一、概述
对图像应用仿射变换。函数 warpAffine 使用指定的矩阵变换源图像:
![]()
当设置了 WARP_INVERSE_MAP 标志时。 否则,先用 invertAffineTransform 反转变换,然后代入上面的公式,而不是 M。该函数不能就地操作。
二、warpAffine函数
1、函数原型
cv::warpAffine (InputArray src, OutputArray dst, InputArray M, Size dsize, int flags=INTER_LINEAR, int borderMode=BORDER_CONSTANT, const Scalar &borderValue=Scalar())2、参数详解
| src | 输入图像。 |
| dst | 输出大小为 dsize 且类型与 src 相同的图像。 |
| M | 2×3 变换矩阵。 |
| dsize | 输出图像的大小。 |
| flags | 插值方法(见 InterpolationFlags)和可选标志 WARP_INVERSE_MAP 的组合,这意味着 M 是逆变换(dst→src)。 |
| borderMode | 像素外推法(参见 BorderTypes); 当borderMode=BORDER_TRANSPARENT时,表示目标图像中与源图像中的“异常值”对应的像素未被函数修改。 |
| borderValue | 在恒定边界的情况下使用的值; 默认情况下,它是 0。 |
三、OpenCV源码
1、源码路径
opencv\modules\imgproc\src\imgwarp.cpp2、源码代码
void cv::warpAffine( InputArray _src, OutputArray _dst,
InputArray _M0, Size dsize,
int flags, int borderType, const Scalar& borderValue )
{
CV_INSTRUMENT_REGION();
int interpolation = flags & INTER_MAX;
CV_Assert( _src.channels() <= 4 || (interpolation != INTER_LANCZOS4 &&
interpolation != INTER_CUBIC) );
CV_OCL_RUN(_src.dims() <= 2 && _dst.isUMat() &&
_src.cols() <= SHRT_MAX && _src.rows() <= SHRT_MAX,
ocl_warpTransform_cols4(_src, _dst, _M0, dsize, flags, borderType,
borderValue, OCL_OP_AFFINE))
CV_OCL_RUN(_src.dims() <= 2 && _dst.isUMat(),
ocl_warpTransform(_src, _dst, _M0, dsize, flags, borderType,
borderValue, OCL_OP_AFFINE))
Mat src = _src.getMat(), M0 = _M0.getMat();
_dst.create( dsize.empty() ? src.size() : dsize, src.type() );
Mat dst = _dst.getMat();
CV_Assert( src.cols > 0 && src.rows > 0 );
if( dst.data == src.data )
src = src.clone();
double M[6] = {0};
Mat matM(2, 3, CV_64F, M);
if( interpolation == INTER_AREA )
interpolation = INTER_LINEAR;
CV_Assert( (M0.type() == CV_32F || M0.type() == CV_64F) && M0.rows == 2 && M0.cols == 3 );
M0.convertTo(matM, matM.type());
if( !(flags & WARP_INVERSE_MAP) )
{
double D = M[0]*M[4] - M[1]*M[3];
D = D != 0 ? 1./D : 0;
double A11 = M[4]*D, A22=M[0]*D;
M[0] = A11; M[1] *= -D;
M[3] *= -D; M[4] = A22;
double b1 = -M[0]*M[2] - M[1]*M[5];
double b2 = -M[3]*M[2] - M[4]*M[5];
M[2] = b1; M[5] = b2;
}
#if defined (HAVE_IPP) && IPP_VERSION_X100 >= 810 && !IPP_DISABLE_WARPAFFINE
CV_IPP_CHECK()
{
int type = src.type(), depth = CV_MAT_DEPTH(type), cn = CV_MAT_CN(type);
if( ( depth == CV_8U || depth == CV_16U || depth == CV_32F ) &&
( cn == 1 || cn == 3 || cn == 4 ) &&
( interpolation == INTER_NEAREST || interpolation == INTER_LINEAR || interpolation == INTER_CUBIC) &&
( borderType == cv::BORDER_TRANSPARENT || borderType == cv::BORDER_CONSTANT) )
{
ippiWarpAffineBackFunc ippFunc = 0;
if ((flags & WARP_INVERSE_MAP) != 0)
{
ippFunc =
type == CV_8UC1 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_8u_C1R :
type == CV_8UC3 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_8u_C3R :
type == CV_8UC4 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_8u_C4R :
type == CV_16UC1 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_16u_C1R :
type == CV_16UC3 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_16u_C3R :
type == CV_16UC4 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_16u_C4R :
type == CV_32FC1 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_32f_C1R :
type == CV_32FC3 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_32f_C3R :
type == CV_32FC4 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_32f_C4R :
0;
}
else
{
ippFunc =
type == CV_8UC1 ? (ippiWarpAffineBackFunc)ippiWarpAffine_8u_C1R :
type == CV_8UC3 ? (ippiWarpAffineBackFunc)ippiWarpAffine_8u_C3R :
type == CV_8UC4 ? (ippiWarpAffineBackFunc)ippiWarpAffine_8u_C4R :
type == CV_16UC1 ? (ippiWarpAffineBackFunc)ippiWarpAffine_16u_C1R :
type == CV_16UC3 ? (ippiWarpAffineBackFunc)ippiWarpAffine_16u_C3R :
type == CV_16UC4 ? (ippiWarpAffineBackFunc)ippiWarpAffine_16u_C4R :
type == CV_32FC1 ? (ippiWarpAffineBackFunc)ippiWarpAffine_32f_C1R :
type == CV_32FC3 ? (ippiWarpAffineBackFunc)ippiWarpAffine_32f_C3R :
type == CV_32FC4 ? (ippiWarpAffineBackFunc)ippiWarpAffine_32f_C4R :
0;
}
int mode =
interpolation == INTER_LINEAR ? IPPI_INTER_LINEAR :
interpolation == INTER_NEAREST ? IPPI_INTER_NN :
interpolation == INTER_CUBIC ? IPPI_INTER_CUBIC :
0;
CV_Assert(mode && ippFunc);
double coeffs[2][3];
for( int i = 0; i < 2; i++ )
for( int j = 0; j < 3; j++ )
coeffs[i][j] = matM.at<double>(i, j);
bool ok;
Range range(0, dst.rows);
IPPWarpAffineInvoker invoker(src, dst, coeffs, mode, borderType, borderValue, ippFunc, &ok);
parallel_for_(range, invoker, dst.total()/(double)(1<<16));
if( ok )
{
CV_IMPL_ADD(CV_IMPL_IPP|CV_IMPL_MT);
return;
}
setIppErrorStatus();
}
}
#endif
hal::warpAffine(src.type(), src.data, src.step, src.cols, src.rows, dst.data, dst.step, dst.cols, dst.rows,
M, interpolation, borderType, borderValue.val);
}namespace hal {
void warpAffine(int src_type,
const uchar * src_data, size_t src_step, int src_width, int src_height,
uchar * dst_data, size_t dst_step, int dst_width, int dst_height,
const double M[6], int interpolation, int borderType, const double borderValue[4])
{
CALL_HAL(warpAffine, cv_hal_warpAffine, src_type, src_data, src_step, src_width, src_height, dst_data, dst_step, dst_width, dst_height, M, interpolation, borderType, borderValue);
Mat src(Size(src_width, src_height), src_type, const_cast<uchar*>(src_data), src_step);
Mat dst(Size(dst_width, dst_height), src_type, dst_data, dst_step);
int x;
AutoBuffer<int> _abdelta(dst.cols*2);
int* adelta = &_abdelta[0], *bdelta = adelta + dst.cols;
const int AB_BITS = MAX(10, (int)INTER_BITS);
const int AB_SCALE = 1 << AB_BITS;
for( x = 0; x < dst.cols; x++ )
{
adelta[x] = saturate_cast<int>(M[0]*x*AB_SCALE);
bdelta[x] = saturate_cast<int>(M[3]*x*AB_SCALE);
}
Range range(0, dst.rows);
WarpAffineInvoker invoker(src, dst, interpolation, borderType,
Scalar(borderValue[0], borderValue[1], borderValue[2], borderValue[3]),
adelta, bdelta, M);
parallel_for_(range, invoker, dst.total()/(double)(1<<16));
}
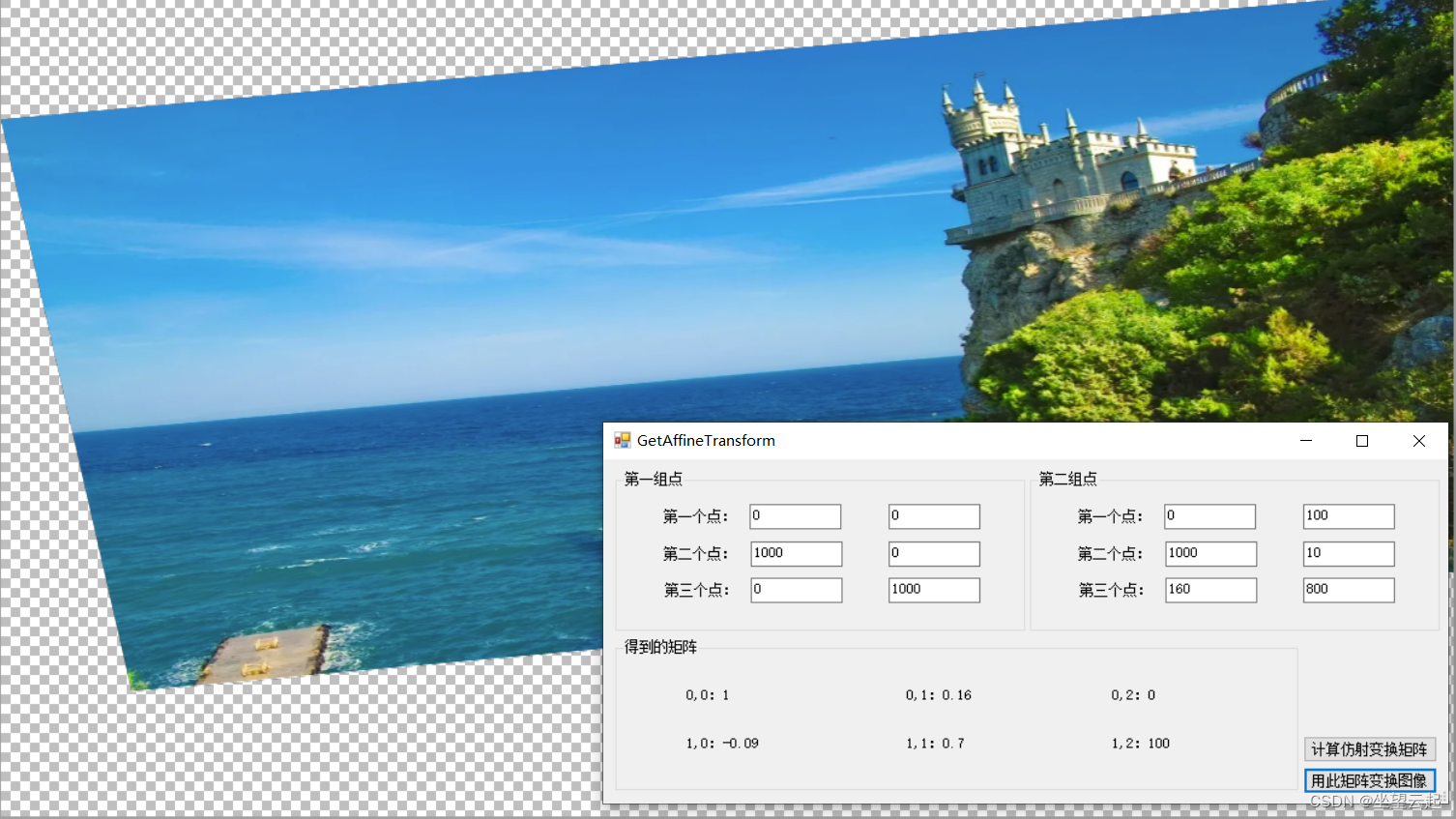
}四、效果图像示例