网上的爬取网易云评论的方法大多数是讲如何构建参数去破解它的一些加密,然后再去爬取评论。
但是我们可以通过网易云的API接口,因为它是属于非加密的get请求,所以难度就直线下降。
这里有一点需要注意:
在一首歌每页显示20条评论的情况下,只有前500页是不重复的评论,从500页之后都是第500页的内容。在网页端和pc端都是这样。也就是说我们只能爬取到最多2万条数据。
同时在XHR中发现获取不到的评论中间部分,确实是请求到了数据包,但内容均是第500页的重复内容。
之前看到过一篇文章,他在爬评论的时候竟然中间的一页,举个例子:一共2001页评论,正常只能爬取前500页或者后500页,同时他页爬取到了第1001页的真实数据,然后其他的都是第500页的重复数据。
感觉这也是网易云的一种类似反爬虫机制吧。
回归正题:这里我们完全没必要去考虑如何构造参数,如何去破解加密,直接调用网易云的API就好了:
# 网易云音乐评论API,其中********为音乐ID,limit为页面结果限制数,最大可设为100,offset为页面偏移量
http://music.163.com/api/v1/resource/comments/R_SO_4_********?limit=20&offset=0
# 用户信息API
https://music.163.com/api/v1/user/detail/{用户ID}
这里我以野狼disco为例:
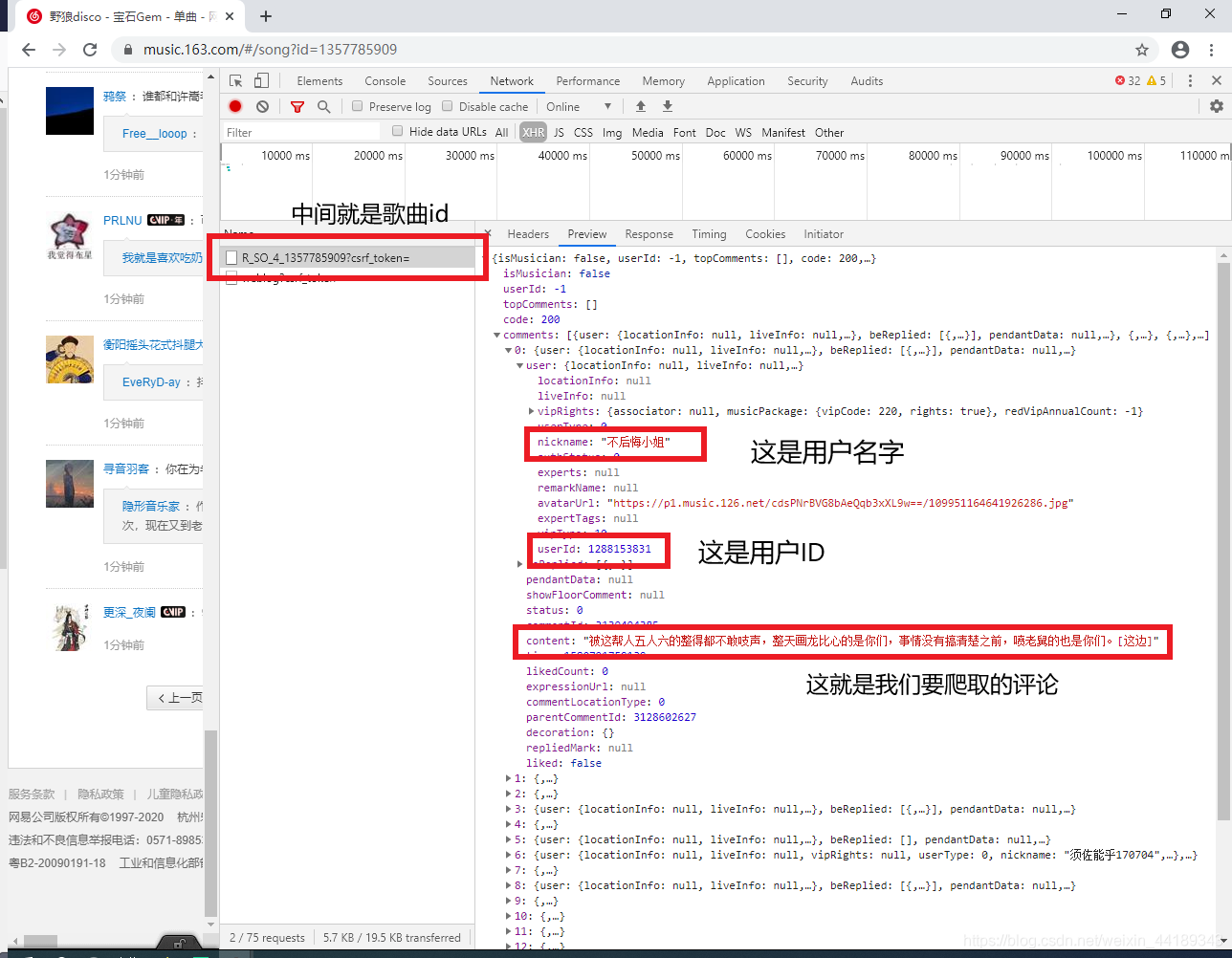
这里使用了开发者工具,如果有不知道的可以去下面的网址了解一下。
https://blog.csdn.net/zengzhenzong/article/details/80446732
下面就是代码了:
import json
import time
import requests
headers = {
'Host': 'music.163.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
def get_user(user_id):
"""
获取用户注册时间
"""
data = {}
url = 'https://music.163.com/api/v1/user/detail/' + str(user_id)
response = requests.get(url=url, headers=headers)
# 将字符串转为json格式
js = json.loads(response.text)
if js['code'] == 200:
# 性别
data['gender'] = js['profile']['gender']
# 年龄
if int(js['profile']['birthday']) < 0:
data['age'] = 0
else:
data['age'] = (2018 - 1970) - (int(js['profile']['birthday']) // (1000 * 365 * 24 * 3600))
if int(data['age']) < 0:
data['age'] = 0
# 城市
data['city'] = js['profile']['city']
# 个人介绍
data['sign'] = js['profile']['signature']
else:
data['gender'] = '无'
data['age'] = '无'
data['city'] = '无'
data['sign'] = '无'
return data
def get_comments(page):
"""
获取评论信息
"""
url = 'http://music.163.com/api/v1/resource/comments/R_SO_4_1313354324?limit=20&offset=' + str(page)
response = requests.get(url=url, headers=headers)
# 将字符串转为json格式
result = json.loads(response.text)
items = result['comments']
for item in items:
# 用户名
user_name = item['user']['nickname'].replace(',', ',')
# 用户ID
user_id = str(item['user']['userId'])
# 获取用户信息
user_message = get_user(user_id)
# 用户年龄
user_age = str(user_message['age'])
# 用户性别
user_gender = str(user_message['gender'])
# 用户所在地区
user_city = str(user_message['city'])
# 个人介绍
user_introduce = user_message['sign'].strip().replace('\n', '').replace(',', ',')
# 评论内容
comment = item['content'].strip().replace('\n', '').replace(',', ',')
# 评论ID
comment_id = str(item['commentId'])
# 评论点赞数
praise = str(item['likedCount'])
# 评论时间
date = time.localtime(int(str(item['time'])[:10]))
date = time.strftime("%Y-%m-%d %H:%M:%S", date)
print(user_name, user_id, user_age, user_gender, user_city, user_introduce, comment, comment_id, praise, date)
with open('music_comments.csv', 'a', encoding='utf-8-sig') as f:
f.write(user_name + ',' + user_id + ',' + user_age + ',' + user_gender + ',' + user_city + ',' + user_introduce + ',' + comment + ',' + comment_id + ',' + praise + ',' + date + '\n')
f.close()
def main():
# 前500页
# for i in range(210000, 230000, 20):
# 后500页
for i in range(0, 25000, 20):
print('\n---------------第 ' + str(i // 20 + 1) + ' 页---------------')
get_comments(i)
if __name__ == '__main__':
main()