1. hdfs存文件的时候会把文件切割成block,block分布在不同节点上,目前设置replicate=3,每个block会出现在3个节点上。
2. Spark以RDD概念为中心运行,RDD代表抽象数据集。以代码为例:
sc.textFile(“abc.log”)
textFile()函数会创建一个RDD对象,可以认为这个RDD对象代表”abc.log”文件数据,通过操作RDD对象完成对文件数据的操作。
3. RDD包含1个或多个partition分区,每个分区对应文件数据的一部分。在spark读取hdfs的场景下,spark把hdfs的block读到内存就会抽象为spark的partition。所以,RDD对应文件,而partition对应文件的block,partition的个数等于block的个数,这么做的目的是为了并行操作文件数据。
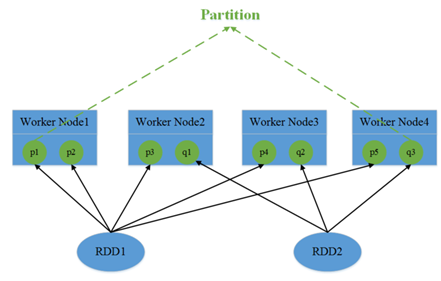
由于block是分布在不同节点上的,所以对partition的操作也是分散在不同节点。
4. RDD是只读的,不可变数据集,所以每次对RDD操作都会产生一个新的RDD对象。同样,partition也是只读的。
sc.textFile("abc.log").map()
代码中textFile()会构建出一个NewHadoopRDD,map()函数运行后会构建出一个MapPartitionsRDD。
这里的map()函数已经是一个分布式操作,因为NewHadoopRDD内的partition是分布在不同节点上的,map()函数会对每一个partition做一次map操作,形成新的partition,一会产生新的RDD(MapPartitionsRDD)。对每个partition执行map操作就是一个task,在图中就会有3个task,task和partition一一对应。

5. 最终每个task会和partition一一对应。但是在分配之前需要考虑task的执行顺序。就出现了job、stage、宽依赖和窄依赖的概念。
宽依赖和窄依赖是为了安排task的执行顺序。简单理解,窄依赖是指操作可以pipeline形式进行,比如map、filter,,不需要依赖所有partition的数据,可以并行地在不同节点计算。map和filter只需要一个分区的数据。
宽依赖,比如groupByKey,需要所有分区的数据才能进行计算,同时会引发节点间的数据传输。
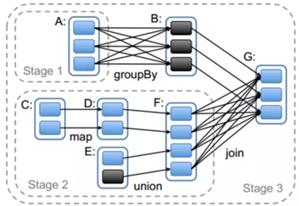
Spark会依据窄依赖和宽依赖划分stage,stage按顺序1,2,3依次执行。
图中stage2里的map和union是窄依赖。
stage3的join是宽依赖。Join操作会把所有partition的数据汇总起来,生产新的partition,这中间可能会发生大量的数据传输。同时会把新生产的RDD写回hdfs,在下次使用时重新读取,划分新的partition。
若干个stage组成一个job,job由真正执行数据的计算部分触发产生,如reduce、collect等操作,所以一个程序可能有多个job。RDD中所有的操作都是Lazy模式进行,运行在编译中不会立即计算最终结果,而是记住所有操作步骤和方法,只有显示的遇到启动命令才执行。
整体看:一个程序有多个job,一个job有多个stage,一个stage有多个task,每个task分配到executor内执行。
6. 分配task时,优先找已经在内存中的数据所在节点;如果没有,再找磁盘上的数据所在节点;都没有,就近节点分配。
7. executor
每个节点根据配置可以起一个或多个executor;每个executor由若干core组成,每个executor的每个core一次只能执行一个task。
task被执行的并行度 = max(executor数目*每个executor的核数,partition数目)。
8. 节点之间使用RPC完成通信(以前是akka,最新的使用netty)。
最后,目前看来,可能会对性能有影响的是有宽依赖的操作,像reduceByKey、sort、sum操作需要所有partition的数据,需要把数据都传输到一个节点上,比较耗时。