爬取网易云音乐评论
01 网页分析
为爬取网易云音乐的评论内容,本案例将提供思路简单的处理方式,网易云音乐一般会提供API,以JSON对象返回开发者请求的内容,而获取歌曲评论的API格式为“http://music.163.com/api/v1/resource/comments/R_SO_4_”+歌曲ID,一般评论的JSON对象显示的评论条数有限,为了获得完整的评论内容,需要加上参数单条JSON加载评论条数(limit)和偏移量(offset),然后发送GET请求,如图17-1所示,JSON会显示评论内容和评论总数,基于以上参数可以间隔发送请求以获得全部评论内容,即可编写爬虫。
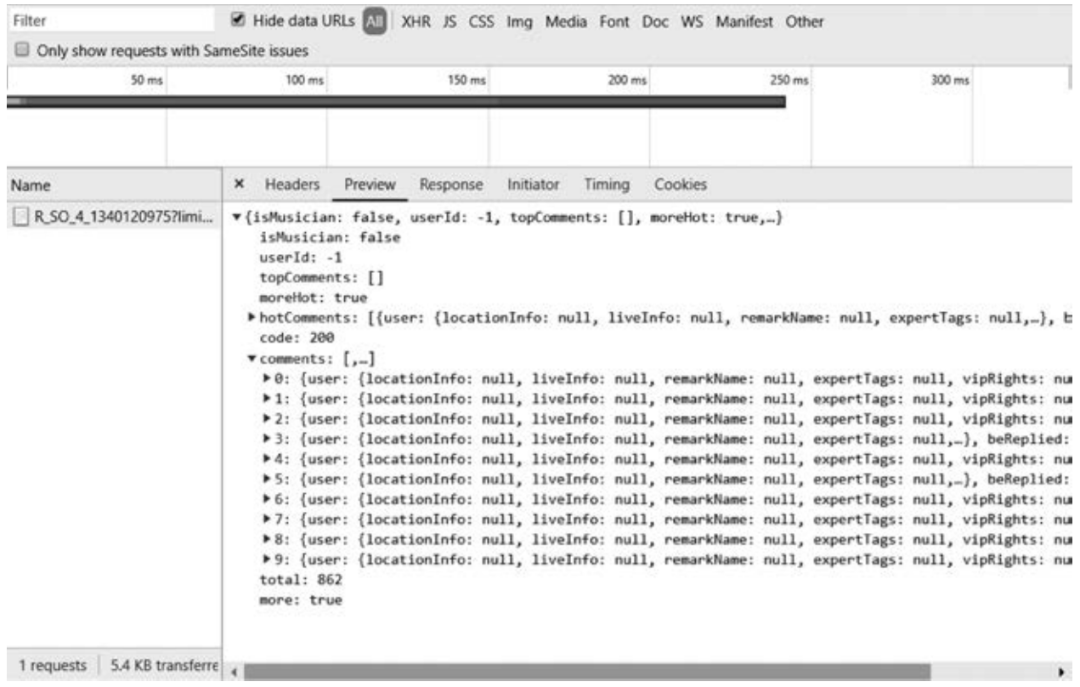
■ 图17-1网页分析JSON对象内容
02 编写爬虫



关于正则表达式处理用于分析的文本,在文本分析中,为了提高准确率以及避免程序产生bug,需要预先去除一些不必要的字符,如标点符号以及非文字的表情等特殊字符,这些都会对文本分析造成干扰,通常采取re.sub(pat, “”, Str),pat为预先编译的正则表达式,将去除的字符替换为空字符,下面将提供一些正则表达式的思路。
(1) re.compile(‘\t|\n|\.|-|: |; |\)|\(|\?|(|)|\|"|\u3000’),用于去除标点符号和空格。
(2) 利用正则表达式特性,[^**]表示不匹配此字符集中的任何一个字符,可以反选需要的字符集,除了基本的[a-zA-Z0-9]匹配,如果采取Unicode编码方式,汉字的Unicode范围为\u4e00\u9fa5,数字的Unicode范围为\u0030\u0039,大写字母的Unicode范围为\u0041\u005a,小写字母的Unicode范围为\u0061\u007a,韩文的Unicode范围为\uAC00\uD7AF,日文的Unicode范围为\u3040\u31FF,根据文本分析的需要,保留需要的字符。
03 运行结果
【例17-1】分析著名民谣歌手赵雷的代表单曲《成都》(歌曲ID: 436514312),评论数有40多万,关键词云如图17-2所示。

■ 图17-2单曲《成都》词云分析结果
【例17-2】分析知名日本电视剧《假面骑士Build》的主题曲Be the One(歌曲ID: 530986958),评论数2万左右,采用自定义遮罩,关键词云如图17-3所示。

■ 图17-3单曲Be the One词云分析结果
最后:
【想要学习爬虫的朋友们 我这里整理了很多Python学习资料上传到CSDN官方了,有需要的朋友可以扫描下方二维码进行获取】
一、学习大纲

二、开发工具

三、Python基础材料

四、实战资料