Spark 可以跑在很多集群上,比如跑在local上,跑在Standalone上,跑在Apache Mesos上,跑在Hadoop YARN上等等。不管你Spark跑在什么上面,它的代码都是一样的,区别只是–master的时候不一样。其中Spark on YARN是工作中或生产上用的非常多的一种运行模式。今天主要对Spark on Yarn 这种方式做讲解。
作业提交
Standalone模式的提交
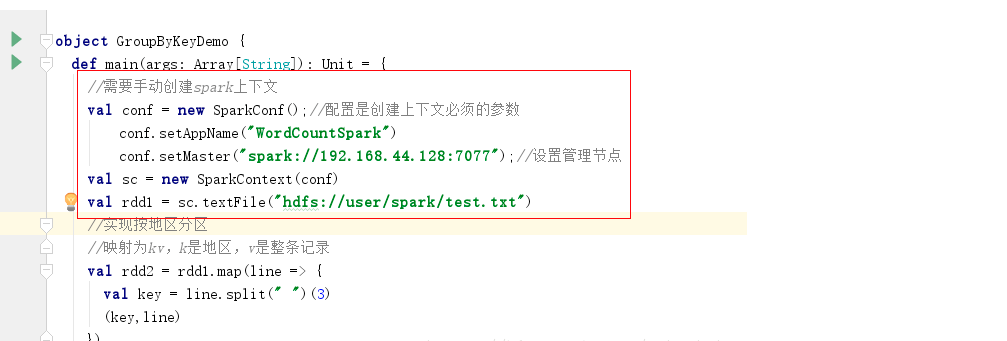
此处master设置为管理节点的集群地址(spark webui上显示的地址)
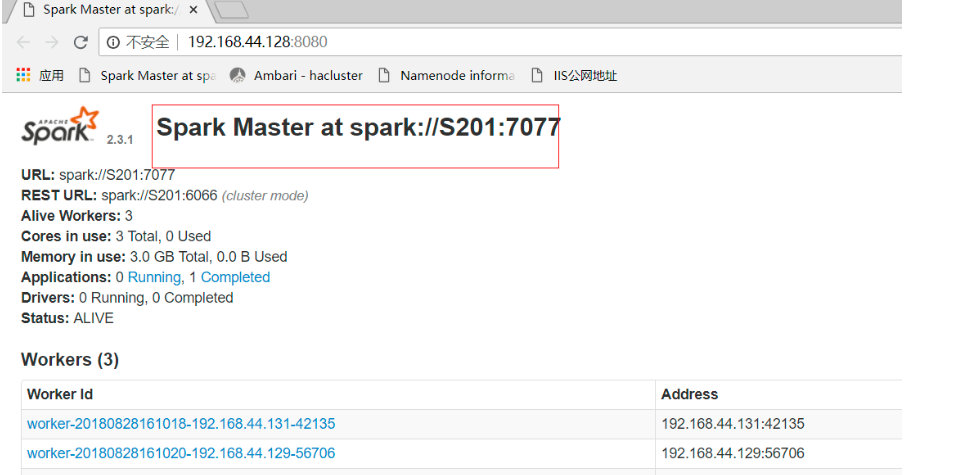
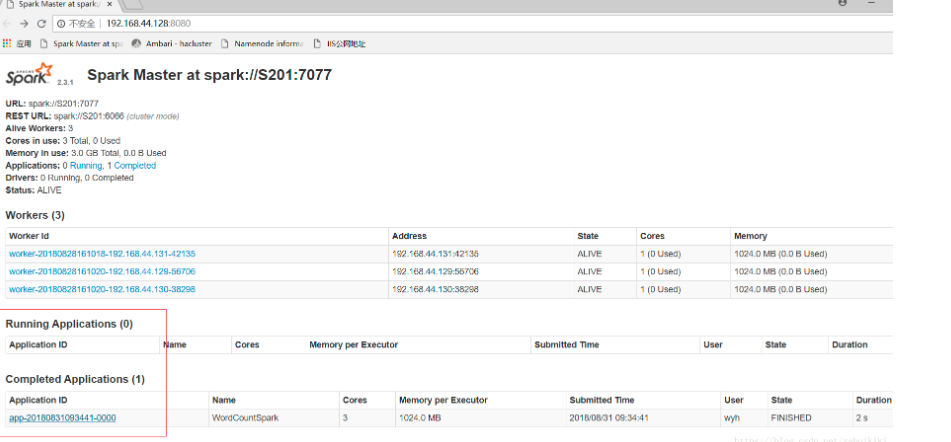
之后将测试代码打包成jar包,上传到服务器,使用spark-submit提交作业。
提交命令:
spark-submit --master spark://s44:7077 --name MyWordCount --class com.demo.spark.scala.WordCountScala SparkDemo-1.0-SNAPSHOT.jar hdfs://s44:8020/usr/hadoop/test.txt把master设置为集群master的url,名字可以随意定义;class参数要带包名,一直指定到要运行的类入口,后面紧跟所在的jar,jar包参数后 跟main需要的自定义参数,如果有多个,空格隔开即可。这里只需要一个参数,用来指定程序要加载的文件目录。
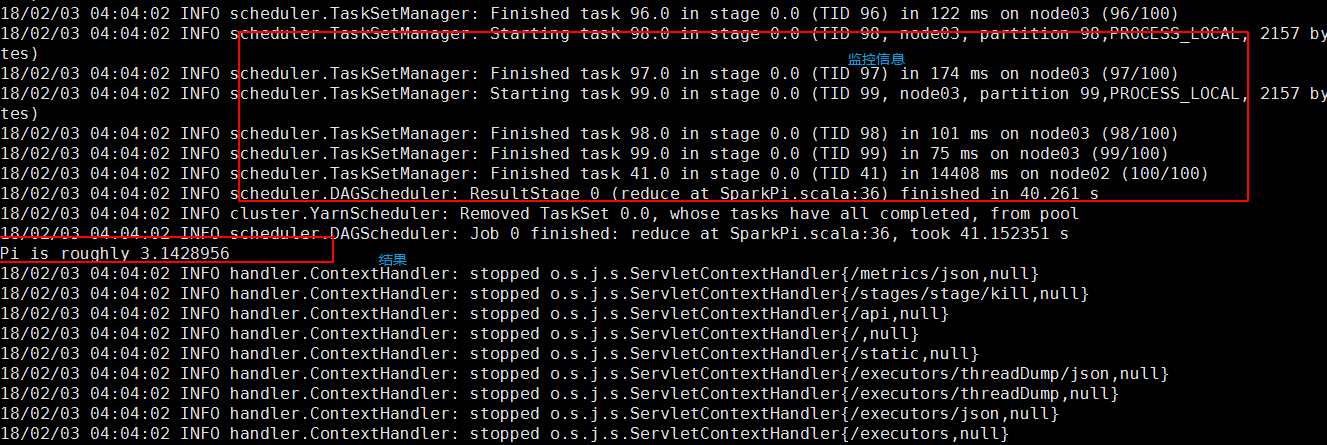
提交后等着打印结果就好,另外可以根据屏幕打印出来的提示查看日志,还可以在webui上查看具体的执行过程。
yarn模式两种提交任务方式
Spark可以和Yarn整合,将Application提交到Yarn上运行,Yarn有两种提交任务的方式。
yarn-client提交任务方式
配置:
在client节点配置中spark-env.sh添加Hadoop_HOME的配置目录即可提交yarn 任务,具体步骤如下:
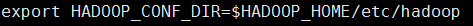
注意client只需要有Spark的安装包即可提交任务,不需要其他配置(比如slaves)
提交命令
./spark-submit --master yarn --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
./spark-submit --master yarn-lient --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
./spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
执行流程图:
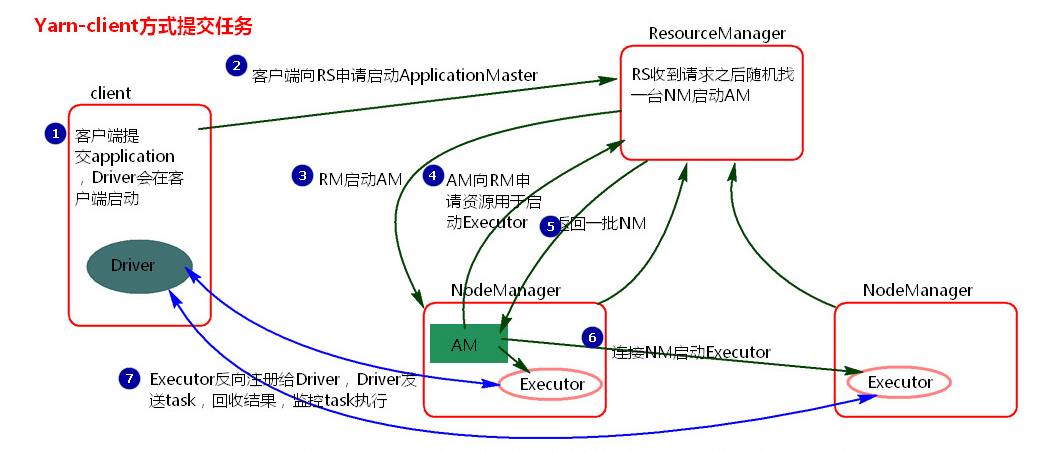
执行流程:
1.客户端提交一个Application,在客户端启动一个Driver进程。
2.Driver进程会向RS(ResourceManager)发送请求,启动AM(ApplicationMaster)。
3.RS收到请求,随机选择一台NM(NodeManager)启动AM。这里的NM相当于Standalone中的Worker节点。
4.AM启动后,会向RS请求一批container资源,用于启动Executor。
5.RS会找到一批NM返回给AM,用于启动Executor。
AM会向NM发送命令启动Executor。
6.Executor启动后,会反向注册给Driver,Driver发送task到Executor,执行情况和结果返回给Driver端。
小结:
1、Yarn-client模式同样是适用于测试,因为Driver运行在本地,Driver会与yarn集群中的Executor进行大量的通信,会造成客户机网卡流量的大量增加.
2、 ApplicationMaster的作用:
为当前的Application申请资源
给NodeManager发送消息启动Executor。
注意:ApplicationMaster有launchExecutor和申请资源的功能,并没有作业调度的功能。
yarn-cluster提交任务方式
提交命令
./spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
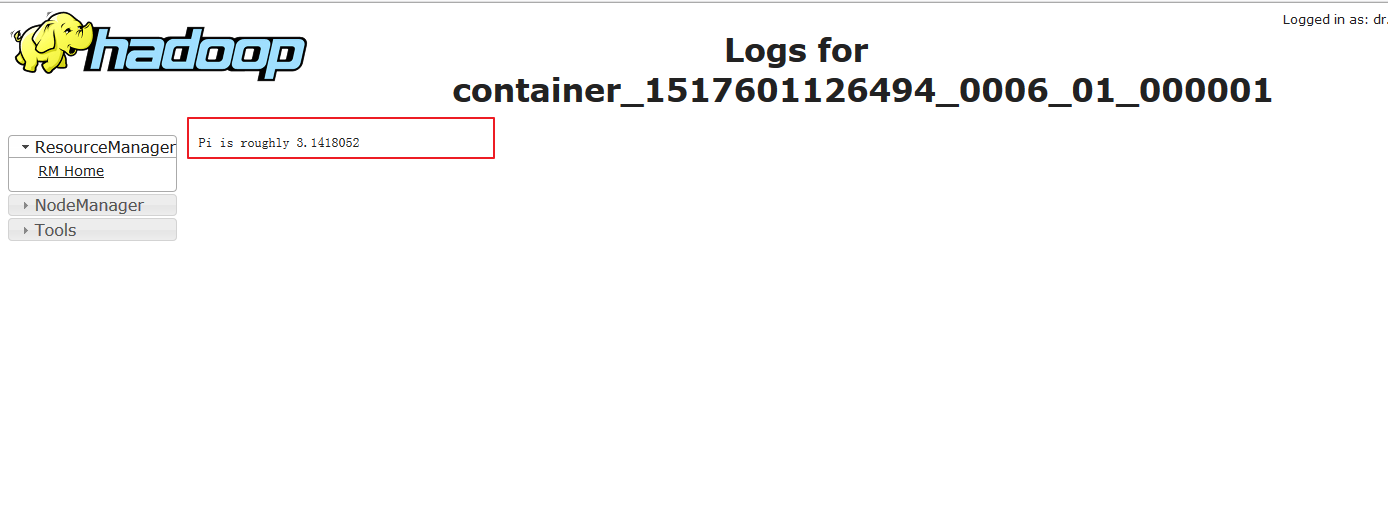
./spark-submit --master yarn-cluster --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100结果在yarn的日志里面:
执行流程图:
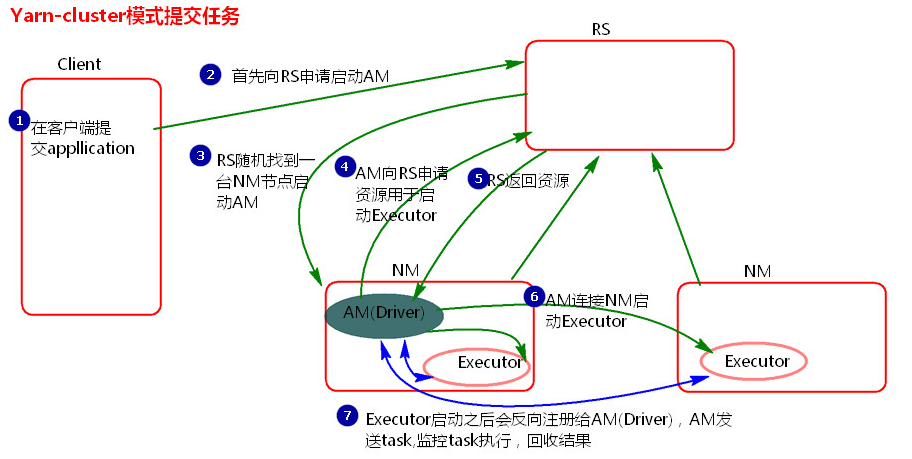
执行流程:
1.客户机提交Application应用程序,发送请求到RS(ResourceManager),请求启动AM(ApplicationMaster)。
2.RS收到请求后随机在一台NM(NodeManager)上启动AM(相当于Driver端)。
3.AM启动,AM发送请求到RS,请求一批container用于启动Executor。
3.RS返回一批NM节点给AM。
4.AM连接到NM,发送请求到NM启动Executor。
5.Executor反向注册到AM所在的节点的Driver。Driver发送task到Executor。
小结
1.Yarn-Cluster主要用于生产环境中,因为Driver运行在Yarn集群中某一台nodeManager中,每次提交任务的Driver所在的机器都是随机的,不会产生某一台机器网卡流量激增的现象,缺点是任务提交后不能看到日志。只能通过yarn查看日志。
2.ApplicationMaster的作用:
为当前的Application申请资源
给nodemanager发送消息 启动Excutor。
任务调度。(这里和client模式的区别是AM具有调度能力,因为其就是Driver端,包含Driver进程)
yarn停止任务命令:
yarn application -kill applicationIDYarn API
hadoop官方文档里面有很多API接口, http://hadoop.apache.org/docs/r2.8.3/hadoop-yarn/hadoop-yarn-site/ResourceManagerRest.html
接下来使用postman来调用yarn api,你也可以使用编程语言来实现http请求。
下面我使用的环境版本:
- Hadoop 2.8.3
- spark-2.4.4-bin-hadoop2.7
首先启动hdfs:
start-hdfs.sh准备一个spark jar包,如果没有可以使用spark样例spark-examples_2.11-2.3.1.jar,并上传到hdfs上
hdfs dfs -put $SPARK_HOME/examples/jars/spark-examples_2.11-2.4.4.jar /
准备需要引入的spark库,打包成zip文件,并上传到hdfs上
cd $SPARK_HOME/jars
打包所有jar
hdfs dfs -put __spark_libs__.zip /
cd $SPARK_HOME/jars
打包配置文件
hdfs dfs -put __spark_conf__.zip /
启动Yarn
start-yarn访问 http://localhost:8088,可以看到yarn 启动正常。

接下来我使用postman 来演示yarn api的调用:
创建spark任务
http://localhost:8088/ws/v1/cluster/apps/new-application

WebHDFS REST API: http://hadoop.apache.org/docs/r2.8.3/hadoop-project-dist/hadoop-hdfs/WebHDFS.html
查看jar包的属性
http://localhost:50070/webhdfs/v1/spark-examples_2.11-2.4.4.jar?op=GETFILESTATUS

查看spark库zip文件属性
http://localhost:50070/webhdfs/v1/__spark_libs__.zip?op=GETFILESTATUS

提交spark任务
每执行一次任务,需要一个app Id,同一个appid 只能提交一次任务
http://localhost:8088/ws/v1/cluster/apps
{
"application-id":"application_1577522109894_0001",
"application-name":"SparkPi",
"am-container-spec":
{
"local-resources":
{
"entry":
[
{
"key":"__app__.jar",
"value":
{
"resource":"hdfs://localhost:9000/spark-examples_2.11-2.4.4.jar",
"type":"FILE",
"visibility":"APPLICATION",
"size": 2017366,
"timestamp": 1577517305828
}
},
{
"key": "__spark_libs__",
"value": {
"resource": "hdfs://localhost:9000/__spark_libs__.zip",
"size": 214677962,
"timestamp": 1577518946899,
"type": "ARCHIVE",
"visibility": "APPLICATION"
}
}
]
},
"commands":
{
"command":"java -server -Xmx1024m -Dspark.yarn.app.container.log.dir=<LOG_DIR> -Dspark.master=yarn -Dspark.submit.deployMode=cluster -Dspark.executor.cores=1 -Dspark.executor.memory=1g -Dspark.app.name=SparkPi org.apache.spark.deploy.yarn.ApplicationMaster --class org.apache.spark.examples.SparkPi --jar __app__.jar 1><LOG_DIR>/stdout 2><LOG_DIR>/stderr"
},
"environment":
{
"entry":
[
{
"key": "SPARK_USER",
"value": "zwnoz"
},
{
"key": "SPARK_YARN_MODE",
"value": true
},
{
"key": "SPARK_YARN_STAGING_DIR",
"value": "hdfs://localhost:9000/user/zwnoz/.sparkStaging/application_1577522109894_0001"
},
{
"key": "CLASSPATH",
"value": "{{PWD}}<CPS>{{PWD}}/__app__.jar<CPS>{{PWD}}/__spark_libs__/*<CPS>$HADOOP_CONF_DIR<CPS>$HADOOP_COMMON_HOME/share/hadoop/common/*<CPS>$HADOOP_COMMON_HOME/share/hadoop/common/lib/*<CPS>$HADOOP_HDFS_HOME/share/hadoop/hdfs/*<CPS>$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*<CPS>$HADOOP_YARN_HOME/share/hadoop/yarn/*<CPS>$HADOOP_YARN_HOME/share/hadoop/yarn/lib/*<CPS>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*<CPS>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*<CPS>{{PWD}}/__spark_conf__/__hadoop_conf__"
},
{
"key": "SPARK_DIST_CLASSPATH",
"value": "{{PWD}}<CPS>{{PWD}}/__app__.jar<CPS>{{PWD}}/__spark_libs__/*<CPS>$HADOOP_CONF_DIR<CPS>$HADOOP_COMMON_HOME/share/hadoop/common/*<CPS>$HADOOP_COMMON_HOME/share/hadoop/common/lib/*<CPS>$HADOOP_HDFS_HOME/share/hadoop/hdfs/*<CPS>$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*<CPS>$HADOOP_YARN_HOME/share/hadoop/yarn/*<CPS>$HADOOP_YARN_HOME/share/hadoop/yarn/lib/*<CPS>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*<CPS>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*<CPS>{{PWD}}/__spark_conf__/__hadoop_conf__"
}
]
}
},
"unmanaged-AM":false,
"max-app-attempts":1,
"resource":
{
"memory":1024,
"vCores":1
},
"application-type":"YARN",
"keep-containers-across-application-attempts":false
}
资源分配
YARN的RM负责管理整个集群,NM则负责管理该工作节点。
YARN的NM可分配core数(即可以分给Container的最大CPU核数)由参数yarn.nodemanager.resource.cpu-vcores指定,一般要小于本节点的物理CPU核数,因为要预留一些资源给其他任务。Hadoop集群工作节点一般都是同构的,即配置相同。NM可分配给Container的最大内存则由参数yarn.nodemanager.resource.memory-mb指定,默认情况下,可分配内存会小于本机内存*0.8。
注意,分配给作业的资源不要超过YARN可分配的集群资源总数。注意:分配给单个Container的核数和内存不能超过阈值,即为Executor设置的核数和内存不能超过阈值。若分配给作业的资源超过上限,将不会启动指定数目的Executor(也就是说,不会起足够数目的Container)。
参数设置
yarn 参数设置
在YARN中,资源管理由ResourceManager和NodeManager共同完成,其中,ResourceManager中的调度器负责资源的分配,而NodeManager则负责资源的供给和隔离,将cpu、内存等包装称container,一个container代表最小计算资源。
ResourceManager将某个NodeManager上资源分配给任务(这就是所谓的“资源调度”)后,NodeManager需按照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础的保证,这就是所谓的资源隔离。
yarn中可以通过yarn-site.xml中设置如下几个参数达到管理内存的目的:
- yarn.nodemanager.resource.memory-mb 默认值:8192M NM总的可用物理内存,以MB为单位。一旦设置,不可动态修改
- yarn.nodemanager.resource.cpu-vcores 默认值:8 可分配的CPU个数
- yarn.scheduler.minimum-allocation-mb 默认值:1024 可申请的最少内存资源,以MB为单位
- yarn.scheduler.maximum-allocation-mb 默认值:8192 可申请的最大内存资源,以MB为单位
- yarn.scheduler.minimum-allocation-vcores 默认值:1 可申请的最小虚拟CPU个数
- yarn.scheduler.maximum-allocation-vcores 默认值:32 可申请的最 大虚拟CPU个数
yarn.nodemanager.resource.memory-mb与yarn.nodemanager.resource.cpu-vcores的值不会根据系统资源自动设置,需要手动设置,如果系统内存小于8G 、cpu小于8个,最好手动设置
spark 参数设置
spark 执行任务是executor,一个executor可以运行多个task。一个Executor对应一个JVM进程。从Spark的角度看,Executor占用的内存分为两部分:ExecutorMemory和MemoryOverhead。
- spark.driver.memory 默认值:1g ; 分配给driver process的jvm堆内存大小,SparkContext将会在这里初始化,命令行中可通过 --driver-memory指定,也可通过配置文件指定一个固定值
- spark.driver.cores 默认值:1 ; 分配给driver process的核心数量,只在cluster模式下
- spark.driver.memoryOverhead 默认值:driverMemory * 0.10, with minimum of 384; 用于driver process的启停jvm内存大小
- spark.executor.cores 默认值:1 ; 分配给executor process的核心数量,命令行中可通过 executor-cores指定
- spark.executor.memory 默认值:1g ; 分配给每个executor的程序的内存大小,命令行中可通过 --executor-memory指定
- spark.executor.memoryOverhead 默认值:executorMemory * 0.10, with minimum of 384; jvm非堆内存的开销,一般占max(executorMemory *10%,384M)大小
Spark On YARN资源分配策略
当在YARN上运行Spark作业,每个Spark executor作为一个YARN容器运行。Spark可以使得多个Tasks在同一个容器里面运行。
- 对于集群中每个节点首先需要找出nodemanager管理的资源大小,总的资源-系统需求资源-hbase、HDFS等需求资源=nodemanager管理资源
- 划分内存资源,有上文中jvm资源需求等于executor.memory(JVM堆资源)+executor.memoryOverhead(JVM非堆需要资源),也就是一个executor需要的内存资源=--executor-memory+max(executorMemory *10%,384M)。同时这个值需要通过yarn申请,必须落在minimum-allocation-mb与maximum-allocation-mb之间
- 划分cpu资源,通过executor.cores指定executor可拥有的cpu个数,也就是task可并行运行的个数,一般小于5
- 计算executor个数。设置num-executors
对于client模式:nodemanager管理资源>=executor个数executor资源(内存+cpu) 对于cluster模式:nodemanager管理资源>=executor个数executor(内存+cpu)+driver资源(内存+cpu)
总结
本篇主要讲解了Spark on yarn 的提交作业方式, Yarn client 与 Yarn cluster的原理,同时以实例讲解了Hadoop Yarn 的Rest api 以及如何调用提交spark的作业,最后讲了下Spark参数设置、Yarn的参数设置以及Spark on Yarn的资源分配策略。