【图像篡改检测1】Learning Rich Features for Image Manipulation Detection_二十二画小生的博客-CSDN博客_图像篡改检测前言今天阅读的论文是《Learning Rich Features for Image Manipulation Detection》这可以算是图像篡改检测领域的一部经典之作。Abstract首先说明了图像篡改检测不同于显著性检测的一个很重要的区别在于:需要学习到更加丰富的特征it pays more at- tention to tampering artifacts than to image content, which suggests that richer features need https://blog.csdn.net/weixin_43343116/article/details/107497378RGBN是一个比较有意义的开创性工作,不过现在回头来看,其实也还好,它主要在自己造的数据上训练,本文也阐述了图像篡改检测和显著性检测的不同,篡改检测希望学到更加丰富的特征,我自己理解,文本篡改检测不仅要到文本的粒度,更要去检测文本中异常的样本,它其实要更加细粒度一些。有的时候也确实需要多给一些先验才能很好的处理,不然就多加一些数据,只不过加数据可能存在目标样本分布和造的样本分布存在差异的情况,这种情况其实也不利于应用。
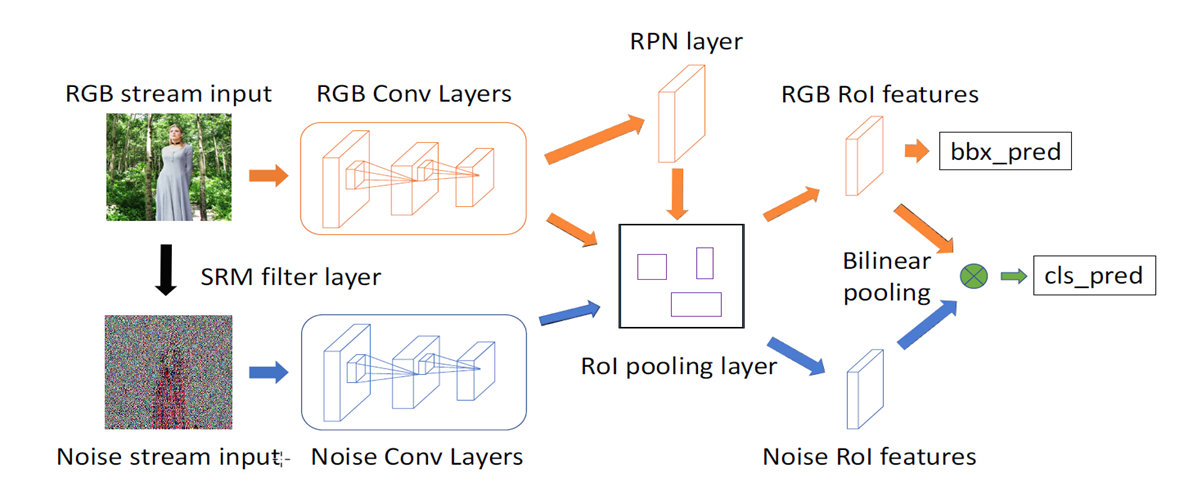
主要是上面这张图,RGBN其实就是双流fasterrcnn,在原本fasterrcnn的基础上加了一个噪声流,噪声流使用srm滤波器。橘黄色箭头连起来的是RGB流,蓝色箭头的是噪声流,噪声流是将输入的RGB图像传递通过SRM滤波器来获得噪声特征图,并利用噪声特征为篡改提供额外的辅助特征,其实辅助特征的思路还有很多,噪声流,dct流,noiseprint等,后面还有集大成的mvssnet,我前面分析过的,它三个支路,bce的image分类,noise维度的语义dice loss,还有edge的dice loss.这里注意的是RGB和噪声流共享来自RPN网络的proposal,但RPN经使用RGB特征作为输入,这也能理解,噪声流也送到RPN中就学不明白了,噪声流只是把RGB流学出来的RPN上直接pooling出来,这里的proposal也不再是目标,而是篡改对象,所以说其实篡改定位是由RGB流做初筛的,此外预测的bbox也是出自RGB流,这也能理解,噪声流只在产生标签时才加入到模型中。
此外SRM也没有使用30个channel,而是只用了3个滤波器,作者实验说了效果也很好。