import numpy as np
import torch
from torch import nn,optim
from torch.autograd import Variable
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
# 训练集
train_data = datasets.MNIST(root="./", # 存放位置
train = True, # 载入训练集
transform=transforms.ToTensor(), # 把数据变成tensor类型
download = True # 下载
)
# 测试集
test_data = datasets.MNIST(root="./",
train = False,
transform=transforms.ToTensor(),
download = True
)
# 批次大小
batch_size = 64
# 装载训练集
train_loader = DataLoader(dataset=train_data,batch_size=batch_size,shuffle=True)
# 装载测试集
test_loader = DataLoader(dataset=test_data,batch_size=batch_size,shuffle=True)
for i,data in enumerate(train_loader):
inputs,labels = data
print(inputs.shape)
print(labels.shape)
break

in_channel: 输入数据的通道数,例RGB图片通道数为3,灰色图通道数为1;
out_channel: 输出数据的通道数,这个根据模型调整;
kennel_size: 卷积核大小,可以是int,或tuple;kennel_size=2,意味着卷积大小2, kennel_size=(2,3),意味着卷积在第一维度大小为2,在第二维度大小为3;
stride:步长,默认为1,与kennel_size类似,stride=2,意味在所有维度步长为2, stride=(2,3),意味着在第一维度步长为2,意味着在第二维度步长为3;
padding: 零填充 如:3X3的卷积窗口就填充1圈零,5X5的卷积窗口就填充2圈零,7X7的卷积窗口就填充3圈零
# 定义网络结构
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()# 初始化
# nn.Conv2d(1,32,5,1,2): 通道数,输出,卷积窗口 步长,填充几圈0 激活函数relu 最大池化窗口2*2
self.conv1 = nn.Sequential(nn.Conv2d(1,32,5,1,2),nn.ReLU(),nn.MaxPool2d(2,2)) # 卷积层
self.conv2 = nn.Sequential(nn.Conv2d(32,64,5,1,2),nn.ReLU(),nn.MaxPool2d(2,2)) # 卷积层
self.fc1 = nn.Sequential(nn.Linear(64*7*7,500),nn.Dropout(p=0.5),nn.ReLU()) # 全连接层 全连接层 features_in其实就是输入的神经元个数,features_out就是输出神经元个数 64*7*7,1000 64个特征图 大小7*7 输出500个特征图
self.fc2 = nn.Sequential(nn.Linear(500,10),nn.Softmax(dim=1)) # 全连接层
def forward(self,x):
# torch.Size([64, 1, 28, 28]) # 卷积中需要传入4维 批次大小 图像通道数 图片大小
x = self.conv1(x)
x = self.conv2(x)
# torch.Size([64, 1, 28, 28]) -> (64,784)
x = x.view(x.size()[0],-1) # 4维变2维 (在全连接层做计算只能2维)
x = self.fc1(x)
x = self.fc2(x)
return x
# 定义模型
model = Net()
# 定义代价函数
mse_loss = nn.CrossEntropyLoss()# 交叉熵
# 定义优化器
optimizer = optim.Adam(model.parameters(),lr=0.5)# 随机梯度下降
# 定义模型训练和测试的方法
def train():
# 模型的训练状态
model.train()
for i,data in enumerate(train_loader):
# 获得一个批次的数据和标签
inputs,labels = data
# 获得模型预测结果(64,10)
out = model(inputs)
# 交叉熵代价函数out(batch,C:类别的数量),labels(batch)
loss = mse_loss(out,labels)
# 梯度清零
optimizer.zero_grad()
# 计算梯度
loss.backward()
# 修改权值
optimizer.step()
def test():
# 模型的测试状态
model.eval()
correct = 0 # 测试集准确率
for i,data in enumerate(test_loader):
# 获得一个批次的数据和标签
inputs,labels = data
# 获得模型预测结果(64,10)
out = model(inputs)
# 获得最大值,以及最大值所在的位置
_,predicted = torch.max(out,1)
# 预测正确的数量
correct += (predicted==labels).sum()
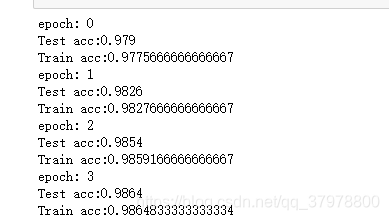
print("Test acc:{0}".format(correct.item()/len(test_data)))
correct = 0
for i,data in enumerate(train_loader): # 训练集准确率
# 获得一个批次的数据和标签
inputs,labels = data
# 获得模型预测结果(64,10)
out = model(inputs)
# 获得最大值,以及最大值所在的位置
_,predicted = torch.max(out,1)
# 预测正确的数量
correct += (predicted==labels).sum()
print("Train acc:{0}".format(correct.item()/len(train_data)))
# 训练
for epoch in range(10):
print("epoch:",epoch)
train()
test()