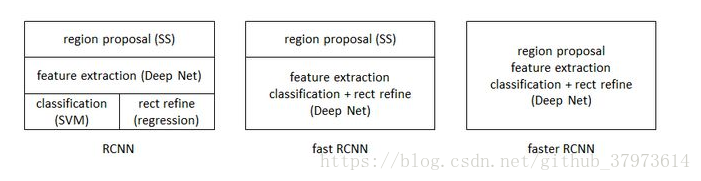
RCNN系列对比图,来源
1、本文主要是记录RCNN。论文相对于以前的传统方法的改进有:
- 速度,经典的目标检测算法使用滑动窗口依次判断所有可能的区域。本文则(采用selective Search方法)预先提取一系列较可能是物体的候选区域,之后仅仅在这些候选区域上进行feature extraction,进行判断。
- 训练集,经典的目标检测算法在区域中提取人工设定的特征。本文则采用深度网络进行特征提取。使用两个数据库,一个较大的识别库(ImageNet ILSVC 2012):标定每张图片中物体的类别。一千万张图像,1000类。一个较小的检测库(PASCAL VOC2007):标定每张图片中,物体的类别和位置,一万图像,20类。本文使用是别人进行与训练得到CNN(有监督预训练),而后用检测库调优参数,最后在检测库上评测。
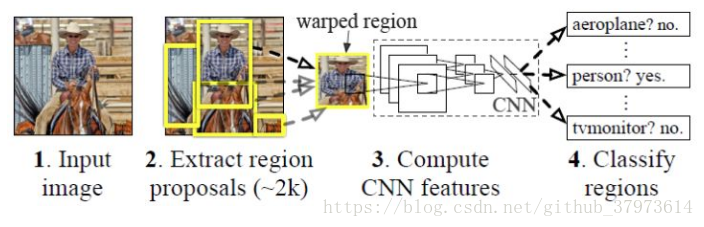
2、RCNN的主要步骤
- 候选区域的提取:一张图像生成1k~2k的候选区域,使用的Selective Search方法
- 特征提取:对每个候选区域,使用深度网络提取特征(CNN),将提取到的feature map保存到磁盘。
- 类别判断:将特征送入到每一类的SVM分类器,判断是否属于该类。【利用feature map训练SVM来对目标和背景进行分类,每个类一个二进制SVM】
- 位置精修:使用回归去精细修正候选框的位置
3、步骤细节
- 候选框的选取:要搜索出图片中所有可能是物体的区域,搜出的候选框是矩形的,而且大小各有不同。然后CNN对输入图片的大小是固定的。因此需要对每个候选框进行大小预处理。在paper里有两种不同的处理方法:
- 各向异性缩放:不管图片的长宽比例,直接进行缩放,变为CNN的nxn的大小。
- 各向同性缩放:solution_A,先扩充再裁剪,直接在原始图片中,把候选框的边界进行扩展延伸成正方形,然后进行裁剪;如果已经延伸到了原始图片的外边界,那么就用候选框的中的颜色均值来填充。solution_B,先裁剪后扩充,把候选框的图片裁剪出来,然后用固定的背景颜色填充成正方形图片(背景颜色也是采用候选框的像素颜色均值)。【对于A,B方法,paper中还有个padding处理,作者发现采用各向异性缩放、padding=16的精度最高。】
- 特征提取:Alexnet的精度为58.5%,VGG16精度为66%,但是AlexNet计算量比较小。Alexnet包含5个卷积层、2个全连接层,pool5层的神经元个数为9216、f6和f7的神经元个数都是4096个,最终提取特征每个输入候选框图片都能得到一个4096维的特征向量,那么如果是2000个候选框,则有2000x4096维度。
- 这里,初始化的参数也是直接选取已经训练好的Alexnet的参数作为初始化参数,然后fine-tuning训练。
- 我们在将候选框放入到CNN训练的前,需要先将框标注好为正、负样本,与ground-truth box的IOU>0.5则认为是正样本【正样本在这里应该有对应的ground-truth box类别,这样在back-propagation时才能得到对于的loss来进行梯度下降】,否则是负样本,即背景。
- 假设要检测的物体种类是N个,那么我们需要将上面预训练的CNN(AlexNet)最后一层给替换掉,替换成N+1个输出的神经元(加1是background),然后这一层采用参数随机初始化的方法。其他的网络层参数不变。接着就可以使用SGD训练了,learning rate=0.001。每次训练时,batch size=128,其中32个是正样本,96个是负样本。【这里注意了,这里的分类,不用做最后的分类,因为我们这里主要是为了进行fine-tuning,所以在IOU选择时(IOU>0.5就当作正样本,是为了增加CNN训练的数据量)并不严格,故精度会比较低。】

- svm训练,类别判断:对于svm,我们只有当bounding box把整个物体包含在内才叫正样本。没有包含到的,且IOU<0.3的都是负样本。【作者测试了IOU阈值各种方案,最终采用了IOU阈值为0.3效果最好,即当重叠率小于0.3时,我们就将其标注为负样本。】一旦CNN f7层的特征被提取出来,那么我们将为每个物体类别训练一个svm分类器。当我们用CNN提取2000个候选框,可以得到2000x4096这样的特征向量矩阵,然后我们只需要把这样的一个矩阵跟svm权值矩阵4096*N点乘(N为分类类别数目,因为我们训练了N个svm,每个svm包含了4096个权值w。【那这个不就相当于一个全连接层么,f7与分类FC层之间的w为4096xN,即svm,而在fine-tuning里,使用的是N+1】),就可以得到结果。
- 位置精修:对每一类目标,使用一个线性回归器进行精修。输入为pool5层的4096维特征,输出为x,y方向的缩放和平移。训练样本:判定为本类的候选框中和真值重叠面积大于0.6的候选框。
4、测试阶段
- 对图像进行Selective search得到2000个region proposals,并归一化到227x227
- 在CNN中提取特征,然后使用最后的层(SVM,20个神经单元??)对特征向量进行打分,得到一个2000x20的矩阵,其中20是类别。
- 对2000x20的每一列进行排序,然后对每一列进行NMS【将score最大的bounding box作为选定框,计算其余的bounding box与当前最大score与box的IOU,去除IOU大于设定阈值的bounding box。重复上面步骤,直至候选bounding box为空,在将score小于一定阈值的选定狂删除得到这一类的结果。然后继续下一个分类的NMS,即下一列】。
问题解释:
- Selective Search:first使用一种过分割手段【过分割就是把本来属于一个整体的目标分成多个,比如分割一朵花,结果把花瓣、茎叶全分到不同的区域,这就是过分割】,将图像分割成小区域(1K~2K个)。second查看现在的小区域,按照合并规则合并可能性最高的两个相邻区域。重复知道整张图合并成一个区域位置。third输出所有曾经存在过的区域,所谓候选区域。 其中合并的规则如下:优先合并颜色(颜色直方图)相近、纹理(梯度直方图)相近的、合并后总面积小的、合并后,总面积在其BBox中所占比例最大的(保证合并后的形状规则)。
- 超像素【参考】:为了在不牺牲太大精确度的情况下降维。超像素最直观的解释就是把一些具有相似特性的像素“聚合”起来,形成一个更具有代表性的大“元素”。而这个新的元素,将作为其他图像处理算法的基本单位。一来可以大大降低了维度,二来可以剔除一些异常像素点。至于根据什么特性把一个个像素点聚集起来,可以是颜色、纹理、类别等。


- 对于目标检测问题:图片分类标注好的训练数据非常多,但是物体检测的标注数据却很少,如何用少量的标注数据,训练高质量的模型,这就是文献最大的特点,这篇论文采用了迁移学习的思想:先用了ILSVRC2012这个训练数据库(这是一个图片分类训练数据库),先进行图片分类训练【预训练CNN】。这个数据库有大量的标注数据,共包含了1000种类别物体,因此预训练阶段CNN模型的输出是1000个神经元(当然也直接可以采用Alexnet训练的模型参数)。再在小型目标数据集PASCAL_VOC上微调(fine-tuning)CNN。
参考:https://zhuanlan.zhihu.com/p/23006190