文章目录
一、多个工作表合并(pandas)
在实际生活工作中,我们经常会遇到多个excel表格合并问题;如一个工作簿中,通常会有多个相似的表。
1. 读取sheet表
import pandas
# 默认读取第一个表
detail = pandas.read_excel('meal_order_detail.xlsx')
print(detail.shape) # (2779, 19) ## 默认读sheet1
# 读取第一和第二个表
detail = pandas.read_excel('meal_order_detail.xlsx',sheetname=[0,1])
print(type(detail))
# 读取所有的表
detail = pandas.read_excel('meal_order_detail.xlsx',sheetname=None)
print(type(detail))
## 想读取另外的sheet表,使用sheetname参数
detail_sheet2 = pandas.read_excel('meal_order_detail.xlsx',sheetname=1)
print("sheet_2:",detail_sheet2.shape) # sheet_2: (3647, 19)
# print(detail_sheet2.describe())
2. read_excel函数源代码一些常用参数介绍
read_excel函数源代码:

| 参数 | 含义 |
|---|---|
| sheetname | 默认是sheetname为0,返回多表使用sheetname=[0,1],若sheetname=None是返回所有的表 。注意:int/string返回的是dataframe,而none和list返回的是dict of dataframe(<class ‘collections.OrderedDict’>)。 |
| header | 指定作为列名的行,默认0,即取第一行,数据为列名行以下的数据;若数据不含列名,则设定 header = None; |
| skiprows | 省略指定行数的数据,默认为None ;如 skiprows= 1#略去1行的数据,自上而下的开始略去数据的行 |
| skip_footer | 省略从尾部数的行数据 ,默认为0;如skip_footer= 1 从尾部开始略去1行的数据 |
| index_col | 指定列为索引列;如index_col=1 |
| names | 指定列的名字,传入一个list数据;如names=[‘a’,‘b’,‘c’]) |
3. 多个sheet合并成一个表
用到的模块:xlrd
xlrd模块介绍:
- xlrd是读取excel表格数据;
- 支持 xlsx和xls 格式的excel表格;
- 第三方模块安装方式:pip install xlrd;
- 模块导入方式: import xlrd
对于excel表格,我们可以利用单独的库来进行操作:xlrd
(1)xlrd的一些方法
① 打开workbook获取Book对象(open_workbook)
打开excel文件xlrd.open_workbook(filename[, logfile, file_contents, ...])
filename:需操作的文件名(包括文件路径和文件名称);
- 若filename不存在,则报错FileNotFoundError;
- 若filename存在,则返回值为xlrd.book.Book对象
""" 打开excel表格"""
workbook = xlrd.open_workbook("测试.xlsx")
print(workbook) # 结果:<xlrd.book.Book object at 0x000000000291B128>
② 获取Book对象中所有sheet名称
获取所有sheet的名称,以列表方式显示BookObject.sheet_names()
""" 获取所有sheet名称"""
sheet_names = workbook.sheet_names()
print(sheet_names) # 结果:['Sheet1', 'Sheet2']
③ 获取Book对象中所有Sheet对象
-
获取所有sheet的对象,以列表形式显示
BookObject.sheets()""" 获取所有或某个sheet对象""" # 获取所有的sheet对象 sheets_object = workbook.sheets() print(sheets_object) # 结果:[<xlrd.sheet.Sheet object at 0x0000000002956710>, <xlrd.sheet.Sheet object at 0x0000000002956AC8>] -
通过sheet索引获取所需sheet对象
BookObject.sheet_by_index(sheetx)# 通过index获取第一个sheet对象 sheet1_object = workbook.sheet_by_index(0) print(sheet1_object) # 结果:<xlrd.sheet.Sheet object at 0x0000000002956710>sheetx为索引值,索引从0开始计算;
若sheetx超出索引范围,则报错IndexError;
若sheetx在索引范围内,则返回值为xlrd.sheet.Sheet对象 -
通过sheet名称获取所需sheet对象
BookObject.sheet_by_name(sheet_name)# 通过name获取第一个sheet对象 sheet1_object = workbook.sheet_by_name(sheet_name="表1") print(sheet1_object) # 结果:<xlrd.sheet.Sheet object at 0x0000000002956710>sheet_name为sheet名称;
若sheet_name不存在,则报错xlrd.biffh.XLRDError;
若sheet_name存在,则返回值为xlrd.sheet.Sheet对象
④ 判断Book对象中某个sheet是否导入
通过sheet名称或索引判断该sheet是否导入成功BookObject.sheet_loaded(sheet_name_or_index)
""" 判断某个sheet是否已导入"""
# 通过index判断sheet1是否导入
sheet1_is_load = workbook.sheet_loaded(sheet_name_or_index=0)
print(sheet1_is_load) # 结果:True
# 通过sheet名称判断sheet1是否导入
sheet1_is_load = workbook.sheet_loaded(sheet_name_or_index="表1")
print(sheet1_is_load) # 结果:True
返回值为bool类型,若返回值为True表示已导入;若返回值为False表示未导入
⑤ 对Sheet对象中的行操作
“”" 对sheet对象中的行执行操作:如有效行数、某行从n1到n2列的数据、某行的单元和类型、某行的长度… “”"
-
获取某sheet中的有效行数
SheetObject.nrows# 获取sheet1中的有效行数 nrows = sheet1_object.nrows print(nrows) # 结果:5 -
获取sheet中第rowx+1行从start_colx列到end_colx列的数据,返回值为列表。
SheetObject.row_values(rowx[, start_colx=0, end_colx=None])# 获取sheet1中第3行的数据 all_row_values = sheet1_object.row_values(rowx=2) print(all_row_values) # 结果:[3.0, 'b', 1, ''] row_values = sheet1_object.row_values(rowx=2, start_colx=1, end_colx=3) print(row_values) # 结果:['b', 1]若rowx在索引范围内,以列表形式返回数据;
若rowx不在索引范围内,则报错IndexError -
获取sheet中第rowx+1行单元,
SheetObject.row(rowx)返回值为列表;列表每个值内容为: 单元类型:单元数据# 获取sheet1中第3行的单元对象 row_object = sheet1_object.row(rowx=2) print(row_object) # 结果:[number:3.0, text:'b', bool:1, empty:''] -
以切片方式获取sheet中第rowx+1行从start_colx列到end_colx列的单元,返回值为列表;
SheetObject.row_slice(rowx[, start_colx=0, end_colx=None])列表每个值内容为: 单元类型:单元数据# 获取sheet1中第3行的单元 row_slice = sheet1_object.row_slice(rowx=2) print(row_slice) # 结果:[number:3.0, text:'b', bool:1, empty:''] -
获取sheet中第rowx+1行从start_colx列到end_colx列的单元类型,返回值为array.array类型。
SheetObject.row_types(rowx[, start_colx=0, end_colx=None])# 获取sheet1中第3行的单元类型 row_types = sheet1_object.row_types(rowx=2) print(row_types) # 结果:array('B', [2, 1, 4, 0])单元类型ctype:empty为0,string为1,number为2,date为3,boolean为4, error为5(左边为类型,右边为类型对应的值);
-
获取sheet中第rowx+1行的长度
SheetObject.row_len(rowx)# 获取sheet1中第3行的长度 row_len = sheet1_object.row_len(rowx=2) print(row_len) # 结果:4rowx:行标,行数从0开始计算(0表示第一行), 必填参数;
start_colx:起始列,表示从start_colx列开始取值,包括第start_colx的值;
end_colx:结束列,表示到end_colx列结束取值,不包括第end_colx的值;
start_colx默认为0,end_colx默认为None:表示取整行相关数据; -
获取某一sheet所有行的生成器
SheetObject.get_rows()# 获取sheet1所有行的生成器 rows_generator = sheet1_object.get_rows() print(rows_generator) # 结果:<generator object Sheet.get_rows.<locals>.<genexpr> at 0x00000000028D8BA0>
⑥ 对Sheet对象中的列操作
-
获取某sheet中的有效列数
SheetObject.ncols# 获取sheet1中的有效列数 ncols = sheet1_object.ncols print(ncols) # 结果:4 -
获取sheet中第colx+1列从start_rowx行到end_rowx行的数据,返回值为列表。
SheetObject.col_values(self, colx[, start_rowx=0, end_rowx=None])# 获取sheet1中第colx+1列的数据 col_values = sheet1_object.col_values(colx=1) print(col_values) # 结果:['测试', 'a', 'b', 'c', 'd'] col_values1 = sheet1_object.col_values(1, 1, 3) print(col_values1) # 结果:['a', 'b'] -
以切片方式获取sheet中第colx+1列从start_rowx行到end_rowx行的数据,返回值为列表。列表每个值内容为: 单元类型:单元数据
SheetObject.col_slice(colx[, start_rowx=0, end_rowx=None])# 获取sheet1中第2列的单元 col_slice = sheet1_object.col_slice(colx=1) print(col_slice) # 结果:[text:'测试', text:'a', text:'b', text:'c', text:'d'] -
获取sheet中第colx+1列从start_rowx行到end_rowx行的单元类型,返回值为列表;
SheetObject.col_types(colx[, start_rowx=0, end_rowx=None])
# 获取sheet1中第2列的单元类型
col_types = sheet1_object.col_types(colx=1)
print(col_types) # 结果:[1, 1, 1, 1, 1]
⑦ 对Sheet对象的单元格执行操作
-
获取sheet对象中第rowx+1行,第colx+1列的单元对象,返回值为’xlrd.sheet.Cell’类型,返回值的格式为“单元类型:单元值”。
ShellObeject.cell(rowx, colx)# 获取sheet1中第rowx+1行,第colx+1列的单元对象 cell_info = sheet1_object.cell(rowx=1, colx=2) print(cell_info) # 结果: text:'m' print(type(cell_info)) # 结果:<class 'xlrd.sheet.Cell'> -
获取sheet对象中第rowx+1行,第colx+1列的单元数据,返回值为当前值的类型(如float、int、string…);
ShellObject.cell_value(rowx, colx)# 获取sheet1中第rowx+1行,第colx+1列的单元值 cell_value = sheet1_object.cell_value(rowx=1, colx=2) print(cell_value) # 结果: m -
获取sheet对象中第rowx+1行,第colx+1列的单元数据类型值;
ShellObject.cell_type(rowx, colx)# 获取sheet1中第rowx+1行,第colx+1列的单元类型值 cell_type = sheet1_object.cell_type(rowx=1, colx=2) print(cell_type) # 结果:1单元类型ctype:empty为0,string为1,number为2,date为3,boolean为4, error为5;
(2)合并sheet表
使用模块:xlrd
步骤:
- 第一步:拿到工作簿
wb = xlrd.open_workbook(file_path) - 第二步:获取工作簿中的工作表
sheets = wb.sheet_names() - 第三步:用for循环,循环遍历获取到的sheets列表长度的索引,将循环出来的sheet表添加到 pandas.DataFrame()中
- 第四步:创建一个新的工作簿
wb=pandas.ExcelWriter('detail.xlsx') - 第五步:将之前获取到的所有sheet表写入创建的工作簿中
total.to_excel(wb,'Sheet1') - 第六步:保存
wb.save()
import pandas
## 对于excel表格,我们可以利用单独的库来进行操作:xlrd
import xlrd
file_path = 'meal_order_detail.xlsx'
## 首先拿到工作簿
wb = xlrd.open_workbook(file_path)
## 获取工作簿中的工作表
sheets = wb.sheet_names()
# print(sheets) # ['meal_order_detail1', 'meal_order_detail2', 'meal_order_detail3']
## 打开表文件
# 总表
total = pandas.DataFrame()
for i in range(len(sheets)):
df = pandas.read_excel(file_path,sheetname=i,skiprows=0,encoding='utf8')
# print(df.shape)
total = total.append(df)
print(total.shape)
## 保存成一张表
wb = pandas.ExcelWriter('detail.xlsx')
## 将表放进去
total.to_excel(wb,'Sheet1') ## 第一个参数工作簿,第二个是表名
## 保存
wb.save()
合并后:

二、iloc函数的用法
对于loc函数,loc[行索引/名称或条件, 列索引/名称]
iloc 和 loc 区别是 iloc 接收的必须是行索引和列索引的位置。
iloc 方法的使用方法如下。
DataFrame.iloc[行索引位置, 列索引位置]
1. loc和iloc的区别
- iloc[,]括号里面的两个参数只能是行索引和列索引
- 使用 loc 方法和 iloc 实现多列切片,其原理的通俗解释就是将多列的列名或者位置作为 一个列表或者数据传入。
- 使用 loc,iloc 方法可以取出 DataFrame 中的任意数据。
- 在 loc 使用的时候内部传入的行索引名称如果为一个区间,则前后均为闭区间;
- iloc 方 法使用时内部传入的行索引位置或列索引位置为区间时,则为前闭后开区间。
- loc 更加灵活多变,代码的可读性更高,iloc 的代码简洁,但可读性不高。(大多数情况建议使用loc)
- loc 内部还可以传入表达式,结果会返回满足表达式的所有值
detail.loc[detail['order_id']==458, ['order_id','dishes_name']])。而使用iloc则是detail.iloc[(detail['order_id']=='458').values,[1,5]])
2. iloc的使用
对于上面提到的传入表达式的介绍
对于loc有:
import pandas
detail = pandas.read_excel('detail.xlsx')
## 读取order_id == 458 的 dishname和order_id这两项
result = detail.loc[detail['order_id']== 458,['dishes_name','order_id' ]]
print(result[:5])

而对于iloc获取相同的数据
-
第一种办法:连续获取
result2 = detail.iloc[145:159,[1,5]] ## 前闭后开,真实的是145:158之间 print(result2)
注意:这里面iloc行索引的区间是前闭后开
缺点:不能跨行获取 -
第二种办法:根据多个行索引来获取
iloc[行索引位置,列索引位置]result3 = detail.iloc[[0,2,3,4],[1,5]] print(result3)
缺点:这是对数量较少的数据,而对于数量很大的数据操作复杂 -
第三种办法:利用条件进行获取指定行的数据 和loc类似
在这里先介绍一下(detail['order_id']== 458).values;返回的是False和True,找到则为True,找不到则为False;如果是False对应的行,则不显示;如果是True对应的行则显示print((detail['order_id']== 458).values) # False不显示,True显示
对于求离散数据,该方法和loc的条件查询一样result4 = detail.iloc[(detail['order_id']== 458).values,[1,5]] print(result4)
三、pandas时间类型问题及时间差问题
1. 将数据类型转换为符合要求的时间日期型(Timestamp)pandas.to_datetime()方法
-
问题:
对于读取出来的数据DataFrame对象,我们想对其时间类型的数据进行操作是很麻烦的一件事;因为存在表中的数据类型是字符串import pandas order = pandas.read_table('meal_order_info.csv',sep=',',encoding='gbk') ## 获取时间use_start_time列 start_time = order['use_start_time'] ## --------取出来的时间类型是字符串----- print(type(start_time)) ## <class 'pandas.core.series.Series'> print(type(start_time[0])) ## <class 'str'> -
解决思路:
为了方便对日期时间进行操作计算,我们需要将原来是字符串类型的日期时间数据转换成日期时间类型的数据 -
解决办法:
在pandas中有一个函数方法,可以将数据类型转换成时间戳Timestamp的时间日期型pandas.to_datetime()result = pandas.to_datetime(start_time) print(type(result[0])) #print(type(result)) # <class 'pandas.core.series.Series'> #print(type(result[0])) # <class 'pandas._libs.tslib.Timestamp'>
将不符合类型的str变成日期时间类型(这一列)---------------》将字符串类型的时间转换成时间日期型## 将转换后的结果赋值给use_start_time列 order['use_start_time'] = result -
转换类型的好处:
可以直接调用其相关属性或方法来获得我们想要的数据
(1)属性1:yearlock_time = order['lock_time'] # print(lock_time[0]) ## str result = pandas.to_datetime(lock_time) order['lock_time'] = result # # ## 转换类型是为了计算 for i in order['lock_time']: print(i.year)
列表推导式方法:years = [i.year for i in order['lock_time'] ] print(years)
(2)属性2:monthmonth = [i.month for i in order['lock_time'] ] print(month) ## 一年中的第几个月
(3)属性3:weekweek = [i.week for i in order['lock_time'] ] print(week) ## 一年中的第几周(4)函数方法:weekday()
weekday = [i.weekday() for i in order['lock_time'] ] print(weekday[:5]) ## [0, 0, 0, 0, 0] # 2016年8月1号是星期一;以星期一为0,星期日为6(5)属性5:weekday_name
weekday_name = [i.weekday_name for i in order['lock_time'] ] print(weekday_name[:5]) # ['Monday', 'Monday', 'Monday', 'Monday', 'Monday']
2. 时间差问题
(1)聚合函数min()和max()
# # min() max()
a = order['lock_time'].min()
print("八月份最早的lock_time",a)
b = order['lock_time'].max()
print("八月份最晚的lock_time",b)

delta = b-a
print('八月份订单持续时间:',delta)

(2)由聚合函数引出的时间差问题
统计每个订单的点餐所用时间
result = order['lock_time'] - order['use_start_time']
print('每个订单的点餐所用时间:',result[:5])
print('订单的点餐最长用时::',result.max()) # 订单的点餐最长用时:: 16 days 00:08:00
print('订单的点餐最少用时::',result.min()) # 订单的点餐最少用时:: -1 days +00:05:00

发现问题:订餐时间为负和16天
原因:数据不符合规范
分析:通过上面可以得出:要做 数据预处理,数据清洗
(3)数据清洗
数据清洗:将不合规的数据去掉,留下标准的数据
① lock_time如果早于use_start_time,这种数据是不合规的
result = order['lock_time'] - order['use_start_time']
# # print(type(result[0])) # <class 'pandas._libs.tslib.Timedelta'>
print(pandas.to_timedelta(0)) ## 0 days 00:00:00
# ## 小于上面的为负数,可以用负数判断是否合规
invalid1 = result.index[(result<pandas.to_timedelta(0))]
print(invalid1)

② lock_time与use_start_time的跨度如果超过1天都是不合规的
通过.dt.days获取天数大于0的;.dt相当于datetime;result获取到的是订单时间的时间戳,获取里面的days天数
result = order['lock_time'] - order['use_start_time']
print(result.dt) # <pandas.core.indexes.accessors.TimedeltaProperties object at 0x0000000005AD7C88>
print(result.dt.days) # 942 0.0

通过天数判断,天数大于0的都是不符合规范的
invalid2 = result.index[(result.dt.days>0)]
print(invalid2) # Int64Index([82, 303, 513, 518, 526, 527], dtype='int64')

③ 通过找到不符合规则的来进行数据清洗
在表格中将不合规的行删除
-
分别删除
print("删除前---order.shape:",order.shape) # 删除前---order.shape: (945, 21) order.drop(labels=invalid1,axis=0,inplace=True) # inplace是否对原数据生效;False不生效 print("invalid1删除后---order.shape:",order.shape) # invalid1删除后---order.shape:(922, 21) # # order.drop(labels=invalid2,axis=0,inplace=True) print("invalid2删除后---order.shape:",order.shape) # invalid2删除后---order.shape: (916, 21)
-
统一删除
invalid3 = result.index[(result.dt.days>0)|(result<pandas.to_timedelta(0))] order.drop(labels=invalid3,axis=0,inplace=True) print("统一删除后---order.shape:",order.shape) # 统一删除后---order.shape: (916, 21)
处理后的数据应该保存
使用清洗后的数据进行数据分析
deta_time = order['lock_time'] - order['use_start_time']
print('每个订单点餐所用时间:',deta_time[:5])
print('每个订单点餐最多用时时间:\n',deta_time.max())
print('每个订单点餐最少用时时间:\n',deta_time.min())
## 平均点餐时间:
print('客户平均点餐时间:',deta_time.mean())

四、DataFrame的增删改查
1.增
原有的表上进行修改,要么增加一列要么增加一行
(1)增加一列
直接用赋值新列操作
eg:将时间差当做表的一列数据
order['lock_time'] = pandas.to_datetime(order['lock_time'])
order['use_start_time'] = pandas.to_datetime(order['use_start_time'])
# 时间差
delta_time = order['lock_time']-order['use_start_time']
# # 增加一列
print('原始表中列有:',order.columns)
order['delta_time'] = delta_time
print('增加一列后,表中列有:',order.columns)

(2)增加一行
使用loc方法将一列加到最后
注意:使用iloc会超出索引
values = []
print("未增加一行之前,order的shape:",order.shape) # 未增加一行之前,order的shape: (945, 21)
for i in range(21):
values.append(i)
order.loc[order.shape[0],:]=values
print("增加一行后,order的shape:",order.shape) # 增加一行后,order的shape: (946, 21)
print(order.tail(1))

2. 删
删除格式
import pandas
order = pandas.read_table('meal_order_info.csv',sep=',',encoding='gbk')
# 删除格式:DataFrame对象.drop()---------->表对象.drop()------>order.drop()
# drop(labels, axis=0, level=None, inplace=False, errors='raise')
使用的是drop函数
(1)删除一列
print("原始表结构为:",order.shape) # 原始表结构为: (945, 21)
order.drop(labels='mode',axis=1,inplace=True) # labels后面接列名,可以是列表写多个
print("删除一列后表结构为:",order.shape) # 删除后表结构为: (945, 20)

注意:inplace有两个值:True和False,默认为False,如果是True就会执行操作;即是否对原数据生效;False不生效
(2)删除多列
order.drop(labels=['check_closed','cashier_id'],axis=1,inplace=True)
print("删除多列后表结构为:",order.shape) # 删除多列后表结构为: (945, 18)

(3)删除含有空的列或行
-
删除所有含有空的列,只要那列有空就删除
使用的是dropna
dropna内部参数def dropna(self, axis=0, how='any', thresh=None, subset=None,inplace=False) # how默认any,而为all时是全有NA时才删order.dropna(axis=1,inplace=True) print("删除所有的空后表结构为:",order.shape) print(order.columns)
-
删除整行或者整列都是空的
order.dropna(axis=1,how='all',inplace=True)
print("删除整行或整列都为空后表结构为:",order.shape) # 删除所有的NA后表结构为: (945, 13)
print(order.columns)

参数:
# 参数:
# axis:0表示按行删除,1表示按列删除
# how:any 表示只有行或列中存在任意一个空值,就把行或列整体都删除
# all 表示行或列所有值都是空值时才删除
# inplace:删除的结果将作用于原始表对象中
(4)去重drop_duplicates((处理行的数据))
order.drop_duplicates(inplace=True)
print("对表的数据进行去重:",order.shape) # 对表的数据进行去重: (945, 21)

说明没有重复的行
数据清洗:
- 取出不符合规则的,如之前的点餐时间为负或者超过一天
- 去除空的列(无用的列)
- 去除重复的行
3. 改
对于修改就是用查到的列重新赋值;具体看查有哪些方法直接赋值就好
(1)针对某一个单元格
import pandas
order = pandas.read_table('meal_order_info.csv',sep=',',encoding='gbk')
## 查看是否获取到元素
cell_0_0 = order.iloc[0,0]
# print(cell_0_0) # 417
cell_0_21 = order.iloc[0,20]
print("修改前:",cell_0_21) # 修改前:苗宇怡
## 将cell_0_21 苗宇怡 人名改成老苗
order.iloc[0,20] = '老苗'
print("修改后结果:",order.iloc[0,20]) # 修改后结果: 老苗

(2)批量修改
# 将982的emp_id修改为98200
print("修改前的emp_id:",order.loc[order['emp_id']==982,'emp_id'])
order.loc[order['emp_id'] == 982,'emp_id'] = 98200
print("批量修改后",order.loc[order['emp_id'] == 98200,:])

4.查
- DataFrame[‘列名’]
- DataFrame.loc[行的索引或名称或条件,列的索引或名称] --------------------》区间前闭后闭
- DataFrame.iloc[行的索引,列的索引]---------》区间前闭后开
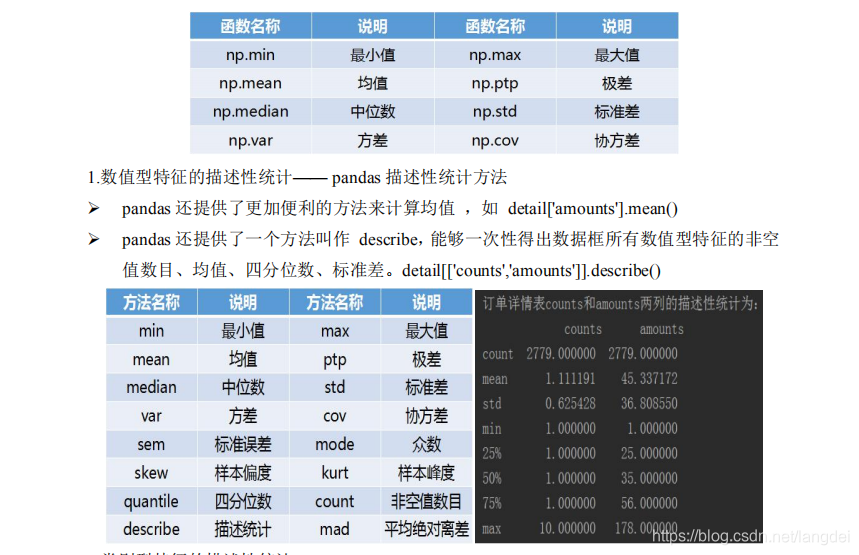
五、统计函数
import pandas
import numpy
order = pandas.read_table('meal_order_info.csv',sep=',',encoding='gbk')
print("本月营业额:",order['accounts_payable'].sum())
print("本月营业额:",numpy.sum(order['accounts_payable']))

注意:pandas是在numpy基础上完成的,所以numpy的sum方法也适用
