初学Spark时,部署的是Standalone模式(集成了HA),写的测试程序一般创建上下文时如下:
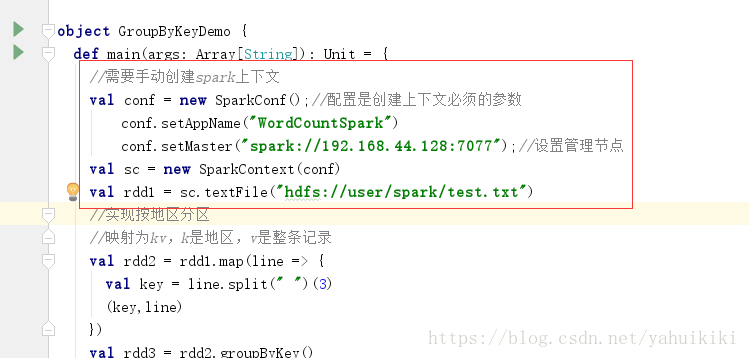
此处master设置为管理节点的集群地址(spark webui上显示的地址) 。

之后将测试代码打包成jar包,上传到服务器,使用spark-submit提交作业。
提交命令:
spark-submit --master spark://s44:7077 --name MyWordCount --class com.yahuidemo.spark.scala.WordCountScala SparkDemo1-1.0-SNAPSHOT.jar hdfs://s44:8020/usr/hadoop/test.txt
打包部署参考 官方api:
http://spark.apache.org/docs/latest/submitting-applications.html
注意,此处我把master设置为我集群master的url,那么可以随意定义;class参数要带包名,一直指定到要运行的类入口,后面紧跟所在的jar(我是直接在jar所在目录下执行的spark-submit,配置过spark环境变量;试过在spark的bin目录下执行,但jar包在别的地方,结果没有成功~)jar包参数后 跟main需要的自定义参数,如果有多个,空格隔开即可。我这里只需要一个参数,用来指定程序要加载的文件目录。
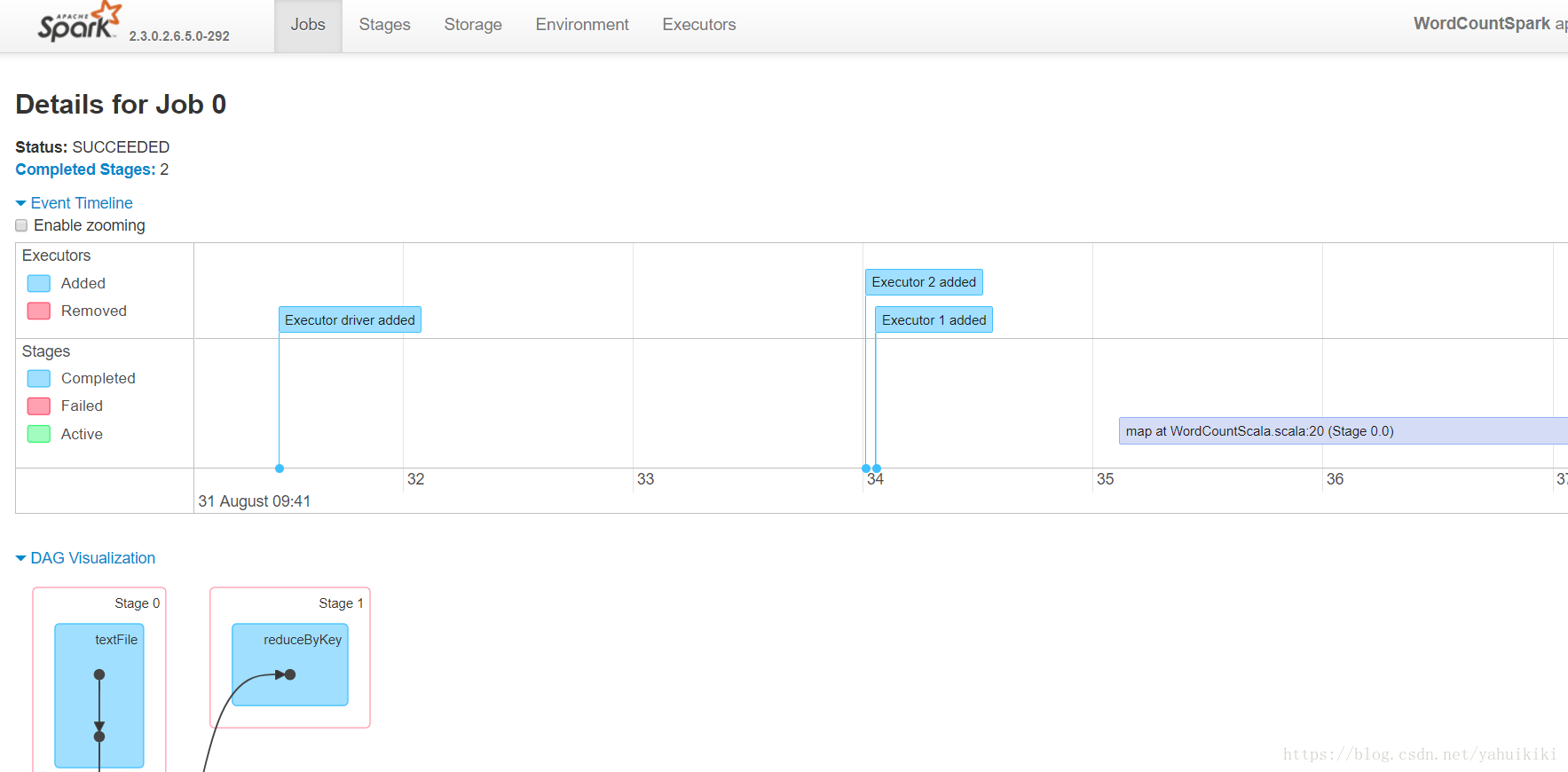
提交后就等着打印结果就好。另外可以根据屏幕打印出来的提示查看日志,还可以在webui上查看具体的执行过程。类似于这样:
点超链接可以看详细的。
前面是测试standalone模式,现在要讲的是yarn模式下提交作业。
由于公司使用ambari来统一搭建管理hadoop、spark等集群。ambari上添加servcie的方式搭建的spark集群是spark-yarn模式。底层原理跟standalone是差不多的,由master来调度worker实现计算,只不过调度交给yarn来管理。
看网上有人这样解释:客户端提交一个Application,在客户端启动一个Driver进程。Driver进程会向RS(ResourceManager)发送请求,启动AM(ApplicationMaster)的资源。RS收到请求,随机选择一台NM(NodeManager)启动AM。这里的NM相当于Standalone中的Worker节点。AM启动后,会向RS请求一批container资源,用于启动Executor.RS会找到一批NM返回给AM,用于启动Executor。AM会向NM发送命令启动Executor。Executor启动后,会反向注册给Driver,Driver发送task到Executor,执行情况和结果返回给Driver端。
官方也给出了spark-yarn的部署文档:
http://spark.apache.org/docs/latest/running-on-yarn.html
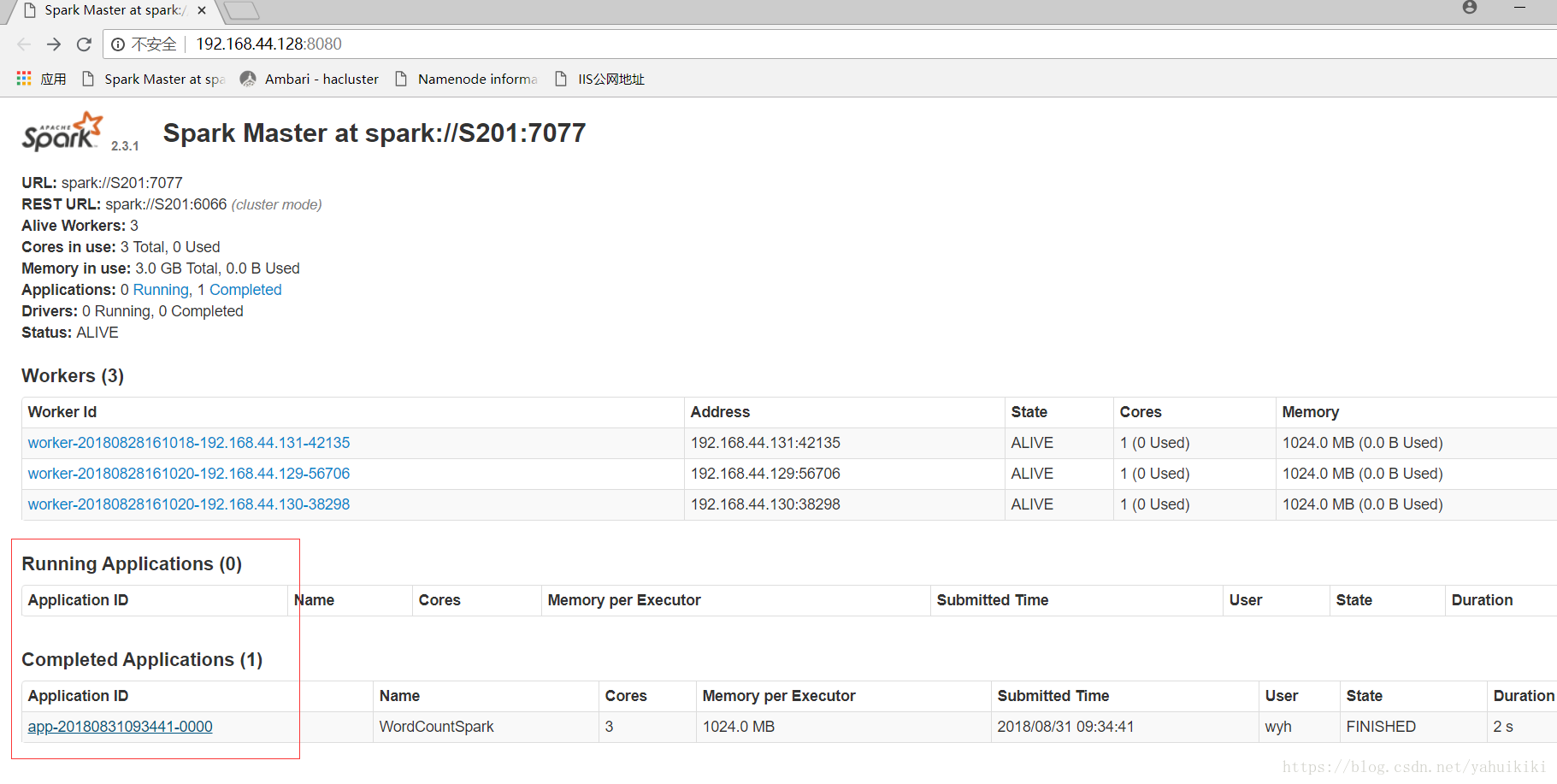
ambari上搭建好集群后,提交了一个example没有问题:
spark-submit --master yarn --class org.apache.spark.examples.SparkPi spark-examples_2.11-2.3.0.2.6.5.0-292.jar
后来自己写了个单词统计的测试类,在使用yarn方式提交。
这里需要将SparkConfig的master配置修改为“yarn”。我为了方便切换模式,将masterurl写成参数传递方式:

依旧将作业打成jar包,上传到服务器,提交作业。提交命令为:
spark-submit --master yarn --class com.yahuidemo.spark.scala.WordCountScala SparkDemo1-1.0-SNAPSHOT.jar yarn /user/spark/test.txt
如图:

注意 需要将master参数修改为yarn,class参数、jar包 和自定义参数跟standalone模式下一样传递。我传了两个参数,一个是指定masterurl 另一个是文件目录。
执行结果
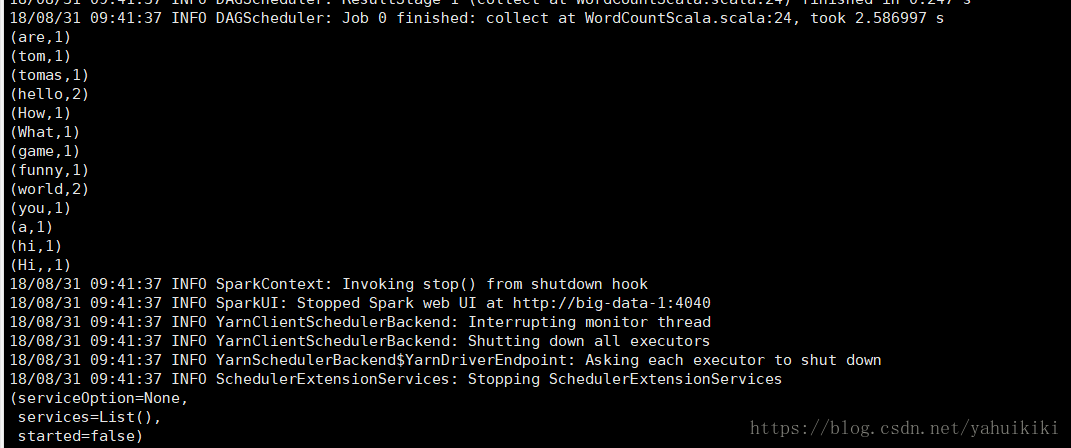
webui 观察