对比
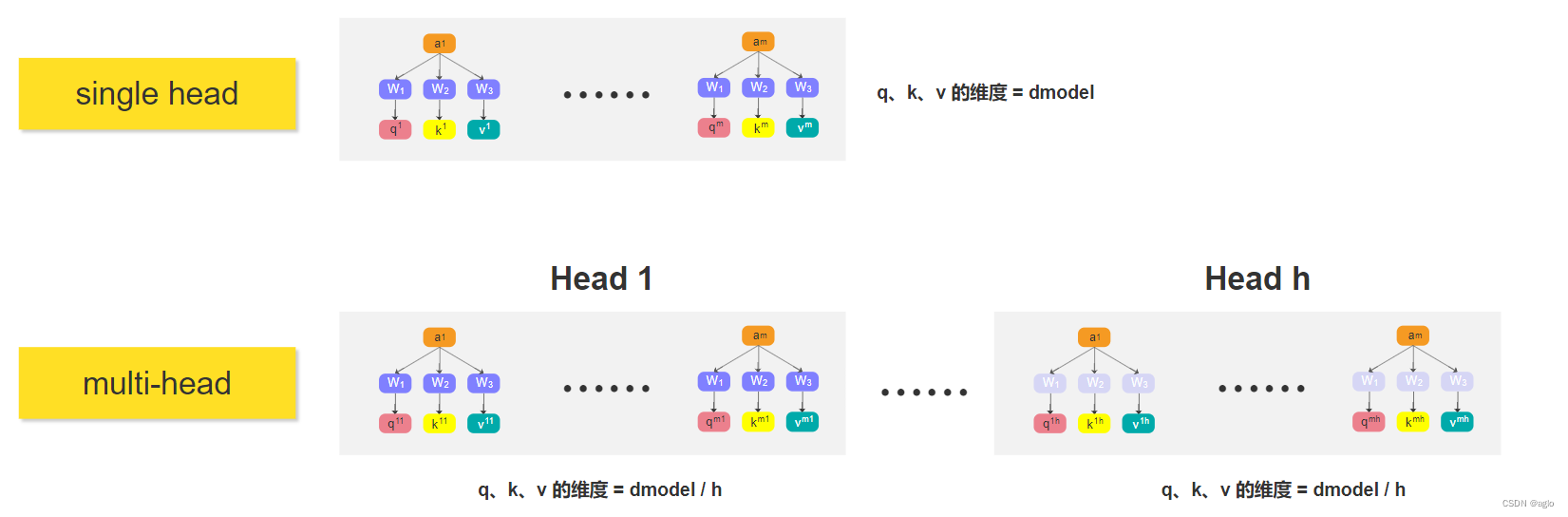
相比于single-head,multi-head就是将 q i q^i qi分成了 h h h份
multi-head_seft-attention的计算过程
-
将 q i q^i qi分成了 h h h份
-
计算过程
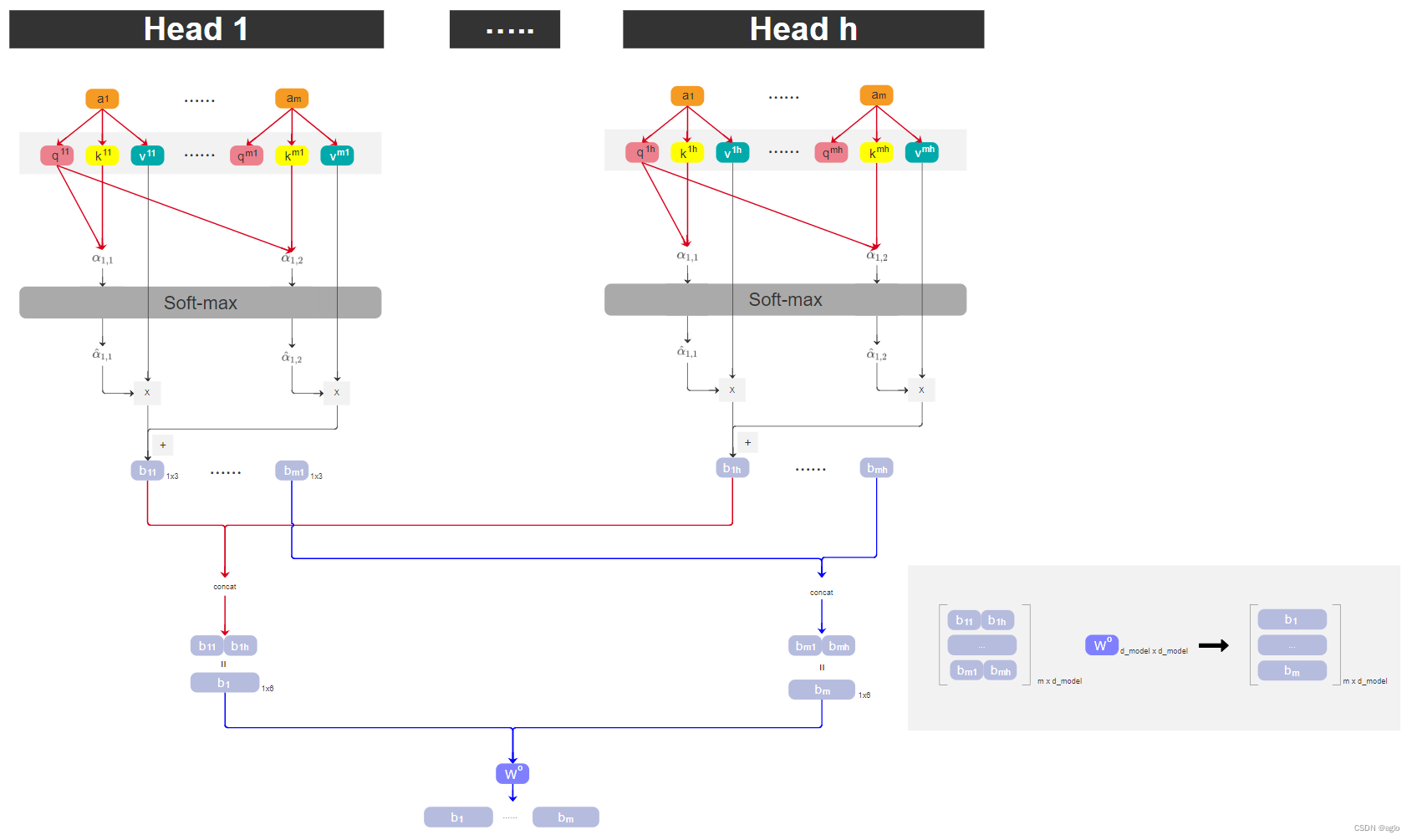
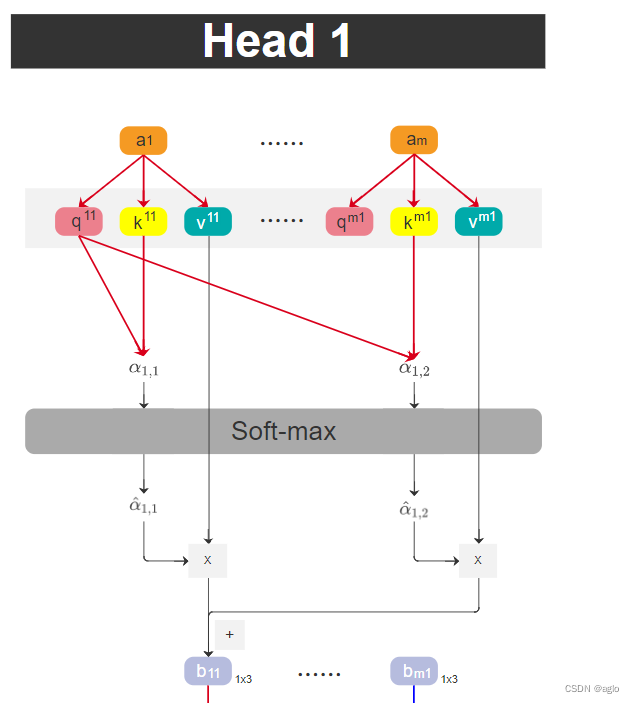
对于每个Head,我们可以提取出他的 b 11 b_{11} b11到 b m 1 b_{m1} bm1,以 H e a d 1 Head_1 Head1举例
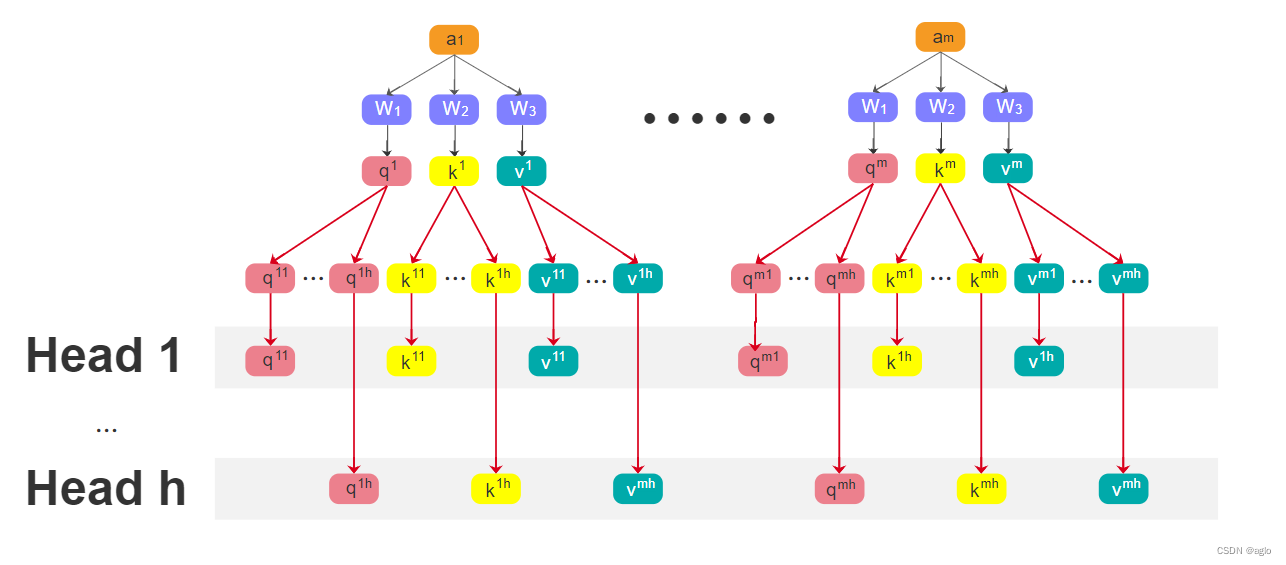
- 将输入序列进行embedding后,变为向量 a 1 a_1 a1, a 2 a_2 a2, a 3 a_3 a3, a 4 a_4 a4
- 分别乘 W 1 W_1 W1, W 2 W_2 W2, W 3 W_3 W3后,提取 q 1 q^1 q1、 k 1 k^1 k1、 v 1 v^1 v1,将 q 1 q^1 q1分成了 h h h份,其他两个也一样
- q 11 q^{11} q11 query分别和自己的 k 11 k^{11} k11以及其他token的key相乘,得到m个相似度分数,再经过softmax处理,得到新的m个分数。
- 将处理后的权重得分分别于 v 11 v^{11} v11、… 、 v m 1 v^{m1} vm1相乘,结果再相加,得到 b 11 b_{11} b11,其他以此类推,直到 b m 1 b_{m1} bm1
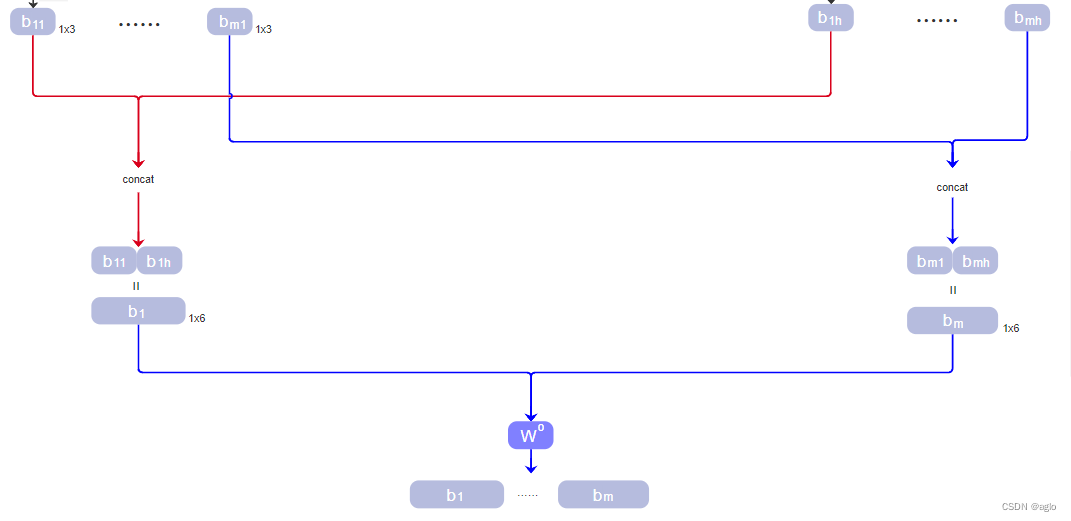
在这之后,我们将对应位置的 b b b,concat起来
-
先按列concat,再按行concat
- 所有head中的第一个 b 11 b_{11} b11、 b 12 b_{12} b12等,我们把它concat起来,组成一个大 b 1 b_1 b1
- 对于第m个位置,我们将所有head中的 b m i b_{mi} bmi concat起来,组成一个大 b m b_m bm
-
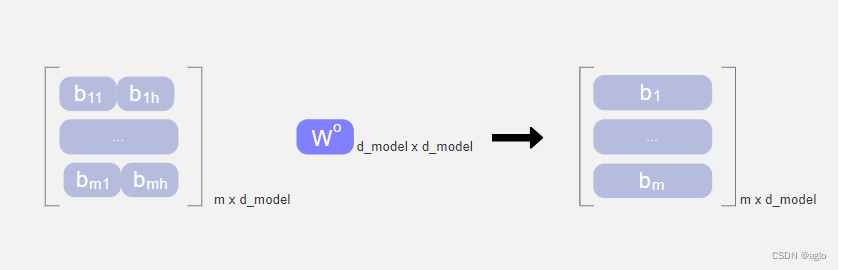
W o W^o Wo代表进行全连接,得到一个最终的结果[ b 1 b_1 b1、… 、 b m b_m bm]
m就是token的个数
d_model就是每个token的维度