前言
故事的开始要从一个下雨的夜和一部装有网易云音乐的说起,十二点我准时打开网易云,回忆我那逝去的青春,众所周知,网易云是一个评论分享软件,那要不试试爬一下评论看看。

思路
前期由于过度高估自己,一直想试试js逆向,看看可不可以搞下来,结果还是高估了自己

然后看了看大佬的文章,发现有大佬直接找到了网易云评论的接口,不需要任何的加密啥的,在此感谢一手大佬的努力。
接下来就很好搞了,访问一下接口,评论就拿下来了,真是舒服。接下就来写代码吧
具体代码
重点:调用下面的接口直接可以获取评论
评论接口:http://music.163.com/api/v1/resource/comments/R_SO_4_{歌曲id}?limit=100&offset={页码}
获取评论内容
访问接口
def getJson(url):
r = requests.get(url, headers=header)
return r.json()['comments']
解析接口返回的评论内容
comments=getJson(url)
for i in range(1,15):
for c in comments:
text=text+c['content']
评论制作词云
词云工具类
# -*- codeing = utf-8 -*-
# @Time : 2021/10/9 20:54
# @Author : xiaow
# @File : wordcloudutil.py
# @Software : PyCharm
from wordcloud import WordCloud
import PIL.Image as image
import numpy as np
import jieba
def trans_CN(text):
# 接收分词的字符串
word_list = jieba.cut(text)
# 分词后在单独个体之间加上空格
result = " ".join(word_list)
return result
def getWordCloud(text):
# print(text)
text = trans_CN(text)
mask = np.array(image.open("E://file//pics//1.png"))
wordcloud = WordCloud(
mask=mask,
font_path="C:\Windows\Fonts\STXINGKA.TTF",
background_color='white'
).generate(text)
image_produce = wordcloud.to_image()
image_produce.show()
生成词云
text=''
songId = "1340001163"
page = 1
url = "http://music.163.com/api/v1/resource/comments/R_SO_4_{0}?limit=100&offset={1}".format(songId, str(page))
comments=getJson(url)
for i in range(1,15):
for c in comments:
text=text+c['content']
wordcloudutil.getWordCloud(text)
成果
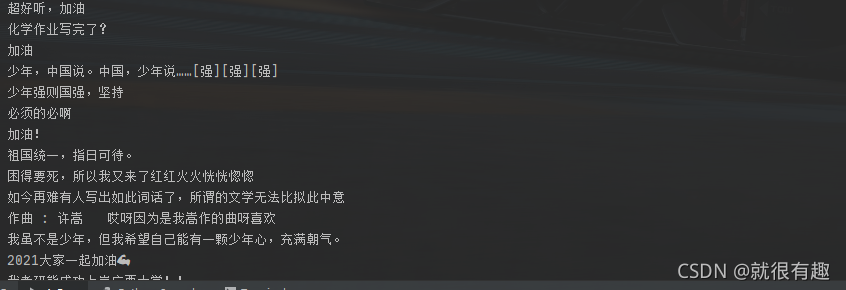
最近周董的歌曲又在网易云上线了,那就拿周董的歌来练练手。
布拉格广场

一块来聊聊你是什么时候开始听周董的吧。
下面推荐下自己的专栏,关于爬虫的基础内容,适合新手练练手
❤️爬虫专栏,快来点我呀❤️
聊天没有表情包被嘲讽,程序员直接用python爬取了十万张表情包
两行代码爬取微博热搜,并实现邮件提醒功能,妈妈再也不用担心我吃不到瓜了 爬虫基础
有缘再写,侵权立删