以魏如萱为例,爬取热门前50首歌曲的评论
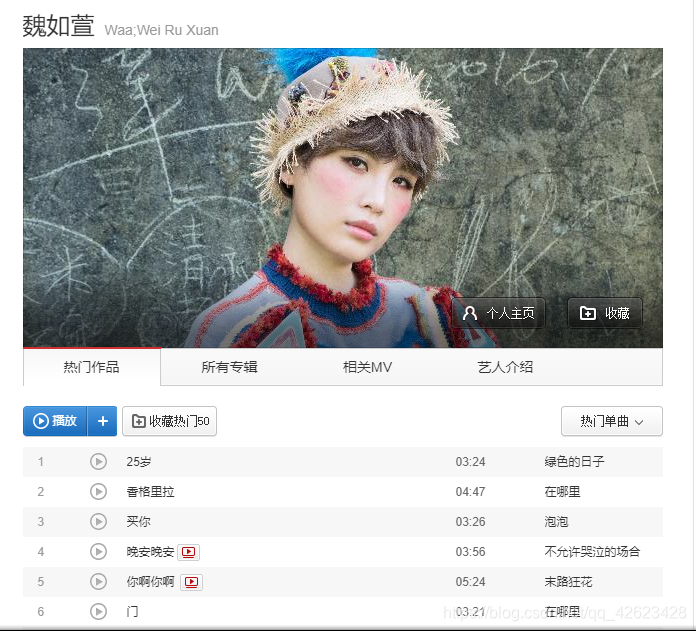
首先因为js异步加载的原因,直接获取源代码只能得到脚本自动生成的代码,因此我用的是selenium+chromdriver
来访问,这样就可以得到加载好的框架代码,然后找到各首歌曲对应的链接就好
之后,在network(以chrome为例)刷新页面,就能看到network的动作
我们可以发现,点击下一页评论,只有评论会刷新,而页面的URL却不会变化,因此后台向服务器发送的请求是xhr(XMLHttpRequset)对象,即在后台与服务器交换数据,而在不重新加载页面的情况下更新网页内容。
之后就可以找到这个R_SO_4_93465...文件,可以找到评论的数据包
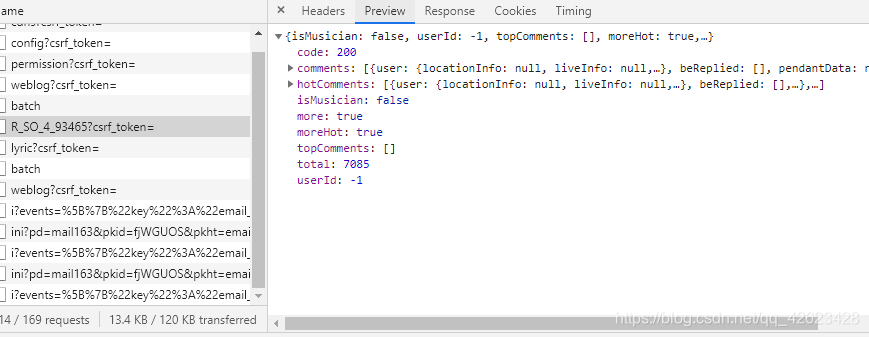
然后就有两个参数 params以及encSecKey
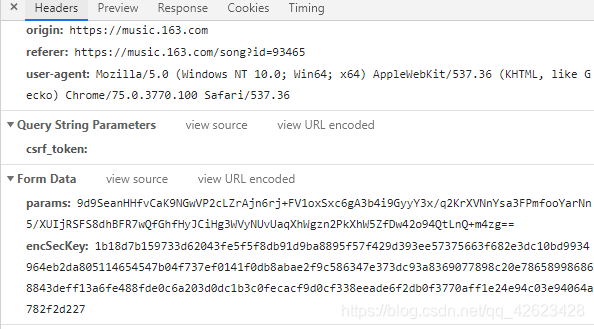
观察可知只有这两个参数 params和encSecKey会随页面改变,进而response也刷新出下一页的评论。因此这是通过不同页面的params以及encSecKey参数的不同变化来向服务器发起请求并获取相应评论。
扫描二维码关注公众号,回复:
13117247 查看本文章

下一步就是搞清楚不同页面的params以及encSecKey参数是如何改变的
方法来源于 @平胸小仙女的知乎回复 https://www.zhihu.com/question/36081767
first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
second_param = "010001"
third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
forth_param = "0CoJUm6Qyw8W8jud"
def get_params(page):
#获取encText,也就是params
iv = "0102030405060708"
first_key = forth_param
second_key = 'F' * 16
if page == 0:
first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
else:
offset = str((page - 1) * 20)
first_param = '{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}' % (offset, 'false')
encText = AES_encrypt(first_param, first_key, iv)
encText = AES_encrypt(encText.decode('utf-8'), second_key, iv)
return encText
def AES_encrypt(text, key, iv):
#AES加密
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key.encode('utf-8'), AES.MODE_CBC, iv.encode('utf-8'))
encrypt_text = encryptor.encrypt(text.encode('utf-8'))
encrypt_text = base64.b64encode(encrypt_text)
return encrypt_text
def get_encSecKey():
encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"
return encSecKey然后就可以程序生成这两个参数,之后获取各页的评论即可
代码如下:
import requests
from lxml import html
from bs4 import BeautifulSoup
from urllib import request
import time
from selenium import webdriver
import json
import base64
from Crypto.Cipher import AES
headers = {
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36',
'Connection': 'keep-alive',
'cookie': '_ntes_nnid=f16bde86c506341f618fb99fdcc28d9e,1558509782535; _ntes_nuid=f16bde86c506341f618fb99fdcc28d9e; UM_distinctid=16c3e03a59b30b-091fb473f85019-e343166-100200-16c3e03a59c508; vinfo_n_f_l_n3=0eb845b1983b4757.1.0.1564408522345.0.1564408656227; JSESSIONID-WYYY=EbCTdI3GfX3zDVzVMRH2onZAiwIlJY6ddjGkKybs%5CFq7BSWSxFa1Jd%2FYMHE21RM3cp%2BViO%5CGHUkVo6q3ATjDacBPJ4FzN%5C4lKKffCHv9Zq9wElns%5CH84KHj9kxy9FaSDWtK99vrmW2Z3P%2BFtek4k%2BOAmmHCX0saY075wUoMCGqFveCm2%3A1566818588491; _iuqxldmzr_=32; WM_NI=dZSL%2B10AySvKGLv7nOxMeWMoNaegj6guS15s40hBTma%2F2PO2RusphiVGJorUYHdedWsbShcsGx6xO8IsI0zafzCh3g3YGydFIoyGNmNMjH%2BQTbD%2B5sZq5vUllYhi7qWDQkg%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eea7ec67a89bb7bad672a7a88fb3c14f828a8aaab865898da699e839fcb98997f42af0fea7c3b92aa8869dadaa3bf49fb7b4f5418594bad8ed45bc93abb8d0658ebfab88e93ea5ab9dd2b879f8f0a8a3d767a3f1feb1ce3a92abbd91eb6396998690f15f9b98ac86e75db1be9d89e27985a8fa99ce348bad87d1f96ba6a68d89b26df187899ae74e8bb1b7a8cd678e93a6a9aa5b98be8cccb8799aaffb97d868b087a88ab67b959c9f8ce637e2a3; WM_TID=iht%2BODmvLFFEFEAQQQc4pPGyhOns1Tq%2B',
'origin': 'https://music.163.com',
'referer': 'https://music.163.com/'
}
first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
second_param = "010001"
third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
forth_param = "0CoJUm6Qyw8W8jud"
def get_params(page):
#获取encText,也就是params
iv = "0102030405060708"
first_key = forth_param
second_key = 'F' * 16
if page == 0:
first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
else:
offset = str((page - 1) * 20)
first_param = '{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}' % (offset, 'false')
encText = AES_encrypt(first_param, first_key, iv)
encText = AES_encrypt(encText.decode('utf-8'), second_key, iv)
return encText
def AES_encrypt(text, key, iv):
#AES加密
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key.encode('utf-8'), AES.MODE_CBC, iv.encode('utf-8'))
encrypt_text = encryptor.encrypt(text.encode('utf-8'))
encrypt_text = base64.b64encode(encrypt_text)
return encrypt_text
def get_encSecKey():
encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"
return encSecKey
def get_json(url, params, encSecKey):
data = {
"params": params,
"encSecKey": encSecKey
}
try:
response = requests.post(url, headers=headers, data=data)
except requests.RequestException as e:
print('error')
content = response.content.decode('utf-8')
return content
path = 'test.txt'
def main():
url = 'https://music.163.com/#/artist?id=9609'
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
brower = webdriver.Chrome(chrome_options=chrome_options)
brower.get(url)
iframe = brower.find_element_by_class_name('g-iframe')
brower.switch_to.frame(iframe)
soup = BeautifulSoup(brower.page_source, 'lxml')
items = soup.find_all('span', 'txt')
for item in items:
item = item.a['href'].replace('/song?id=', '')
songUrl = 'https://music.163.com/weapi/v1/resource/comments/R_SO_4_'+item+'?csrf_token='
params = get_params(1)
encSecKey = get_encSecKey()
content = get_json(songUrl,params,encSecKey)
json_dict = json.loads(content)
comments = int(json_dict['total'])
if comments % 20 == 0:
pages = comments/20
else:
pages = int(comments/20)+1
f = open(path,'a',encoding='utf-8')
f.write('total'+str(comments)+'\n\n')
f.close()
for i in range(pages):
f = open(path,'a',encoding='utf-8')
params = get_params(i+1)
encSecKey = get_encSecKey()
text = get_json(songUrl,params,encSecKey)
json_dict = json.loads(text)
for item in json_dict['comments']:
f.write(item['user']['nickname']+':'+item['content']+'\n\n')
f.close()
brower.quit()
if __name__ == "__main__":
main()