TensorFlow 笔记-07-神经网络优化-交叉熵,学习率
交叉熵
- 交叉熵(Cross Entropy):表示两个概率分布之间的距离,交叉熵越大,两个概率分布距离越远,两个概率分布越相异;交叉熵越小,两个概率分布距离越近,两个概率分布越相似
- 交叉熵计算公式:H(y_, y) = -Σy_ * log y
用 Tensorflow 函数表示
ce = -tf.reduce_mean(y_*tf.clip_by_value(y, le-12, 1.0)))
例如:
两个神经网络模型解决二分类问题中,已知标准答案为 y_ = (1, 0),第一个神经网络模型预测结果为 y1 = (0.6, 0.4),第二个神经网络模型预测结果为 y2 = (0.8, 0.2),判断哪个神经网络模型预测得结果更接近标准答案
H(1, 0), (0.6, 0.4) = -(1 * log0.6 + 0*log0.4) ≈ -(-0.222 + 0) = 0.222
H(1, 0), (0.8, 0.2) = -(1 * log0.8 + 0*log0.2) ≈ -(-0.097 + 0) = 0.097
softmax 函数
- softmax 函数:将 n 分类中的 n 个输出(y1, y2…yn)变为满足以下概率分布要求的函数:
∀x = P(X = x) ∈ [0, 1] - softmax 函数表示为:
- softmax 函数应用:在 n 分类中,模型会有 n 个输出,即 y1,y2 … n, 其中yi表示第 i 中情况出现的可能性大小。将 n 个输出经过 softmax 函数,可得到符合概率分布的分类结果
- 在 Tensorflow 中,一般让模型的输出经过 softmax 函数,以获得输出分类的概率分布再与标准答案对比,求出交叉熵,得到损失函数,用如下函数实现:
ce = tf.nn.sparse_softmax_cross_entropy_with_logits(logits = y, labels = tf.argmax(y_, 1))
cem = tf.reduce_mean(ce)
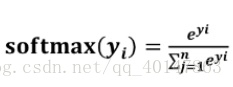
学习率
- 学习率 learning_rate: 表示了每次参数更新的幅度大小。学习率过大,会导致待优化的参数在最小值附近波动,不收敛;学习率过小,会导致待优化的参数收敛缓慢
- 在训练过程中,参数的更新向着损失函数梯度下降的方向
- 参数的更新公式为:
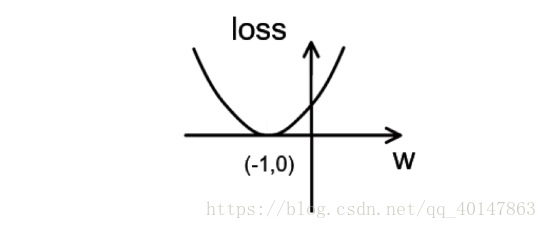
wn+1 = wn - learning_rate▽ 假设损失函数 loss = (w + 1)2。梯度是损失函数 loss 的导数为 ▽ = 2w + 2 。如参数初值为5,学习率为 0.2,则参数和损失函数更新如下:
1次 ·······参数w: 5 ·················5 - 0.2 * (2 * 5 + 2) = 2.6
2次 ·······参数w: 2.6 ··············2.6 - 0.2 * (2 * 2.6 + 2) = 1.16
3次 ·······参数w: 1.16 ············1.16 - 0.2 * (2 * 1.16 +2) = 0.296
4次 ·······参数w: 0.296损失函数loss = (w + 1) 2 的图像为:
由图可知,损失函数 loss 的最小值会在(-1,0)处得到,此时损失函数的导数为 0,得到最终参数 w = -1。
代码 tf08learn 文件:https://xpwi.github.io/py/TensorFlow/tf08learn.py
# coding: utf-8
# 设损失函数loss = (w + 1)^2 , 令 w 是常数 5。反向传播就是求最小
# loss 对应的 w 值
import tensorflow as tf
# 定义待优化参数 w 初值赋予5
w = tf.Variable(tf.constant(5, dtype=tf.float32))
# 定义损失函数 loss
loss = tf.square(w + 1)
# 定义反向传播方法
train_step = tf.train.GradientDescentOptimizer(0.20).minimize(loss)
# 生成会话,训练40轮
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
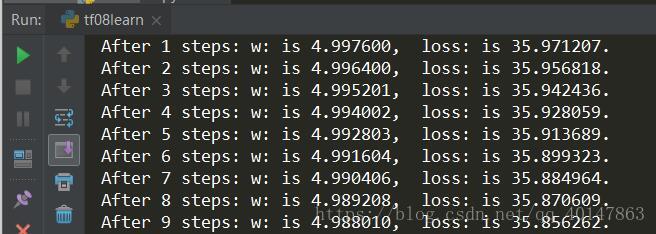
for i in range(40):
sess.run(train_step)
W_val = sess.run(w)
loss_val = sess.run(loss)
print("After %s steps: w: is %f, loss: is %f." %(i, W_val, loss_val))运行结果
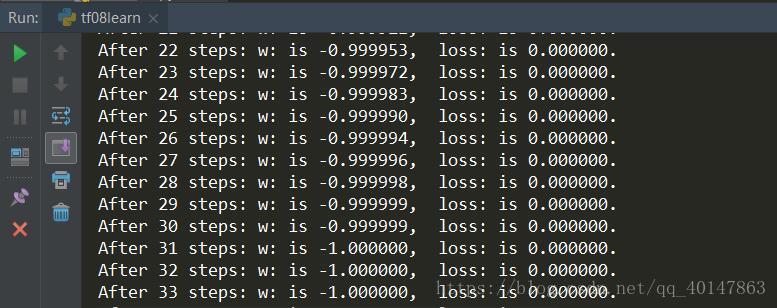
运行结果分析: 由结果可知,随着损失函数值得减小,w 无线趋近于 -1。
学习率的设置
- 学习率过大,会导致待优化的参数在最小值附近波动,不收敛;学习率过小,会导致待优化的参数收敛缓慢
- 例如:
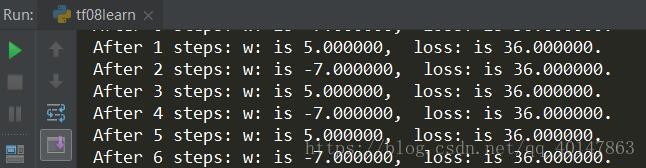
- (1) 对于上例的损失函数loss = (w + 1) 2,则将上述代码中学习率改为1,其余内容不变。
实验结果如下:
- (2) 对于上例的损失函数loss = (w + 1) 2,则将上述代码中学习率改为0.0001,其余内容不变。
实验结果如下:
由运行结果可知,损失函数 loss 值缓慢下降,w 值也在小幅度变化,收敛缓慢
指数衰减学习率
- 指数衰减学习率:学习率随着训练轮数变化而动态更新
其中,LEARNING_RATE_BASE 为学习率初始值,LEARNING_RATE_DECAY 为学习率衰减率,global_step 记录了当前训练轮数,为了不可训练型参数。学习率 learning_rate 更新频率为输入数据集总样本数除以每次喂入样本数。若 staircase 设置为 True 时,表示 global_step / learning rate step 取整数,学习率阶梯型衰减;若 staircase 设置为 False 时,学习率会是一条平滑下降的曲线。
- 例如:
在本例中,模型训练过程不设定固定的学习率,使用指数衰减学习率进行训练。其中,学习率初值设置为0.1,学习率衰减值设置为0.99,BATCH_SIZE 设置为1。 - 代码 tf08learn2 文件:https://xpwi.github.io/py/TensorFlow/tf08learn2.py
- 例如:

# coding: utf-8
'''
设损失函数loss = (w + 1)^2 , 令 w 初值是常数5,
反向传播就是求最优 w,即求最小 loss 对应的w值。
使用指数衰减的学习率,在迭代初期得到较高的下降速度,
可以在较小的训练轮数下取得更有收敛度
'''
import tensorflow as tf
LEARNING_RATE_BASE = 0.1 # 最初学习率
LEARNING_RATE_DECAY = 0.99 # 学习率衰减率
# 喂入多少轮 BATCH_SIZE 后,更新一次学习率,一般设置为:样本数/BATCH_SIZE
LEARNING_RATE_STEP = 1
# 运行了几轮 BATCH_SIZE 的计算器,初始值是0,设为不被训练
global_step = tf.Variable(0, trainable=False)
# 定义指数下降学习率
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, global_step,
LEARNING_RATE_STEP, LEARNING_RATE_DECAY, staircase=True)
# 定义待优化参数 w 初值赋予5
w = tf.Variable(tf.constant(5, dtype=tf.float32))
# 定义损失函数 loss
loss = tf.square(w+1)
# 定义反向传播方法
# 学习率为:0.2
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# 生成会话,训练40轮
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
for i in range(40):
sess.run(train_step)
learning_rate_val = sess.run(learning_rate)
global_step_val = sess.run(global_step)
w_val = sess.run(w)
loss_val = sess.run(loss)
print("After %s steps: global_step is %f; : w: is %f;learn rate is %f; loss: is %f."
%(i,global_step_val, w_val, learning_rate_val, loss_val))运行结果
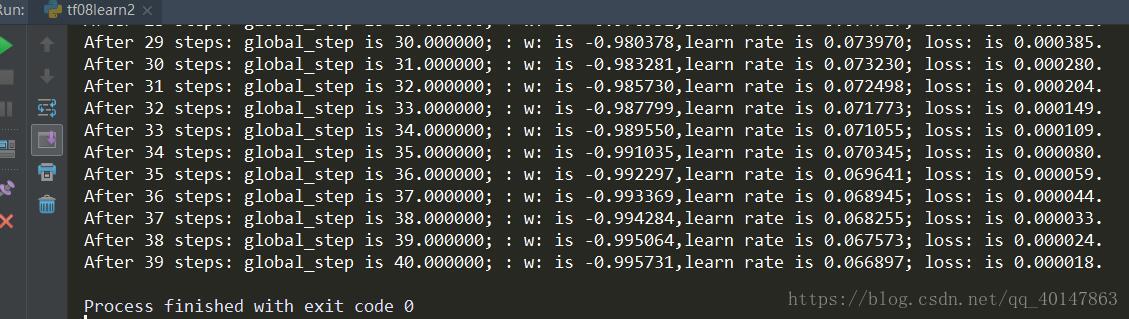
由结果可以看出,随着训练轮数增加学习率在不断减小
拜拜

- 本笔记不允许任何个人和组织转载