘D', 19, '男', "搬砖"],
]
df = pd.DataFrame(index=index1, columns=columns1, data=data1)
df["平时成绩"] = [90, 50, 70, 32]
print(df,'\n')
#查看平时成绩及格的人
mask=df['平时成绩']>=60
df1=df.loc[mask,:]
print(df1)
代码实现
