一、Pandas简介
Pandas是一个Python软件包,提供快速,灵 活和富有表现力的数据结构,旨在使“关系” 或“标记”数据的工作变得简单直观。 Pandas 纳入了大量库和一些标准的数据模 型,提供了高效地操作大型数据集所需的工具以及大量能使我们快速便捷地处理数据的函数和方法。
Pandas最初被作为金融数据分析工具而开发 出来,因此,pandas为时间序列分析提供了 很好的支持。 Pandas的名称来自于面板数 据(panel data)和python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。
Pandas时一个开源的,BSD许可的库,为Python编程语言提供了高性能,易于使用的数据结构和数据分析工具。
二、Pandas 开发环境准备
1、操作系统: windows 8.1
2、开发工具:
• Anaconda 5.1
• Jupyter Notebook
3、Python版本 • 3.6
4、第三方模块包
• numpy 1.13.3
• pandas 0.20.3
• matplotlib 2.1
三、Pandas 基本数据结构
Pandas两个主要数据结构: Series和 Dataframe。
Series是一种类似于一维数组的对象,它由一组数据(各种 Numpy数据类型)以及一 组与之相关的数据标签(即索引1)组成。仅由一组数据即可产生最简单的 Series。
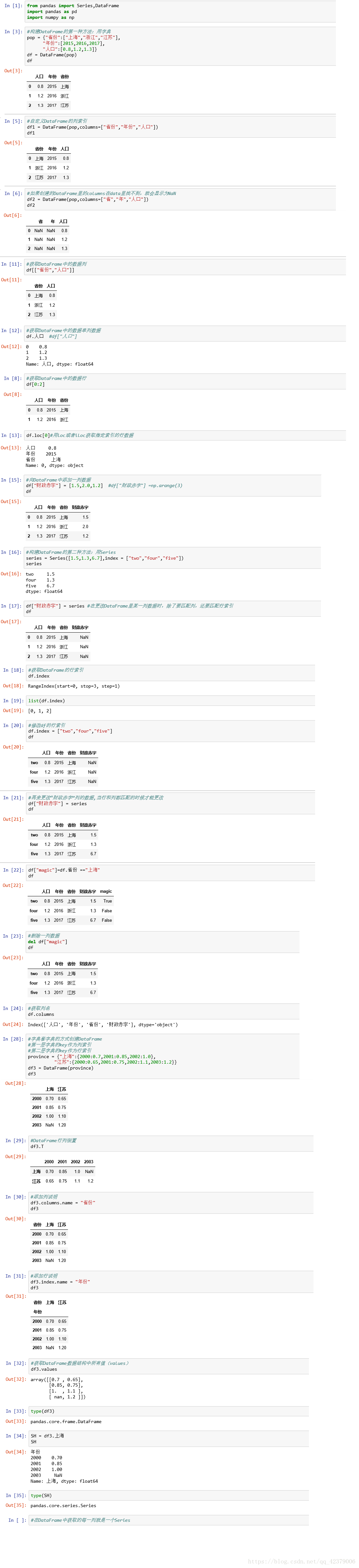
Series代码演示如下:

DataFrame 是一个 表格型 的数据结构,它含有一组 有序的列 ,每列可以 是 不同的值类型 (数值、字符串、布尔值等)。 Dataframe既有行索引也有 列索引,它可以被看做由 Series组成的字典(共用同一个索引)。跟其他类似的 数据结构相比(如R的dataframe), Data frame中 面向行 和 面向列 的操作 基本上是平衡的。其实, Dataframe中的数据是以一个或多个二维块存放的 (而不是列表、字典或别的一维数据结构)。
DataFrame代码演示如下: